 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantic and Motion-Aware Spatiotemporal Transformer Network for Action Detection
May 13, 2024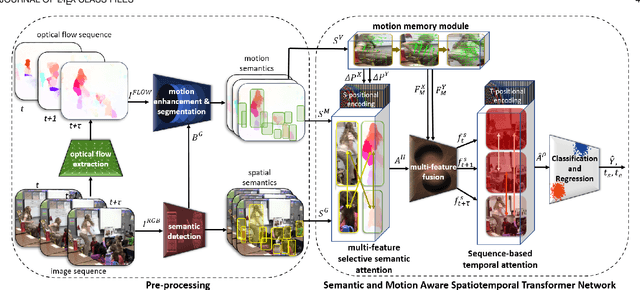
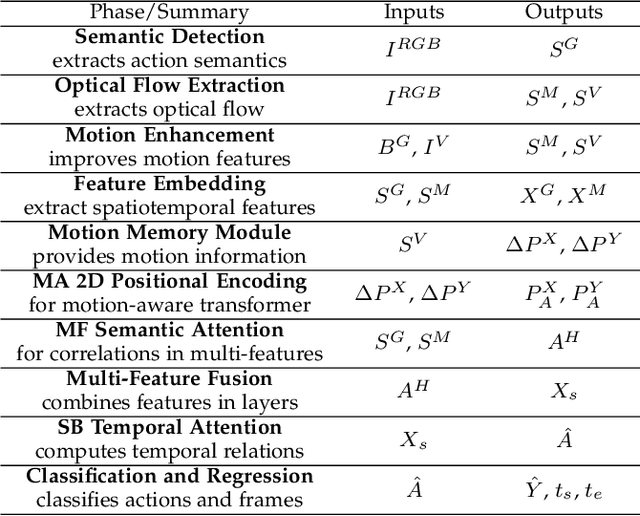
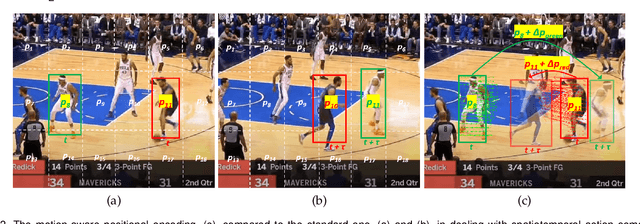
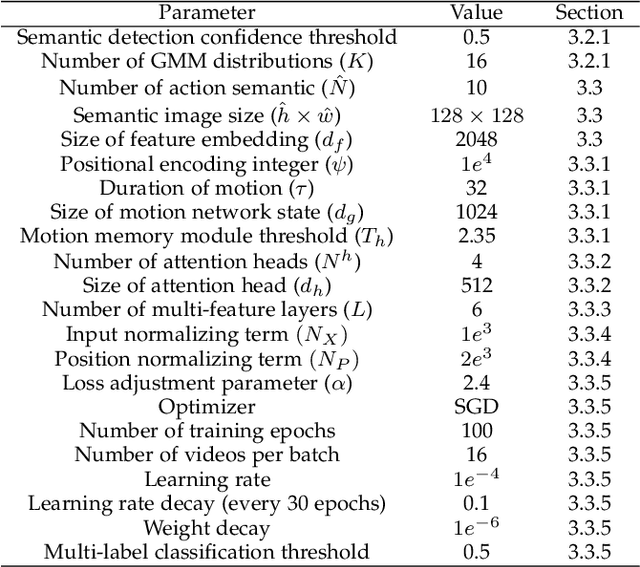
This paper presents a novel spatiotemporal transformer network that introduces several original components to detect actions in untrimmed videos. First, the multi-feature selective semantic attention model calculates the correlations between spatial and motion features to model spatiotemporal interactions between different action semantics properly. Second, the motion-aware network encodes the locations of action semantics in video frames utilizing the motion-aware 2D positional encoding algorithm. Such a motion-aware mechanism memorizes the dynamic spatiotemporal variations in action frames that current methods cannot exploit. Third, the sequence-based temporal attention model captures the heterogeneous temporal dependencies in action frames. In contrast to standard temporal attention used in natural language processing, primarily aimed at finding similarities between linguistic words, the proposed sequence-based temporal attention is designed to determine both the differences and similarities between video frames that jointly define the meaning of actions. The proposed approach outperforms the state-of-the-art solutions on four spatiotemporal action datasets: AVA 2.2, AVA 2.1, UCF101-24, and EPIC-Kitchens.
