 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Transformer Network for Action Detection
Paper and Code
May 31, 2023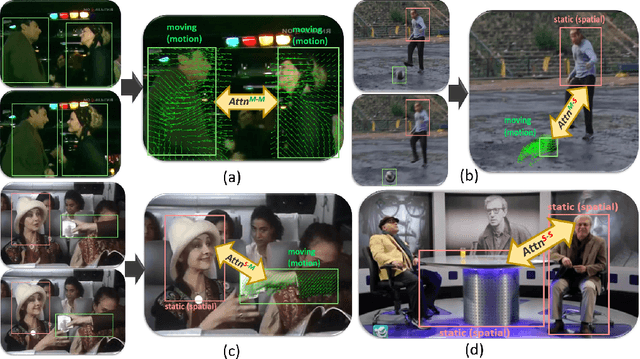
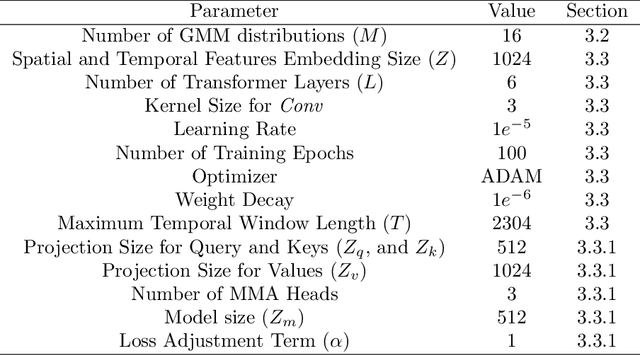

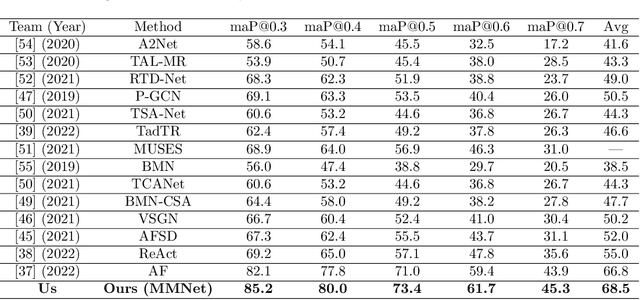
This paper proposes a novel multi-modal transformer network for detecting actions in untrimmed videos. To enrich the action features, our transformer network utilizes a new multi-modal attention mechanism that computes the correlations between different spatial and motion modalities combinations. Exploring such correlations for actions has not been attempted previously. To use the motion and spatial modality more effectively, we suggest an algorithm that corrects the motion distortion caused by camera movement. Such motion distortion, common in untrimmed videos, severely reduces the expressive power of motion features such as optical flow fields. Our proposed algorithm outperforms the state-of-the-art methods on two public benchmarks, THUMOS14 and ActivityNet. We also conducted comparative experiments on our new instructional activity dataset, including a large set of challenging classroom videos captured from elementary schools.