 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Piecewise Linear Ensembles
Paper and Code
May 01, 2024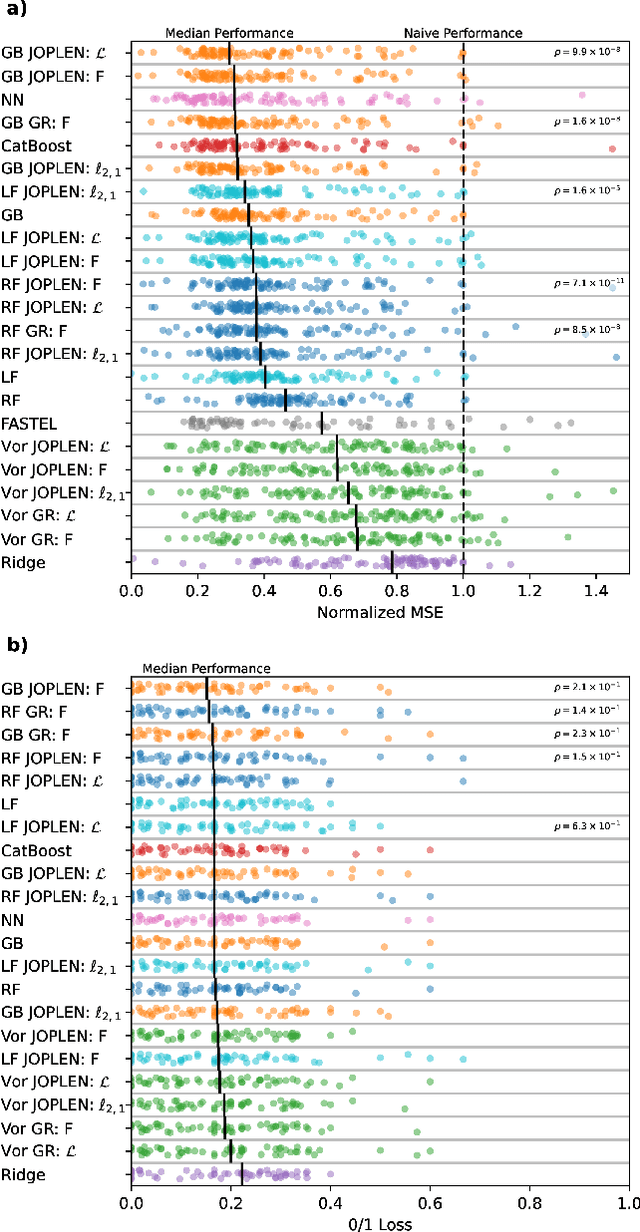
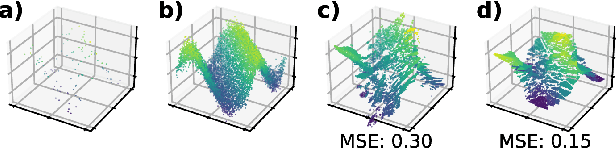
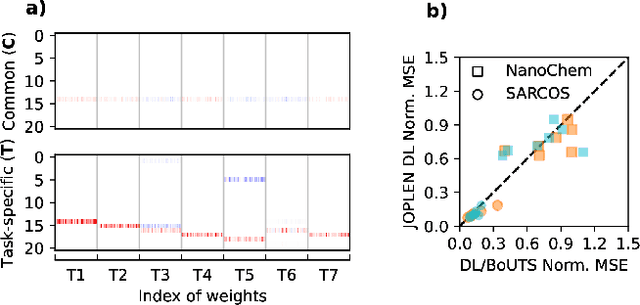
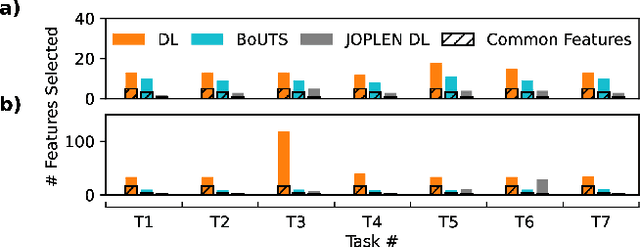
Tree ensembles achieve state-of-the-art performance despite being greedily optimized. Global refinement (GR) reduces greediness by jointly and globally optimizing all constant leaves. We propose Joint Optimization of Piecewise Linear ENsembles (JOPLEN), a piecewise-linear extension of GR. Compared to GR, JOPLEN improves model flexibility and can apply common penalties, including sparsity-promoting matrix norms and subspace-norms, to nonlinear prediction. We evaluate the Frobenius norm, $\ell_{2,1}$ norm, and Laplacian regularization for 146 regression and classification datasets; JOPLEN, combined with GB trees and RF, achieves superior performance in both settings. Additionally, JOPLEN with a nuclear norm penalty empirically learns smooth and subspace-aligned functions. Finally, we perform multitask feature selection by extending the Dirty LASSO. JOPLEN Dirty LASSO achieves a superior feature sparsity/performance tradeoff to linear and gradient boosted approaches. We anticipate that JOPLEN will improve regression, classification, and feature selection across many fields.