 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Majorization-Minimization Algorithms
Jul 31, 2023Majorization-minimization (MM) is a family of optimization methods that iteratively reduce a loss by minimizing a locally-tight upper bound, called a majorizer. Traditionally, majorizers were derived by hand, and MM was only applicable to a small number of well-studied problems. We present optimizers that instead derive majorizers automatically, using a recent generalization of Taylor mode automatic differentiation. These universal MM optimizers can be applied to arbitrary problems and converge from any starting point, with no hyperparameter tuning.
Automatically Bounding the Taylor Remainder Series: Tighter Bounds and New Applications
Dec 22, 2022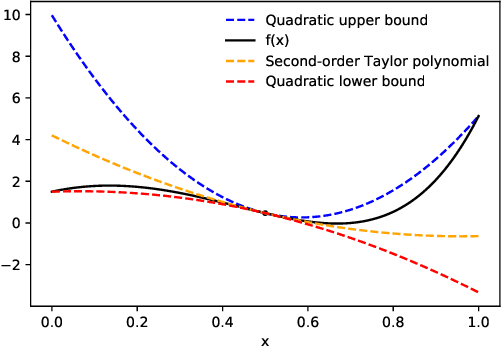
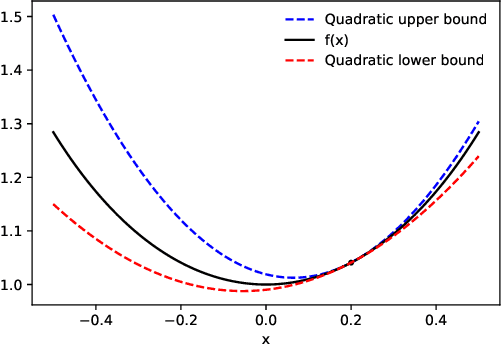

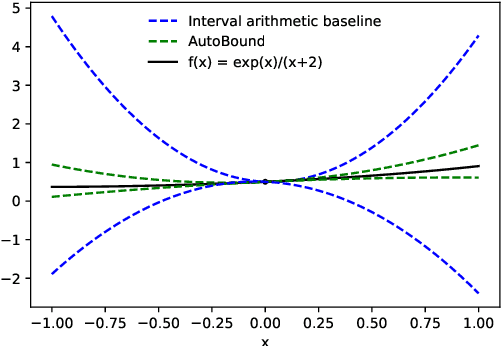
We present a new algorithm for automatically bounding the Taylor remainder series. In the special case of a scalar function $f: \mathbb{R} \mapsto \mathbb{R}$, our algorithm takes as input a reference point $x_0$, trust region $[a, b]$, and integer $k \ge 0$, and returns an interval $I$ such that $f(x) - \sum_{i=0}^k \frac {f^{(i)}(x_0)} {i!} (x - x_0)^i \in I (x - x_0)^{k+1}$ for all $x \in [a, b]$. As in automatic differentiation, the function $f$ is provided to the algorithm in symbolic form, and must be composed of known elementary functions. At a high level, our algorithm has two steps. First, for a variety of commonly-used elementary functions (e.g., $\exp$, $\log$), we derive sharp polynomial upper and lower bounds on the Taylor remainder series. We then recursively combine the bounds for the elementary functions using an interval arithmetic variant of Taylor-mode automatic differentiation. Our algorithm can make efficient use of machine learning hardware accelerators, and we provide an open source implementation in JAX. We then turn our attention to applications. Most notably, we use our new machinery to create the first universal majorization-minimization optimization algorithms: algorithms that iteratively minimize an arbitrary loss using a majorizer that is derived automatically, rather than by hand. Applied to machine learning, this leads to architecture-specific optimizers for training deep networks that converge from any starting point, without hyperparameter tuning. Our experiments show that for some optimization problems, these hyperparameter-free optimizers outperform tuned versions of gradient descent, Adam, and AdaGrad. We also show that our automatically-derived bounds can be used for verified global optimization and numerical integration, and to prove sharper versions of Jensen's inequality.
