 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Utilisation of Multiple Open-Source Datasets to Improve Generalisation Performance of Point Cloud Segmentation Models
Nov 29, 2022

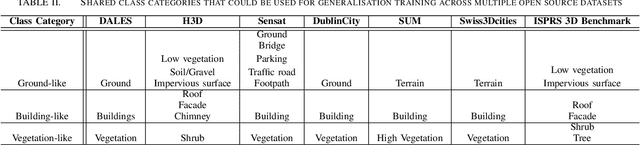

Semantic segmentation of aerial point cloud data can be utilised to differentiate which points belong to classes such as ground, buildings, or vegetation. Point clouds generated from aerial sensors mounted to drones or planes can utilise LIDAR sensors or cameras along with photogrammetry. Each method of data collection contains unique characteristics which can be learnt independently with state-of-the-art point cloud segmentation models. Utilising a single point cloud segmentation model can be desirable in situations where point cloud sensors, quality, and structures can change. In these situations it is desirable that the segmentation model can handle these variations with predictable and consistent results. Although deep learning can segment point clouds accurately it often suffers in generalisation, adapting poorly to data which is different than the training data. To address this issue, we propose to utilise multiple available open source fully annotated datasets to train and test models that are better able to generalise. In this paper we discuss the combination of these datasets into a simple training set and challenging test set. Combining datasets allows us to evaluate generalisation performance on known variations in the point cloud data. We show that a naive combination of datasets produces a model with improved generalisation performance as expected. We go on to show that an improved sampling strategy which decreases sampling variations increases the generalisation performance substantially on top of this. Experiments to find which sample variations give this performance boost found that consistent densities are the most important.
Weakly Supervised Training of Monocular 3D Object Detectors Using Wide Baseline Multi-view Traffic Camera Data
Oct 21, 2021



Accurate 7DoF prediction of vehicles at an intersection is an important task for assessing potential conflicts between road users. In principle, this could be achieved by a single camera system that is capable of detecting the pose of each vehicle but this would require a large, accurately labelled dataset from which to train the detector. Although large vehicle pose datasets exist (ostensibly developed for autonomous vehicles), we find training on these datasets inadequate. These datasets contain images from a ground level viewpoint, whereas an ideal view for intersection observation would be elevated higher above the road surface. We develop an alternative approach using a weakly supervised method of fine tuning 3D object detectors for traffic observation cameras; showing in the process that large existing autonomous vehicle datasets can be leveraged for pre-training. To fine-tune the monocular 3D object detector, our method utilises multiple 2D detections from overlapping, wide-baseline views and a loss that encodes the subjacent geometric consistency. Our method achieves vehicle 7DoF pose prediction accuracy on our dataset comparable to the top performing monocular 3D object detectors on autonomous vehicle datasets. We present our training methodology, multi-view reprojection loss, and dataset.