 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantic and Motion-Aware Spatiotemporal Transformer Network for Action Detection
Paper and Code
May 13, 2024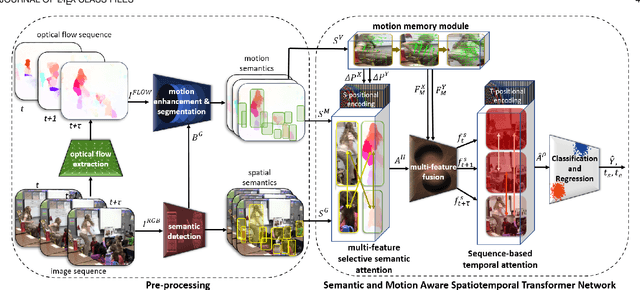
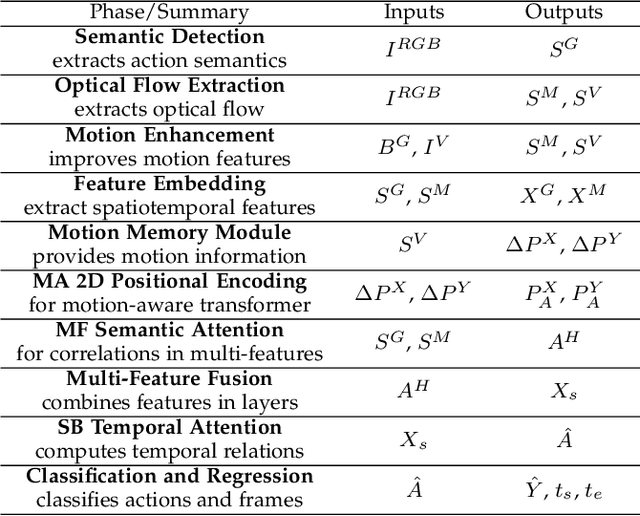
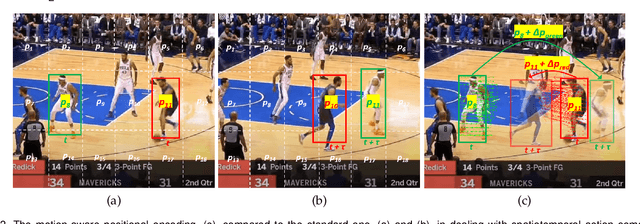
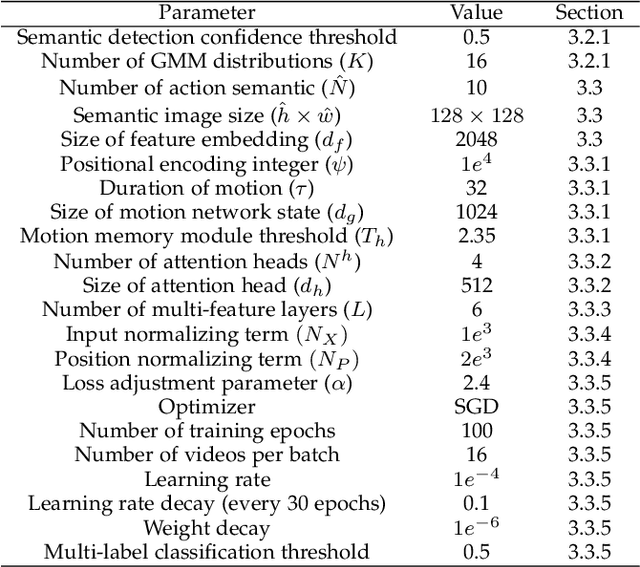
This paper presents a novel spatiotemporal transformer network that introduces several original components to detect actions in untrimmed videos. First, the multi-feature selective semantic attention model calculates the correlations between spatial and motion features to model spatiotemporal interactions between different action semantics properly. Second, the motion-aware network encodes the locations of action semantics in video frames utilizing the motion-aware 2D positional encoding algorithm. Such a motion-aware mechanism memorizes the dynamic spatiotemporal variations in action frames that current methods cannot exploit. Third, the sequence-based temporal attention model captures the heterogeneous temporal dependencies in action frames. In contrast to standard temporal attention used in natural language processing, primarily aimed at finding similarities between linguistic words, the proposed sequence-based temporal attention is designed to determine both the differences and similarities between video frames that jointly define the meaning of actions. The proposed approach outperforms the state-of-the-art solutions on four spatiotemporal action datasets: AVA 2.2, AVA 2.1, UCF101-24, and EPIC-Kitchens.