 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Piecewise Linear Ensembles
May 01, 2024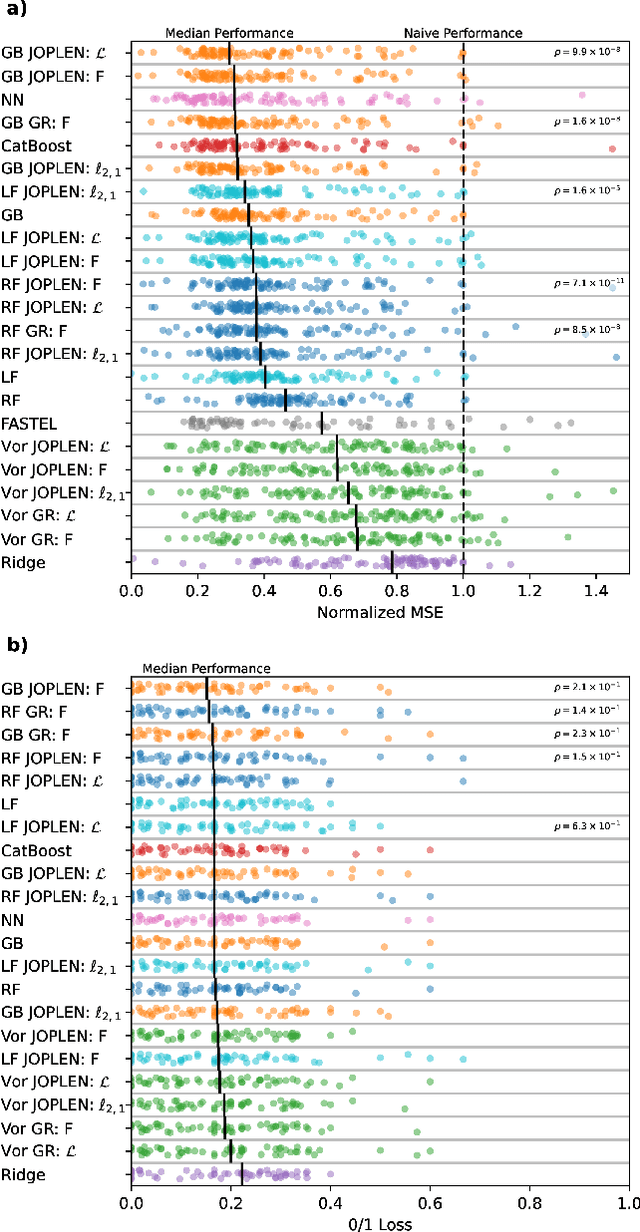
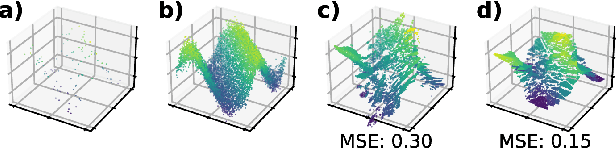
Tree ensembles achieve state-of-the-art performance despite being greedily optimized. Global refinement (GR) reduces greediness by jointly and globally optimizing all constant leaves. We propose Joint Optimization of Piecewise Linear ENsembles (JOPLEN), a piecewise-linear extension of GR. Compared to GR, JOPLEN improves model flexibility and can apply common penalties, including sparsity-promoting matrix norms and subspace-norms, to nonlinear prediction. We evaluate the Frobenius norm, $\ell_{2,1}$ norm, and Laplacian regularization for 146 regression and classification datasets; JOPLEN, combined with GB trees and RF, achieves superior performance in both settings. Additionally, JOPLEN with a nuclear norm penalty empirically learns smooth and subspace-aligned functions. Finally, we perform multitask feature selection by extending the Dirty LASSO. JOPLEN Dirty LASSO achieves a superior feature sparsity/performance tradeoff to linear and gradient boosted approaches. We anticipate that JOPLEN will improve regression, classification, and feature selection across many fields.
Universal Feature Selection for Simultaneous Interpretability of Multitask Datasets
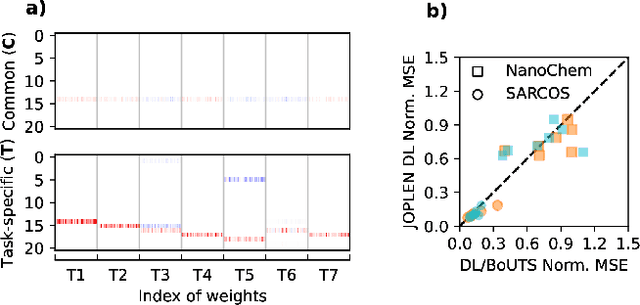
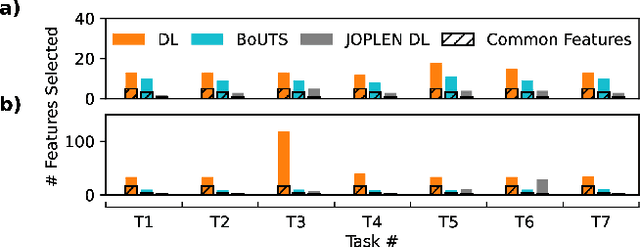
Mar 21, 2024Extracting meaningful features from complex, high-dimensional datasets across scientific domains remains challenging. Current methods often struggle with scalability, limiting their applicability to large datasets, or make restrictive assumptions about feature-property relationships, hindering their ability to capture complex interactions. BoUTS's general and scalable feature selection algorithm surpasses these limitations to identify both universal features relevant to all datasets and task-specific features predictive for specific subsets. Evaluated on seven diverse chemical regression datasets, BoUTS achieves state-of-the-art feature sparsity while maintaining prediction accuracy comparable to specialized methods. Notably, BoUTS's universal features enable domain-specific knowledge transfer between datasets, and suggest deep connections in seemingly-disparate chemical datasets. We expect these results to have important repercussions in manually-guided inverse problems. Beyond its current application, BoUTS holds immense potential for elucidating data-poor systems by leveraging information from similar data-rich systems. BoUTS represents a significant leap in cross-domain feature selection, potentially leading to advancements in various scientific fields.