A Multi-Modal Transformer Network for Action Detection
May 31, 2023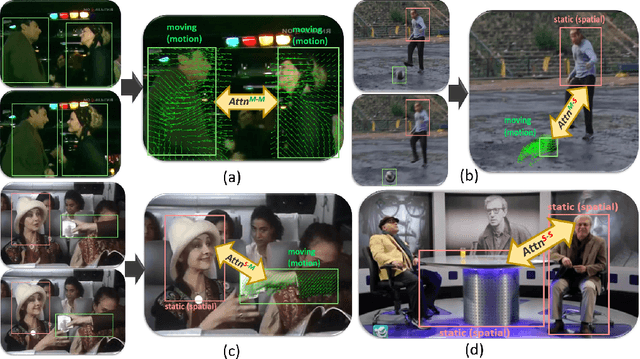
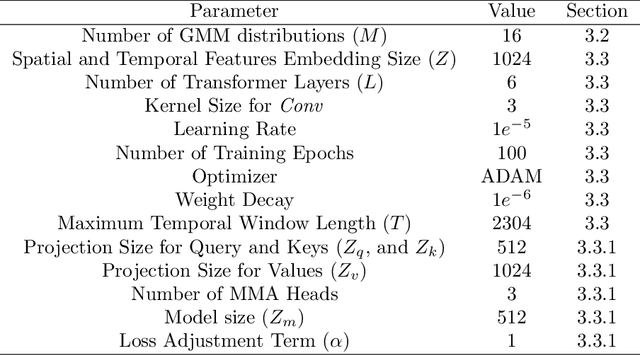

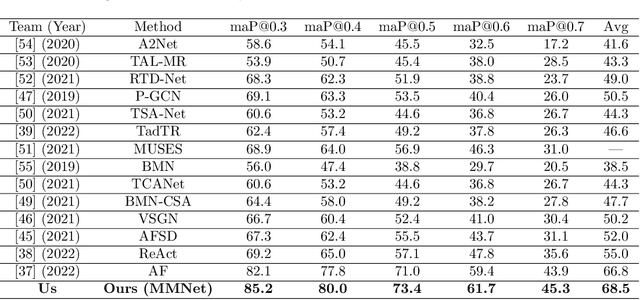
This paper proposes a novel multi-modal transformer network for detecting actions in untrimmed videos. To enrich the action features, our transformer network utilizes a new multi-modal attention mechanism that computes the correlations between different spatial and motion modalities combinations. Exploring such correlations for actions has not been attempted previously. To use the motion and spatial modality more effectively, we suggest an algorithm that corrects the motion distortion caused by camera movement. Such motion distortion, common in untrimmed videos, severely reduces the expressive power of motion features such as optical flow fields. Our proposed algorithm outperforms the state-of-the-art methods on two public benchmarks, THUMOS14 and ActivityNet. We also conducted comparative experiments on our new instructional activity dataset, including a large set of challenging classroom videos captured from elementary schools.