Data-driven Science and Machine Learning Methods in Laser-Plasma Physics
Nov 30, 2022Laser-plasma physics has developed rapidly over the past few decades as lasers have become both more powerful and more widely available. Early experimental and numerical research in this field was dominated by single-shot experiments with limited parameter exploration. However, recent technological improvements make it possible to gather data for hundreds or thousands of different settings in both experiments and simulations. This has sparked interest in using advanced techniques from mathematics, statistics and computer science to deal with, and benefit from, big data. At the same time, sophisticated modeling techniques also provide new ways for researchers to deal effectively with situation where still only sparse data are available. This paper aims to present an overview of relevant machine learning methods with focus on applicability to laser-plasma physics and its important sub-fields of laser-plasma acceleration and inertial confinement fusion.
Learning Effective Loss Functions Efficiently
Jun 28, 2019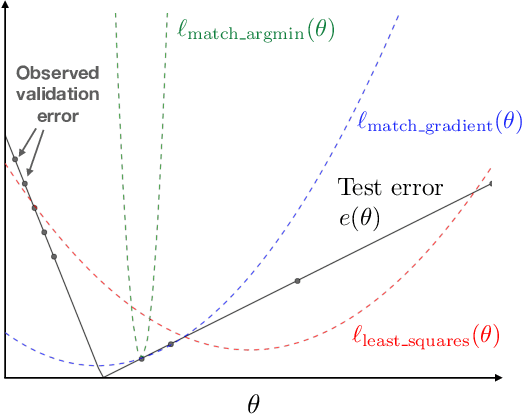

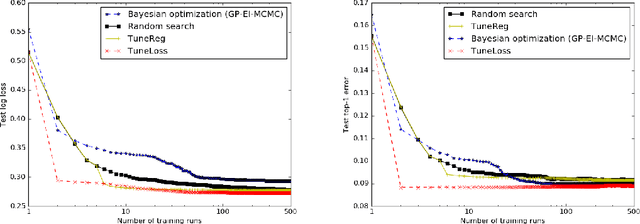
