 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deformable Attention-Based Detection Transformer with Cross-Scale Feature Fusion for Industrial Coil Spring Inspection
Mar 13, 2026Automated visual inspection of locomotive coil springs presents significant challenges due to the morphological diversity of surface defects, substantial scale variations, and complex industrial backgrounds. This paper proposes MSD-DETR (Multi-Scale Deformable Detection Transformer), a novel detection framework that addresses these challenges through three key innovations: (1) a structural re-parameterization strategy that decouples training-time multi-branch topology from inference-time efficiency, enhancing feature extraction while maintaining real-time performance; (2) a deformable attention mechanism that enables content-adaptive spatial sampling, allowing dynamic focus on defect-relevant regions regardless of morphological irregularity; and (3) a cross-scale feature fusion architecture incorporating GSConv modules and VoVGSCSP blocks for effective multi-resolution information aggregation. Comprehensive experiments on a real-world locomotive coil spring dataset demonstrate that MSD-DETR achieves 92.4\% mAP@0.5 at 98 FPS, outperforming state-of-the-art detectors including YOLOv8 (+3.1\% mAP) and the baseline RT-DETR (+2.8\% mAP) while maintaining comparable inference speed, establishing a new benchmark for industrial coil spring quality inspection.
TerraBind: Fast and Accurate Binding Affinity Prediction through Coarse Structural Representations
Feb 08, 2026We present TerraBind, a foundation model for protein-ligand structure and binding affinity prediction that achieves 26-fold faster inference than state-of-the-art methods while improving affinity prediction accuracy by $\sim$20\%. Current deep learning approaches to structure-based drug design rely on expensive all-atom diffusion to generate 3D coordinates, creating inference bottlenecks that render large-scale compound screening computationally intractable. We challenge this paradigm with a critical hypothesis: full all-atom resolution is unnecessary for accurate small molecule pose and binding affinity prediction. TerraBind tests this hypothesis through a coarse pocket-level representation (protein C$_β$ atoms and ligand heavy atoms only) within a multimodal architecture combining COATI-3 molecular encodings and ESM-2 protein embeddings that learns rich structural representations, which are used in a diffusion-free optimization module for pose generation and a binding affinity likelihood prediction module. On structure prediction benchmarks (FoldBench, PoseBusters, Runs N' Poses), TerraBind matches diffusion-based baselines in ligand pose accuracy. Crucially, TerraBind outperforms Boltz-2 by $\sim$20\% in Pearson correlation for binding affinity prediction on both a public benchmark (CASP16) and a diverse proprietary dataset (18 biochemical/cell assays). We show that the affinity prediction module also provides well-calibrated affinity uncertainty estimates, addressing a critical gap in reliable compound prioritization for drug discovery. Furthermore, this module enables a continual learning framework and a hedged batch selection strategy that, in simulated drug discovery cycles, achieves 6$\times$ greater affinity improvement of selected molecules over greedy-based approaches.
MA-LipNet: Multi-Dimensional Attention Networks for Robust Lipreading
Jan 27, 2026Lipreading, the technology of decoding spoken content from silent videos of lip movements, holds significant application value in fields such as public security. However, due to the subtle nature of articulatory gestures, existing lipreading methods often suffer from limited feature discriminability and poor generalization capabilities. To address these challenges, this paper delves into the purification of visual features from temporal, spatial, and channel dimensions. We propose a novel method named Multi-Attention Lipreading Network(MA-LipNet). The core of MA-LipNet lies in its sequential application of three dedicated attention modules. Firstly, a \textit{Channel Attention (CA)} module is employed to adaptively recalibrate channel-wise features, thereby mitigating interference from less informative channels. Subsequently, two spatio-temporal attention modules with distinct granularities-\textit{Joint Spatial-Temporal Attention (JSTA)} and \textit{Separate Spatial-Temporal Attention (SSTA)}-are leveraged to suppress the influence of irrelevant pixels and video frames. The JSTA module performs a coarse-grained filtering by computing a unified weight map across the spatio-temporal dimensions, while the SSTA module conducts a more fine-grained refinement by separately modeling temporal and spatial attentions. Extensive experiments conducted on the CMLR and GRID datasets demonstrate that MA-LipNet significantly reduces the Character Error Rate (CER) and Word Error Rate (WER), validating its effectiveness and superiority over several state-of-the-art methods. Our work highlights the importance of multi-dimensional feature refinement for robust visual speech recognition.
Pretrained Joint Predictions for Scalable Batch Bayesian Optimization of Molecular Designs
Nov 14, 2025Batched synthesis and testing of molecular designs is the key bottleneck of drug development. There has been great interest in leveraging biomolecular foundation models as surrogates to accelerate this process. In this work, we show how to obtain scalable probabilistic surrogates of binding affinity for use in Batch Bayesian Optimization (Batch BO). This demands parallel acquisition functions that hedge between designs and the ability to rapidly sample from a joint predictive density to approximate them. Through the framework of Epistemic Neural Networks (ENNs), we obtain scalable joint predictive distributions of binding affinity on top of representations taken from large structure-informed models. Key to this work is an investigation into the importance of prior networks in ENNs and how to pretrain them on synthetic data to improve downstream performance in Batch BO. Their utility is demonstrated by rediscovering known potent EGFR inhibitors on a semi-synthetic benchmark in up to 5x fewer iterations, as well as potent inhibitors from a real-world small-molecule library in up to 10x fewer iterations, offering a promising solution for large-scale drug discovery applications.
