 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Text Relation Prediction for Multilingual Tweets
May 08, 2025Various social networks have been allowing media uploads for over a decade now. Still, it has not always been clear what is their relation with the posted text or even if there is any at all. In this work, we explore how multilingual vision-language models tackle the task of image-text relation prediction in different languages, and construct a dedicated balanced benchmark data set from Twitter posts in Latvian along with their manual translations into English. We compare our results to previous work and show that the more recently released vision-language model checkpoints are becoming increasingly capable at this task, but there is still much room for further improvement.
Annotations for Exploring Food Tweets From Multiple Aspects
Dec 09, 2024



This research builds upon the Latvian Twitter Eater Corpus (LTEC), which is focused on the narrow domain of tweets related to food, drinks, eating and drinking. LTEC has been collected for more than 12 years and reaching almost 3 million tweets with the basic information as well as extended automatically and manually annotated metadata. In this paper we supplement the LTEC with manually annotated subsets of evaluation data for machine translation, named entity recognition, timeline-balanced sentiment analysis, and text-image relation classification. We experiment with each of the data sets using baseline models and highlight future challenges for various modelling approaches.
Strategic Insights in Human and Large Language Model Tactics at Word Guessing Games
Sep 17, 2024



At the beginning of 2022, a simplistic word-guessing game took the world by storm and was further adapted to many languages beyond the original English version. In this paper, we examine the strategies of daily word-guessing game players that have evolved during a period of over two years. A survey gathered from 25% of frequent players reveals their strategies and motivations for continuing the daily journey. We also explore the capability of several popular open-access large language model systems and open-source models at comprehending and playing the game in two different languages. Results highlight the struggles of certain models to maintain correct guess length and generate repetitions, as well as hallucinations of non-existent words and inflections.
What Food Do We Tweet about on a Rainy Day?
Apr 11, 2023


Food choice is a complex phenomenon shaped by factors such as taste, ambience, culture or weather. In this paper, we explore food-related tweeting in different weather conditions. We inspect a Latvian food tweet dataset spanning the past decade in conjunction with a weather observation dataset consisting of average temperature, precipitation, and other phenomena. We find which weather conditions lead to specific food information sharing; automatically classify tweet sentiment and discuss how it changes depending on the weather. This research contributes to the growing area of large-scale social network data understanding of food consumers' choices and perceptions.
How Masterly Are People at Playing with Their Vocabulary? Analysis of the Wordle Game for Latvian
Oct 04, 2022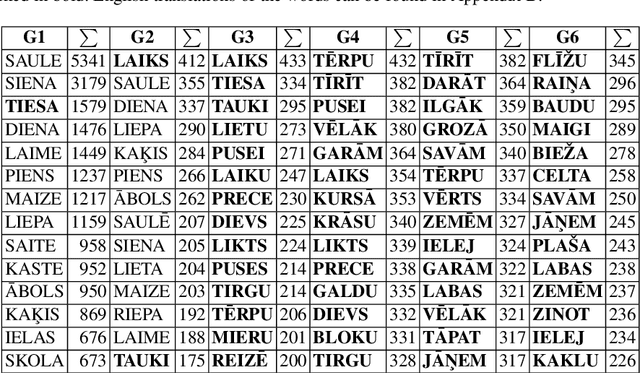