We consider the problem of learning a loss function which, when minimized over a training dataset, yields a model that approximately minimizes a validation error metric. Though learning an optimal loss function is NP-hard, we present an anytime algorithm that is asymptotically optimal in the worst case, and is provably efficient in an idealized "easy" case. Experimentally, we show that this algorithm can be used to tune loss function hyperparameters orders of magnitude faster than state-of-the-art alternatives. We also show that our algorithm can be used to learn novel and effective loss functions on-the-fly during training.
Learning Optimal Linear Regularizers
Feb 21, 2019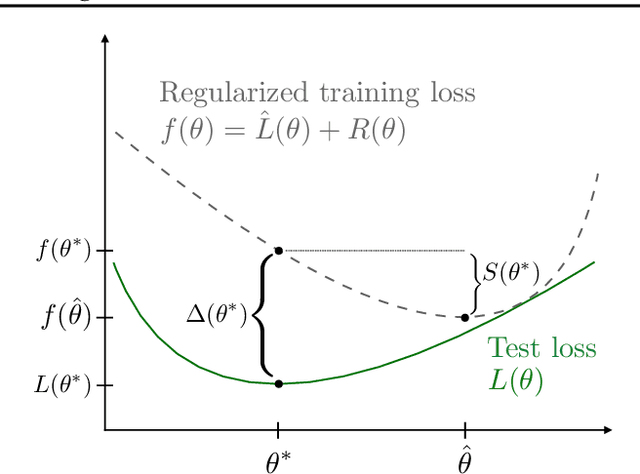
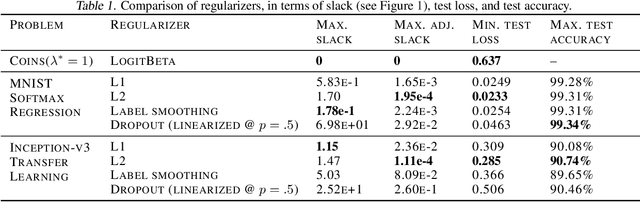
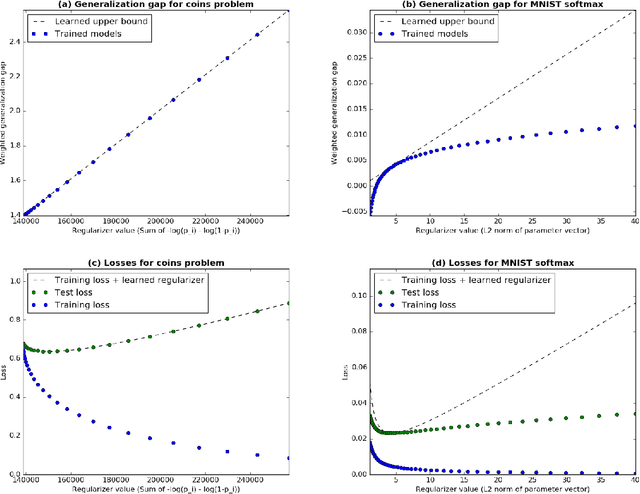
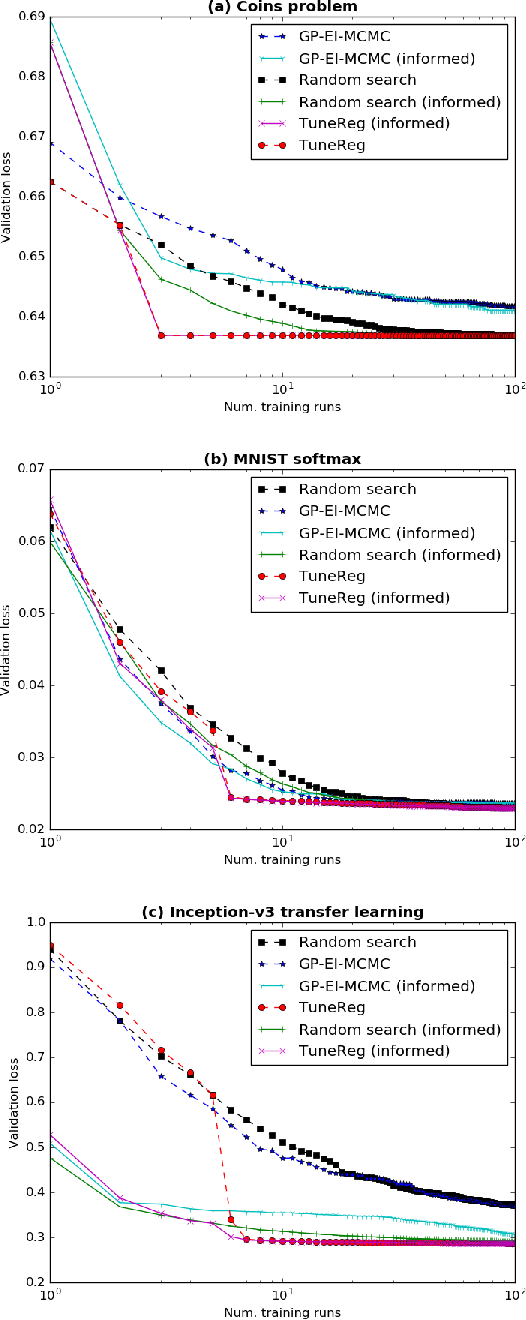
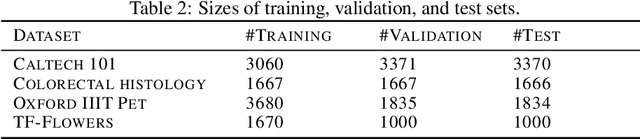
We present algorithms for efficiently learning regularizers that improve generalization. Our approach is based on the insight that regularizers can be viewed as upper bounds on the generalization gap, and that reducing the slack in the bound can improve performance on test data. For a broad class of regularizers, the hyperparameters that give the best upper bound can be computed using linear programming. Under certain Bayesian assumptions, solving the LP lets us "jump" to the optimal hyperparameters given very limited data. This suggests a natural algorithm for tuning regularization hyperparameters, which we show to be effective on both real and synthetic data.