TAA-GCN: A Temporally Aware Adaptive Graph Convolutional Network for Age Estimation
May 15, 2023



This paper proposes a novel age estimation algorithm, the Temporally-Aware Adaptive Graph Convolutional Network (TAA-GCN). Using a new representation based on graphs, the TAA-GCN utilizes skeletal, posture, clothing, and facial information to enrich the feature set associated with various ages. Such a novel graph representation has several advantages: First, reduced sensitivity to facial expression and other appearance variances; Second, robustness to partial occlusion and non-frontal-planar viewpoint, which is commonplace in real-world applications such as video surveillance. The TAA-GCN employs two novel components, (1) the Temporal Memory Module (TMM) to compute temporal dependencies in age; (2) Adaptive Graph Convolutional Layer (AGCL) to refine the graphs and accommodate the variance in appearance. The TAA-GCN outperforms the state-of-the-art methods on four public benchmarks, UTKFace, MORPHII, CACD, and FG-NET. Moreover, the TAA-GCN showed reliability in different camera viewpoints and reduced quality images.
A Survey on Applications of Digital Human Avatars toward Virtual Co-presence
Jan 11, 2022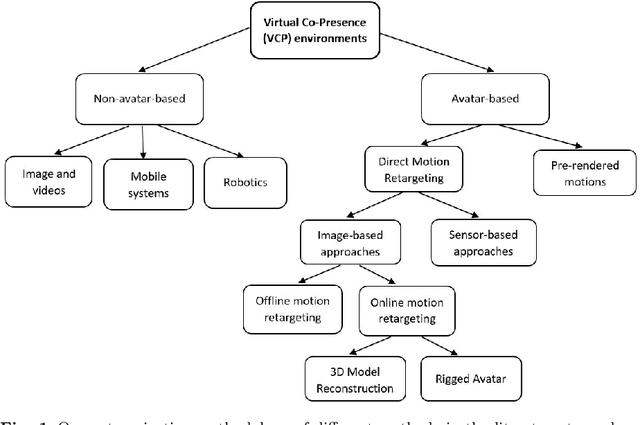
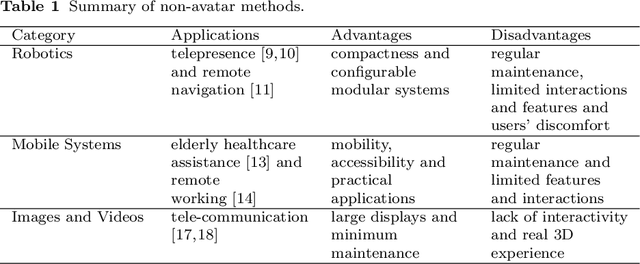

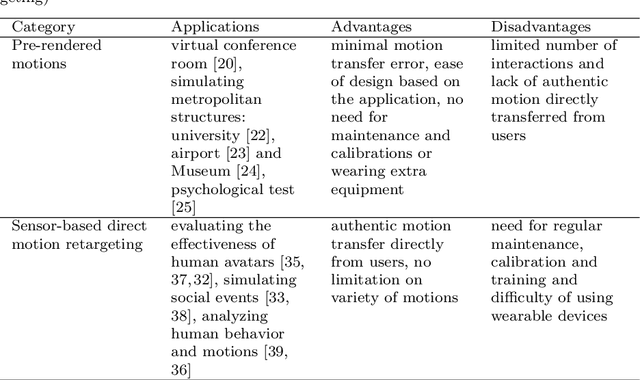
This paper investigates different approaches to build and use digital human avatars toward interactive Virtual Co-presence (VCP) environments. We evaluate the evolution of technologies for creating VCP environments and how the advancement in Artificial Intelligence (AI) and Computer Graphics affect the quality of VCP environments. We categorize different methods in the literature based on their applications and methodology and compare various groups and strategies based on their applications, contributions, and limitations. We also have a brief discussion about the approaches that other forms of human representation, rather than digital human avatars, have been utilized in VCP environments. Our goal is to fill the gap in the research domain where there is a lack of literature review investigating different approaches for creating avatar-based VCP environments. We hope this study will be useful for future research involving human representation in VCP or Virtual Reality (VR) environments. To the best of our knowledge, it is the first survey research that investigates avatar-based VCP environments. Specifically, the categorization methodology suggested in this paper for avatar-based methods is new.