 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Context Choices for Context-aware Machine Translation
Paper and Code
Sep 07, 2021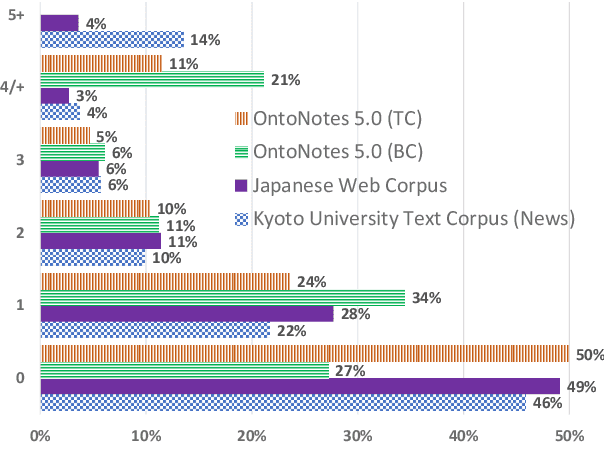
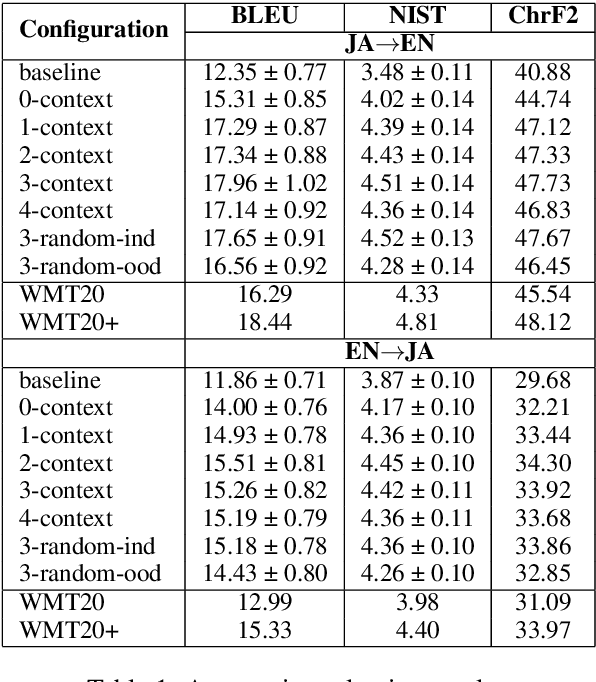
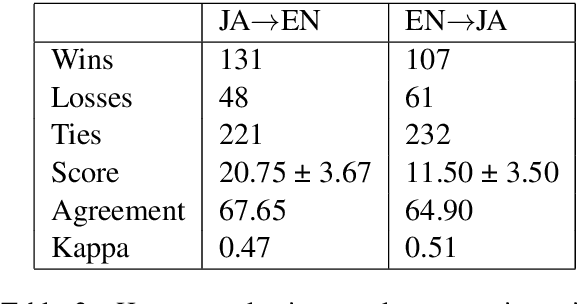

One of the most popular methods for context-aware machine translation (MT) is to use separate encoders for the source sentence and context as multiple sources for one target sentence. Recent work has cast doubt on whether these models actually learn useful signals from the context or are improvements in automatic evaluation metrics just a side-effect. We show that multi-source transformer models improve MT over standard transformer-base models even with empty lines provided as context, but the translation quality improves significantly (1.51 - 2.65 BLEU) when a sufficient amount of correct context is provided. We also show that even though randomly shuffling in-domain context can also improve over baselines, the correct context further improves translation quality and random out-of-domain context further degrades it.