Bayes Optimal Early Stopping Policies for Black-Box Optimization
Feb 21, 2019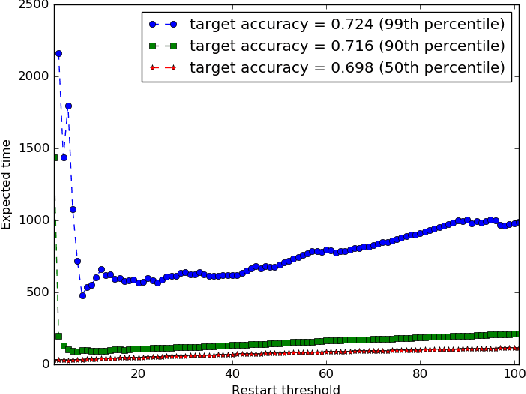

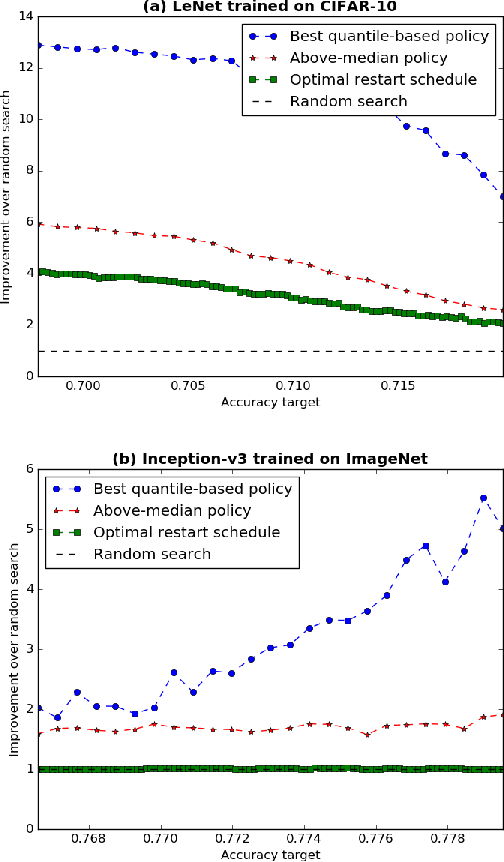
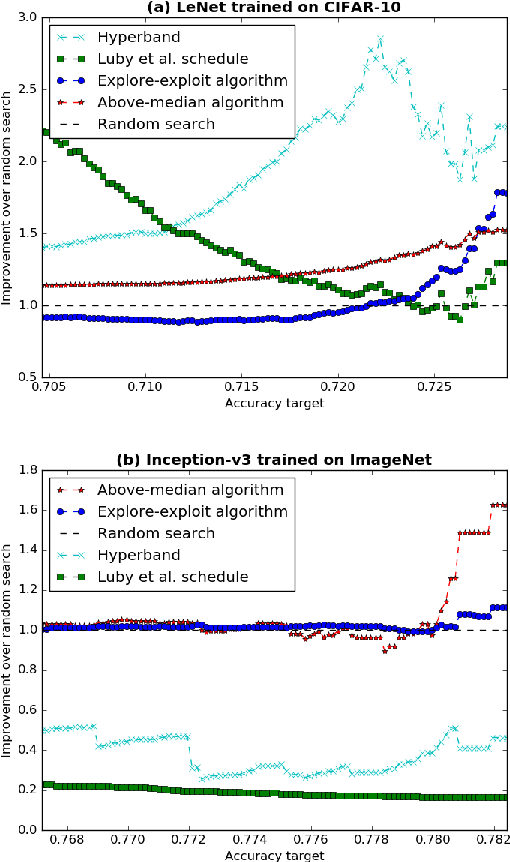
We derive an optimal policy for adaptively restarting a randomized algorithm, based on observed features of the run-so-far, so as to minimize the expected time required for the algorithm to successfully terminate. Given a suitable Bayesian prior, this result can be used to select the optimal black-box optimization algorithm from among a large family of algorithms that includes random search, Successive Halving, and Hyperband. On CIFAR-10 and ImageNet hyperparameter tuning problems, the proposed policies offer up to a factor of 13 improvement over random search in terms of expected time to reach a given target accuracy, and up to a factor of 3 improvement over a baseline adaptive policy that terminates a run whenever its accuracy is below-median.
