 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Utilisation of Multiple Open-Source Datasets to Improve Generalisation Performance of Point Cloud Segmentation Models
Paper and Code
Nov 29, 2022

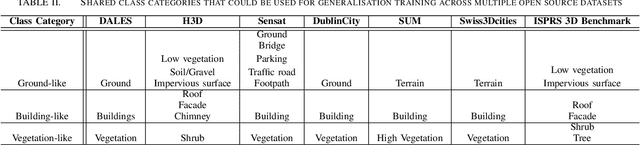

Semantic segmentation of aerial point cloud data can be utilised to differentiate which points belong to classes such as ground, buildings, or vegetation. Point clouds generated from aerial sensors mounted to drones or planes can utilise LIDAR sensors or cameras along with photogrammetry. Each method of data collection contains unique characteristics which can be learnt independently with state-of-the-art point cloud segmentation models. Utilising a single point cloud segmentation model can be desirable in situations where point cloud sensors, quality, and structures can change. In these situations it is desirable that the segmentation model can handle these variations with predictable and consistent results. Although deep learning can segment point clouds accurately it often suffers in generalisation, adapting poorly to data which is different than the training data. To address this issue, we propose to utilise multiple available open source fully annotated datasets to train and test models that are better able to generalise. In this paper we discuss the combination of these datasets into a simple training set and challenging test set. Combining datasets allows us to evaluate generalisation performance on known variations in the point cloud data. We show that a naive combination of datasets produces a model with improved generalisation performance as expected. We go on to show that an improved sampling strategy which decreases sampling variations increases the generalisation performance substantially on top of this. Experiments to find which sample variations give this performance boost found that consistent densities are the most important.