Cascade learning in multi-task encoder-decoder networks for concurrent bone segmentation and glenohumeral joint assessment in shoulder CT scans
Oct 16, 2024



Osteoarthritis is a degenerative condition affecting bones and cartilage, often leading to osteophyte formation, bone density loss, and joint space narrowing. Treatment options to restore normal joint function vary depending on the severity of the condition. This work introduces an innovative deep-learning framework processing shoulder CT scans. It features the semantic segmentation of the proximal humerus and scapula, the 3D reconstruction of bone surfaces, the identification of the glenohumeral (GH) joint region, and the staging of three common osteoarthritic-related pathologies: osteophyte formation (OS), GH space reduction (JS), and humeroscapular alignment (HSA). The pipeline comprises two cascaded CNN architectures: 3D CEL-UNet for segmentation and 3D Arthro-Net for threefold classification. A retrospective dataset of 571 CT scans featuring patients with various degrees of GH osteoarthritic-related pathologies was used to train, validate, and test the pipeline. Root mean squared error and Hausdorff distance median values for 3D reconstruction were 0.22mm and 1.48mm for the humerus and 0.24mm and 1.48mm for the scapula, outperforming state-of-the-art architectures and making it potentially suitable for a PSI-based shoulder arthroplasty preoperative plan context. The classification accuracy for OS, JS, and HSA consistently reached around 90% across all three categories. The computational time for the inference pipeline was less than 15s, showcasing the framework's efficiency and compatibility with orthopedic radiology practice. The outcomes represent a promising advancement toward the medical translation of artificial intelligence tools. This progress aims to streamline the preoperative planning pipeline delivering high-quality bone surfaces and supporting surgeons in selecting the most suitable surgical approach according to the unique patient joint conditions.
Statistical Model Checking of Human-Robot Interaction Scenarios
Jul 23, 2020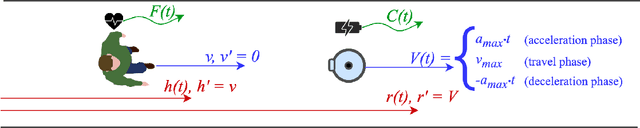
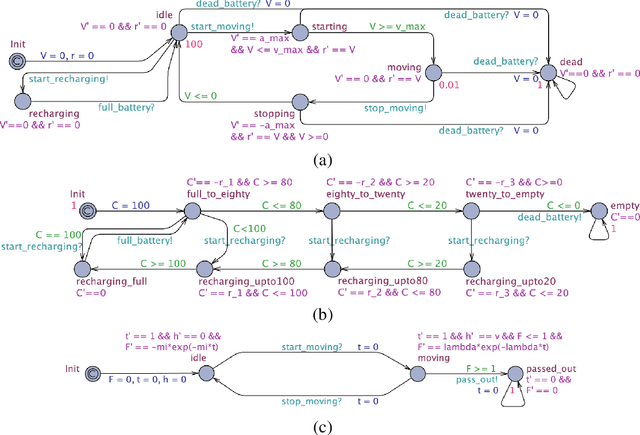
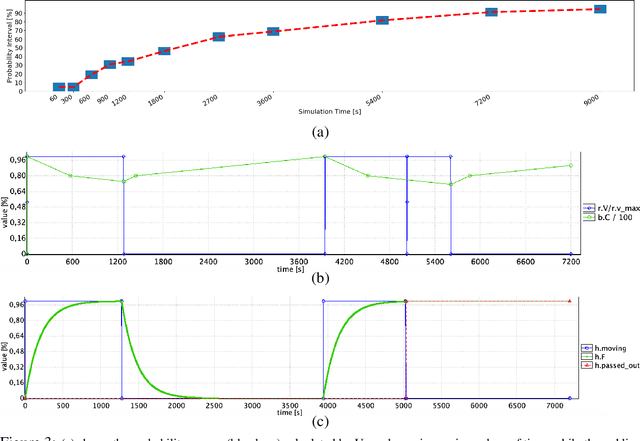
Robots are soon going to be deployed in non-industrial environments. Before society can take such a step, it is necessary to endow complex robotic systems with mechanisms that make them reliable enough to operate in situations where the human factor is predominant. This calls for the development of robotic frameworks that can soundly guarantee that a collection of properties are verified at all times during operation. While developing a mission plan, robots should take into account factors such as human physiology. In this paper, we present an example of how a robotic application that involves human interaction can be modeled through hybrid automata, and analyzed by using statistical model-checking. We exploit statistical techniques to determine the probability with which some properties are verified, thus easing the state-space explosion problem. The analysis is performed using the Uppaal tool. In addition, we used Uppaal to run simulations that allowed us to show non-trivial time dynamics that describe the behavior of the real system, including human-related variables. Overall, this process allows developers to gain useful insights into their application and to make decisions about how to improve it to balance efficiency and user satisfaction.
* In Proceedings AREA 2020, arXiv:2007.11260
Co-Simulation of Human-Robot Collaboration: from Temporal Logic to 3D Simulation
Jul 23, 2020Human-Robot Collaboration (HRC) is rapidly replacing the traditional application of robotics in the manufacturing industry. Robots and human operators no longer have to perform their tasks in segregated areas and are capable of working in close vicinity and performing hybrid tasks -- performed partially by humans and by robots. We have presented a methodology in an earlier work [16] to promote and facilitate formally modeling HRC systems, which are notoriously safety-critical. Relying on temporal logic modeling capabilities and automated model checking tools, we built a framework to formally model HRC systems and verify the physical safety of human operator against ISO 10218-2 [10] standard. In order to make our proposed formal verification framework more appealing to safety engineers, whom are usually not very fond of formal modeling and verification techniques, we decided to couple our model checking approach with a 3D simulator that demonstrates the potential hazardous situations to the safety engineers in a more transparent way. This paper reports our co-simulation approach, using Morse simulator [4] and Zot model checker [14].
* In Proceedings AREA 2020, arXiv:2007.11260