Approximation Algorithms for Cascading Prediction Models
Feb 21, 2018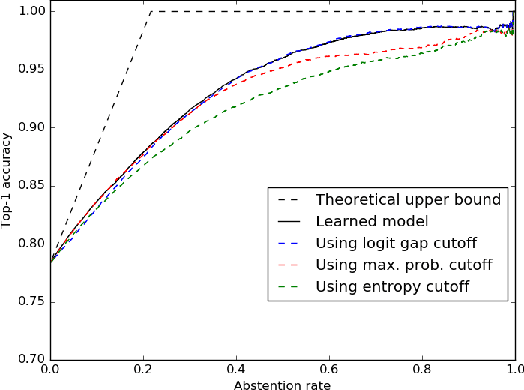
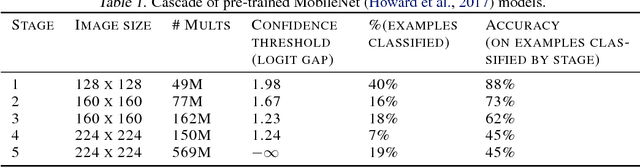
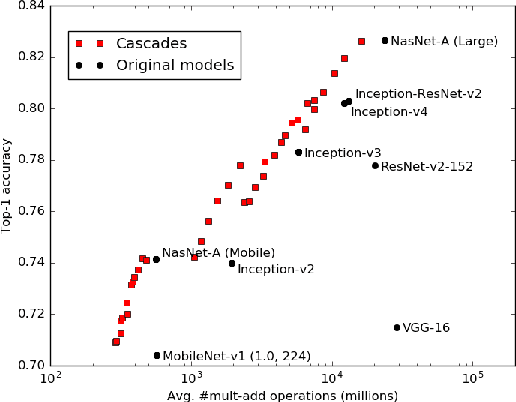
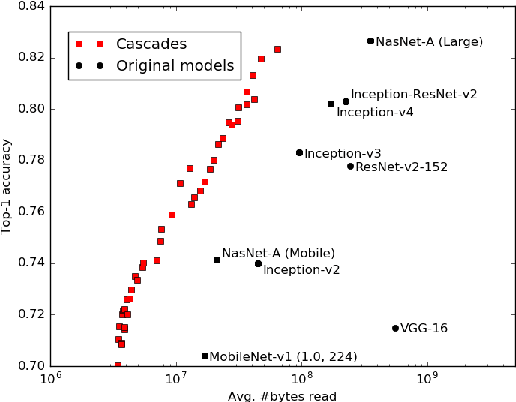
We present an approximation algorithm that takes a pool of pre-trained models as input and produces from it a cascaded model with similar accuracy but lower average-case cost. Applied to state-of-the-art ImageNet classification models, this yields up to a 2x reduction in floating point multiplications, and up to a 6x reduction in average-case memory I/O. The auto-generated cascades exhibit intuitive properties, such as using lower-resolution input for easier images and requiring higher prediction confidence when using a computationally cheaper model.
Online Submodular Maximization under a Matroid Constraint with Application to Learning Assignments
Jul 03, 2014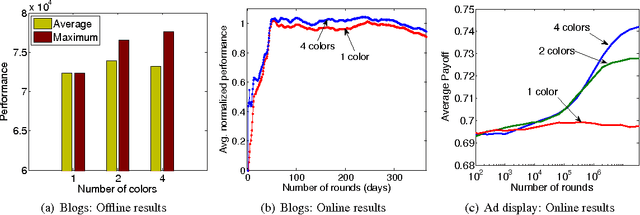
Which ads should we display in sponsored search in order to maximize our revenue? How should we dynamically rank information sources to maximize the value of the ranking? These applications exhibit strong diminishing returns: Redundancy decreases the marginal utility of each ad or information source. We show that these and other problems can be formalized as repeatedly selecting an assignment of items to positions to maximize a sequence of monotone submodular functions that arrive one by one. We present an efficient algorithm for this general problem and analyze it in the no-regret model. Our algorithm possesses strong theoretical guarantees, such as a performance ratio that converges to the optimal constant of 1 - 1/e. We empirically evaluate our algorithm on two real-world online optimization problems on the web: ad allocation with submodular utilities, and dynamically ranking blogs to detect information cascades. Finally, we present a second algorithm that handles the more general case in which the feasible sets are given by a matroid constraint, while still maintaining a 1 - 1/e asymptotic performance ratio.