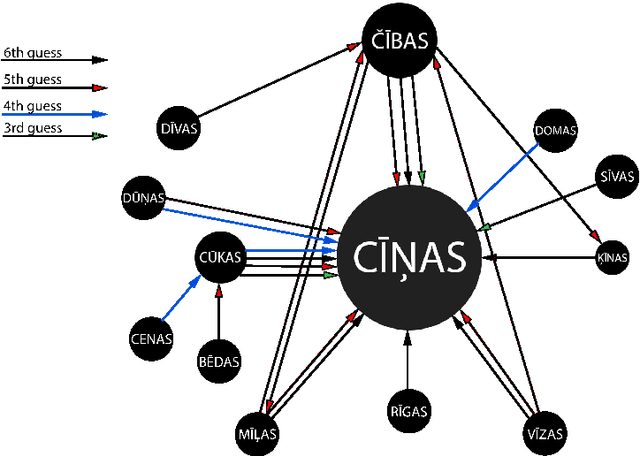
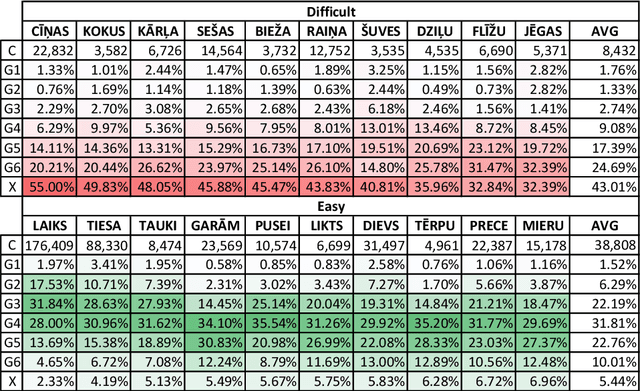
In this paper, we describe adaptation of a simple word guessing game that occupied the hearts and minds of people around the world. There are versions for all three Baltic countries and even several versions of each. We specifically pay attention to the Latvian version and look into how people form their guesses given any already uncovered hints. The paper analyses guess patterns, easy and difficult word characteristics, and player behaviour and response.
Revisiting Context Choices for Context-aware Machine Translation
Sep 07, 2021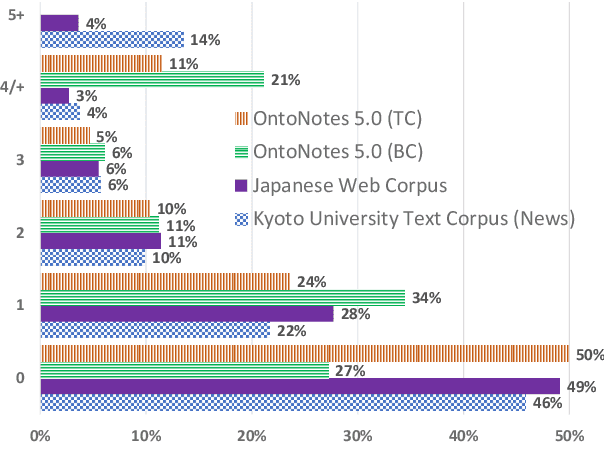
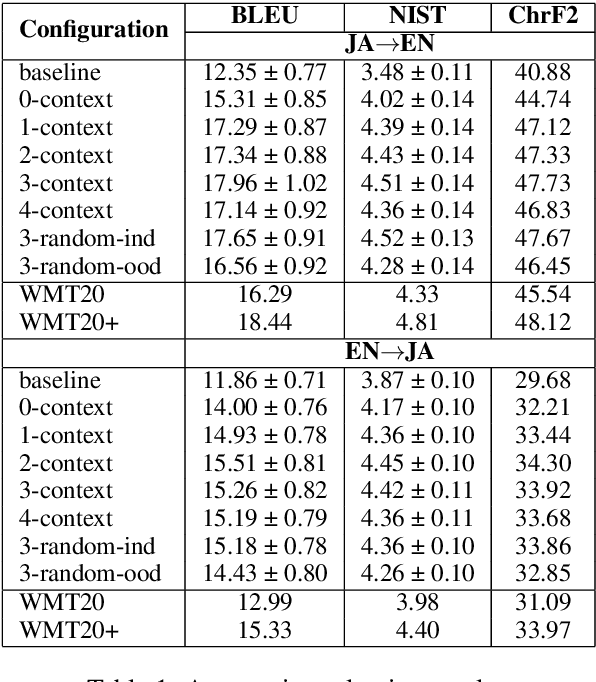
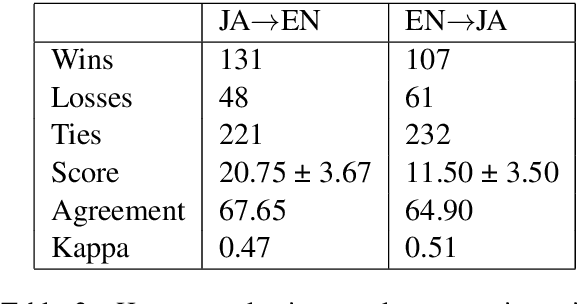

