 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Controlled Differential Equations
Dec 29, 2025We introduce a training-efficient framework for time-series learning that combines random features with controlled differential equations (CDEs). In this approach, large randomly parameterized CDEs act as continuous-time reservoirs, mapping input paths to rich representations. Only a linear readout layer is trained, resulting in fast, scalable models with strong inductive bias. Building on this foundation, we propose two variants: (i) Random Fourier CDEs (RF-CDEs): these lift the input signal using random Fourier features prior to the dynamics, providing a kernel-free approximation of RBF-enhanced sequence models; (ii) Random Rough DEs (R-RDEs): these operate directly on rough-path inputs via a log-ODE discretization, using log-signatures to capture higher-order temporal interactions while remaining stable and efficient. We prove that in the infinite-width limit, these model induces the RBF-lifted signature kernel and the rough signature kernel, respectively, offering a unified perspective on random-feature reservoirs, continuous-time deep architectures, and path-signature theory. We evaluate both models across a range of time-series benchmarks, demonstrating competitive or state-of-the-art performance. These methods provide a practical alternative to explicit signature computations, retaining their inductive bias while benefiting from the efficiency of random features.
Numerical Schemes for Signature Kernels
Feb 12, 2025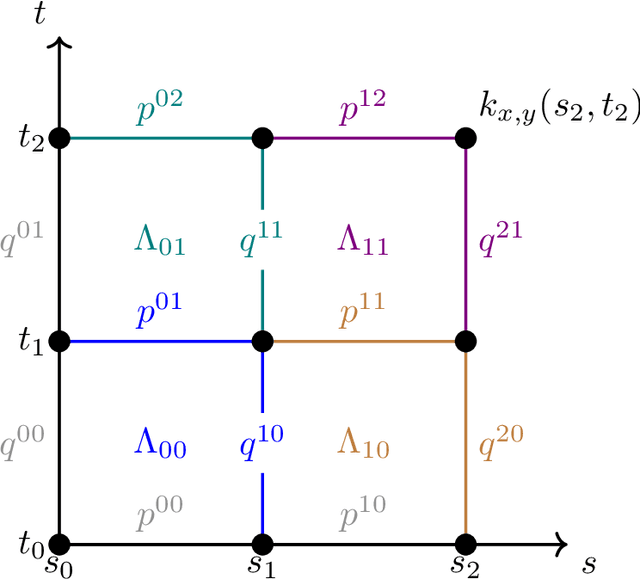
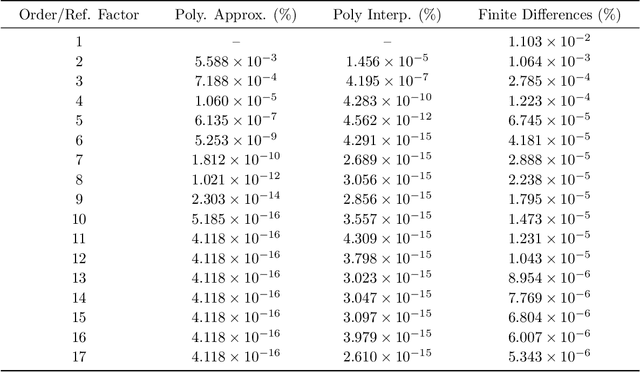
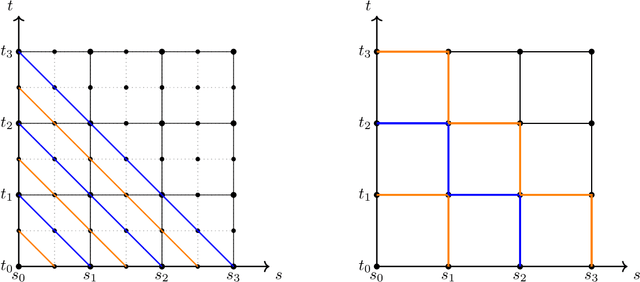
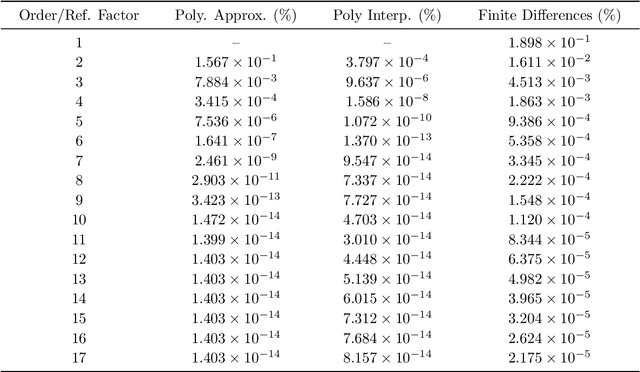
Signature kernels have emerged as a powerful tool within kernel methods for sequential data. In the paper "The Signature Kernel is the solution of a Goursat PDE", the authors identify a kernel trick that demonstrates that, for continuously differentiable paths, the signature kernel satisfies a Goursat problem for a hyperbolic partial differential equation (PDE) in two independent time variables. While finite difference methods have been explored for this PDE, they face limitations in accuracy and stability when handling highly oscillatory inputs. In this work, we introduce two advanced numerical schemes that leverage polynomial representations of boundary conditions through either approximation or interpolation techniques, and rigorously establish the theoretical convergence of the polynomial approximation scheme. Experimental evaluations reveal that our approaches yield improvements of several orders of magnitude in mean absolute percentage error (MAPE) compared to traditional finite difference schemes, without increasing computational complexity. Furthermore, like finite difference methods, our algorithms can be GPU-parallelized to reduce computational complexity from quadratic to linear in the length of the input sequences, thereby improving scalability for high-frequency data. We have implemented these algorithms in a dedicated Python library, which is publicly available at: https://github.com/FrancescoPiatti/polysigkernel.
Partially Stochastic Infinitely Deep Bayesian Neural Networks
Feb 05, 2024



In this paper, we present Partially Stochastic Infinitely Deep Bayesian Neural Networks, a novel family of architectures that integrates partial stochasticity into the framework of infinitely deep neural networks. Our new class of architectures is designed to improve the limitations of existing architectures around computational efficiency at training and inference time. To do this, we leverage the advantages of partial stochasticity in the infinite-depth limit which include the benefits of full stochasticity e.g. robustness, uncertainty quantification, and memory efficiency, whilst improving their limitations around computational efficiency at training and inference time. We present a variety of architectural configurations, offering flexibility in network design including different methods for weight partition. We also provide mathematical guarantees on the expressivity of our models by establishing that our network family qualifies as Universal Conditional Distribution Approximators. Lastly, empirical evaluations across multiple tasks show that our proposed architectures achieve better downstream task performance and uncertainty quantification than their counterparts while being significantly more efficient.