No-Regret Algorithms for Unconstrained Online Convex Optimization
Nov 09, 2012
Some of the most compelling applications of online convex optimization, including online prediction and classification, are unconstrained: the natural feasible set is R^n. Existing algorithms fail to achieve sub-linear regret in this setting unless constraints on the comparator point x^* are known in advance. We present algorithms that, without such prior knowledge, offer near-optimal regret bounds with respect to any choice of x^*. In particular, regret with respect to x^* = 0 is constant. We then prove lower bounds showing that our guarantees are near-optimal in this setting.
* To appear
New Techniques for Algorithm Portfolio Design
Jun 13, 2012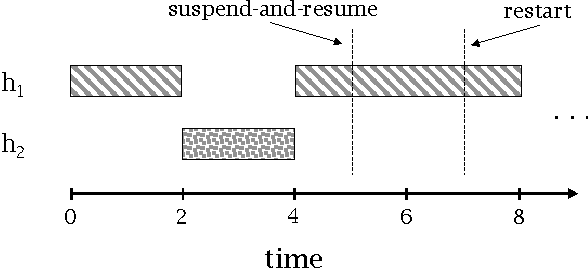

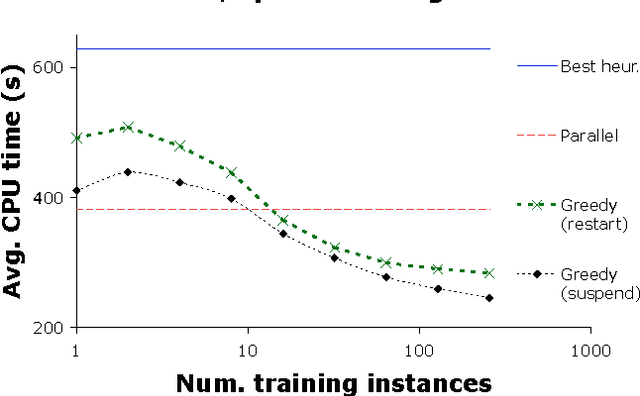
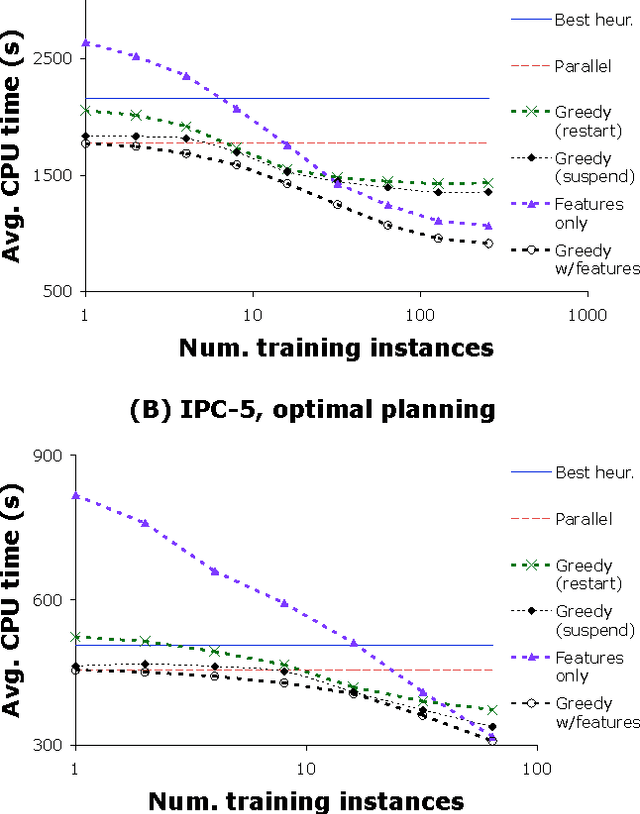
We present and evaluate new techniques for designing algorithm portfolios. In our view, the problem has both a scheduling aspect and a machine learning aspect. Prior work has largely addressed one of the two aspects in isolation. Building on recent work on the scheduling aspect of the problem, we present a technique that addresses both aspects simultaneously and has attractive theoretical guarantees. Experimentally, we show that this technique can be used to improve the performance of state-of-the-art algorithms for Boolean satisfiability, zero-one integer programming, and A.I. planning.