One of the most popular methods for context-aware machine translation (MT) is to use separate encoders for the source sentence and context as multiple sources for one target sentence. Recent work has cast doubt on whether these models actually learn useful signals from the context or are improvements in automatic evaluation metrics just a side-effect. We show that multi-source transformer models improve MT over standard transformer-base models even with empty lines provided as context, but the translation quality improves significantly (1.51 - 2.65 BLEU) when a sufficient amount of correct context is provided. We also show that even though randomly shuffling in-domain context can also improve over baselines, the correct context further improves translation quality and random out-of-domain context further degrades it.
Fragmented and Valuable: Following Sentiment Changes in Food Tweets
Jun 09, 2021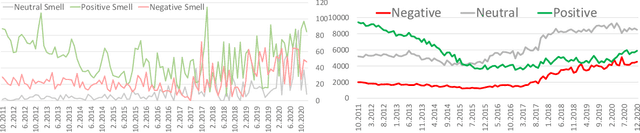
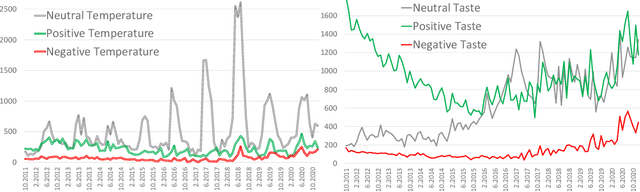

We analysed sentiment and frequencies related to smell, taste and temperature expressed by food tweets in the Latvian language. To get a better understanding of the role of smell, taste and temperature in the mental map of food associations, we looked at such categories as 'tasty' and 'healthy', which turned out to be mutually exclusive. By analysing the occurrence frequency of words associated with these categories, we discovered that food discourse overall was permeated by `tasty' while the category of 'healthy' was relatively small. Finally, we used the analysis of temporal dynamics to see if we can trace seasonality or other temporal aspects in smell, taste and temperature as reflected in food tweets. Understanding the composition of social media content with relation to smell, taste and temperature in food tweets allows us to develop our work further - on food culture/seasonality and its relation to temperature, on our limited capacity to express smell-related sentiments, and the lack of the paradigm of taste in discussing food healthiness.
Document-aligned Japanese-English Conversation Parallel Corpus
Dec 11, 2020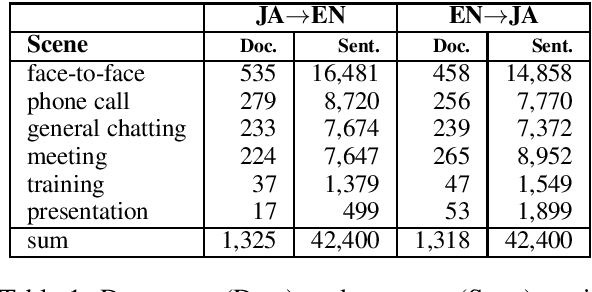
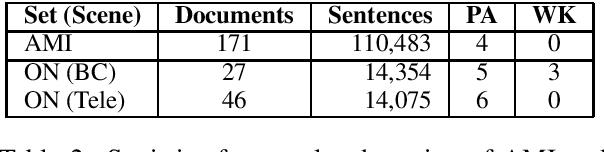

