 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogNet: Convolutional Neural Network Inference on Analog Focal Plane Sensor Processors
Jun 21, 2020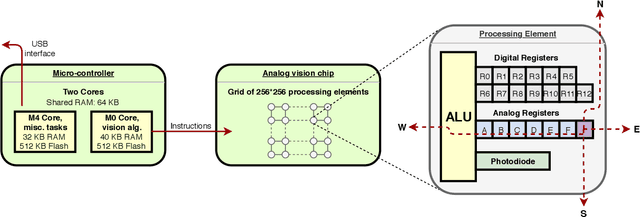
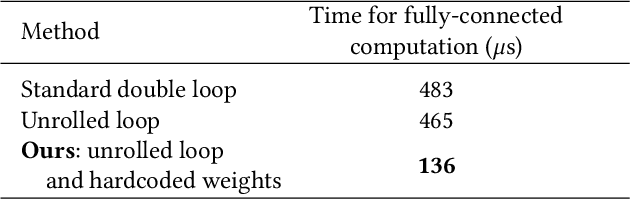


We present a high-speed, energy-efficient Convolutional Neural Network (CNN) architecture utilising the capabilities of a unique class of devices known as analog Focal Plane Sensor Processors (FPSP), in which the sensor and the processor are embedded together on the same silicon chip. Unlike traditional vision systems, where the sensor array sends collected data to a separate processor for processing, FPSPs allow data to be processed on the imaging device itself. This unique architecture enables ultra-fast image processing and high energy efficiency, at the expense of limited processing resources and approximate computations. In this work, we show how to convert standard CNNs to FPSP code, and demonstrate a method of training networks to increase their robustness to analog computation errors. Our proposed architecture, coined AnalogNet, reaches a testing accuracy of 96.9% on the MNIST handwritten digits recognition task, at a speed of 2260 FPS, for a cost of 0.7 mJ per frame.
Synthetic dataset generation for object-to-model deep learning in industrial applications
Sep 24, 2019
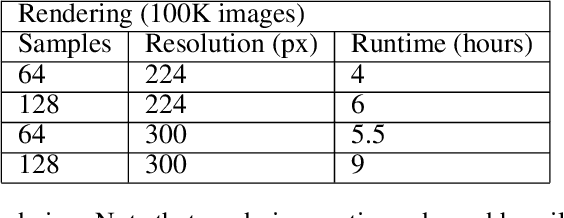
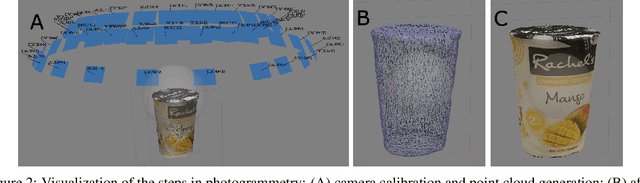

The availability of large image data sets has been a crucial factor in the success of deep learning-based classification and detection methods. While data sets for everyday objects are widely available, data for specific industrial use-cases (e.g. identifying packaged products in a warehouse) remains scarce. In such cases, the data sets have to be created from scratch, placing a crucial bottleneck on the deployment of deep learning techniques in industrial applications. We present work carried out in collaboration with a leading UK online supermarket, with the aim of creating a computer vision system capable of detecting and identifying unique supermarket products in a warehouse setting. To this end, we demonstrate a framework for using synthetic data to create an end-to-end deep learning pipeline, beginning with real-world objects and culminating in a trained model. Our method is based on the generation of a synthetic dataset from 3D models obtained by applying photogrammetry techniques to real-world objects. Using 100k synthetic images generated from 60 real images per class, an InceptionV3 convolutional neural network (CNN) was trained, which achieved classification accuracy of 95.8% on a separately acquired test set of real supermarket product images. The image generation process supports automatic pixel annotation. This eliminates the prohibitively expensive manual annotation typically required for detection tasks. Based on this readily available data, a one-stage RetinaNet detector was trained on the synthetic, annotated images to produce a detector that can accurately localize and classify the specimen products in real-time.