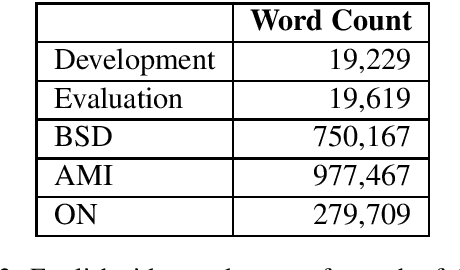
Sentence-level (SL) machine translation (MT) has reached acceptable quality for many high-resourced languages, but not document-level (DL) MT, which is difficult to 1) train with little amount of DL data; and 2) evaluate, as the main methods and data sets focus on SL evaluation. To address the first issue, we present a document-aligned Japanese-English conversation corpus, including balanced, high-quality business conversation data for tuning and testing. As for the second issue, we manually identify the main areas where SL MT fails to produce adequate translations in lack of context. We then create an evaluation set where these phenomena are annotated to alleviate automatic evaluation of DL systems. We train MT models using our corpus to demonstrate how using context leads to improvements.
* Published in proceedings of the Fifth Conference on Machine Translation, 2020
Designing the Business Conversation Corpus
Aug 05, 2020
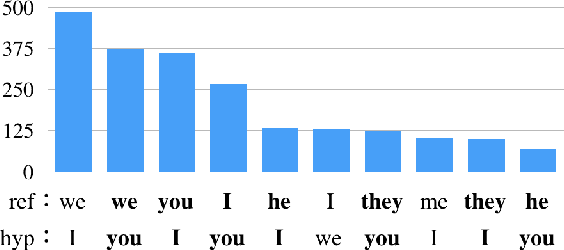
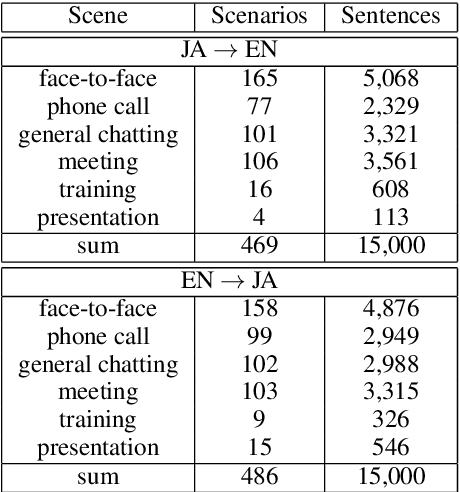

While the progress of machine translation of written text has come far in the past several years thanks to the increasing availability of parallel corpora and corpora-based training technologies, automatic translation of spoken text and dialogues remains challenging even for modern systems. In this paper, we aim to boost the machine translation quality of conversational texts by introducing a newly constructed Japanese-English business conversation parallel corpus. A detailed analysis of the corpus is provided along with challenging examples for automatic translation. We also experiment with adding the corpus in a machine translation training scenario and show how the resulting system benefits from its use.
What Can We Learn From Almost a Decade of Food Tweets
Jul 10, 2020

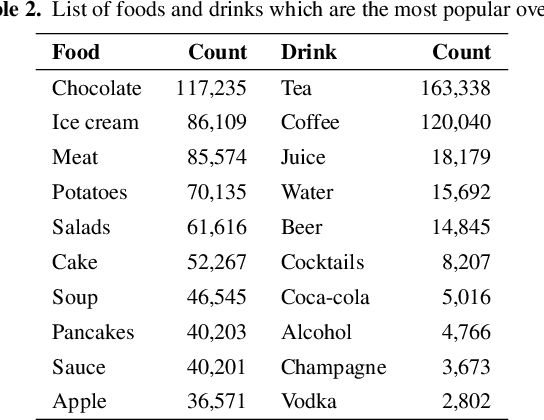
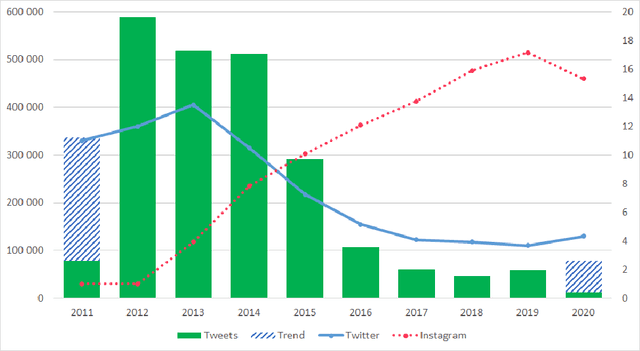
We present the Latvian Twitter Eater Corpus - a set of tweets in the narrow domain related to food, drinks, eating and drinking. The corpus has been collected over time-span of over 8 years and includes over 2 million tweets entailed with additional useful data. We also separate two sub-corpora of question and answer tweets and sentiment annotated tweets. We analyse contents of the corpus and demonstrate use-cases for the sub-corpora by training domain-specific question-answering and sentiment-analysis models using data from the corpus.