 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANTE: Deep Affinity Network for Clustering Conversational Interactants
Jul 24, 2019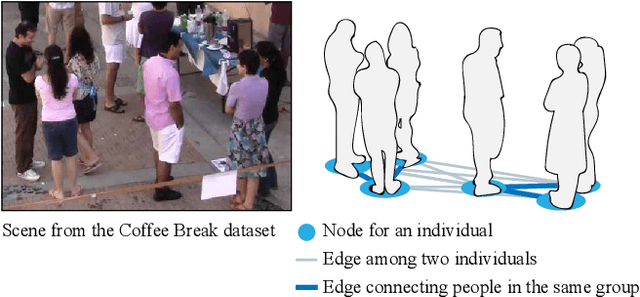
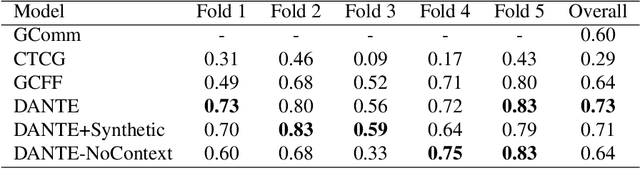


We propose a data-driven approach to visually detect conversational groups by identifying spatial arrangements typical of these focused social encounters. Our approach uses a novel Deep Affinity Network (DANTE) to predict the likelihood that two individuals in a scene are part of the same conversational group, considering contextual information like the position and orientation of other nearby individuals. The predicted pair-wise affinities are then used in a graph clustering framework to identify both small (e.g., dyads) and bigger groups. The results from our evaluation on two standard benchmarks suggest that the combination of powerful deep learning methods with classical clustering techniques can improve the detection of conversational groups in comparison to prior approaches. Our technique has a wide range of applications from visual scene understanding, e.g., for surveillance, to social robotics.
Image Completion on CIFAR-10
Oct 07, 2018
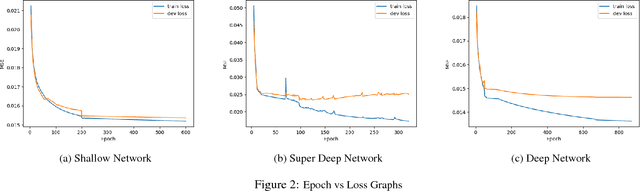
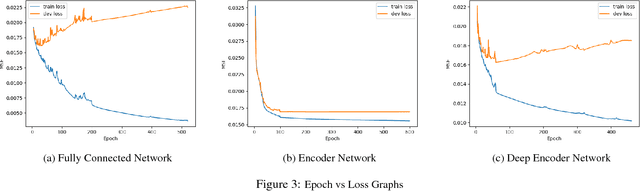

This project performed image completion on CIFAR-10, a dataset of 60,000 32x32 RGB images, using three different neural network architectures: fully convolutional networks, convolutional networks with fully connected layers, and encoder-decoder convolutional networks. The highest performing model was a deep fully convolutional network, which was able to achieve a mean squared error of .015 when comparing the original image pixel values with the predicted pixel values. As well, this network was able to output in-painted images which appeared real to the human eye.
Conversational Group Detection With Deep Convolutional Networks
Oct 07, 2018



Detection of interacting and conversational groups from images has applications in video surveillance and social robotics. In this paper we build on prior attempts to find conversational groups by detection of social gathering spaces called o-spaces used to assign people to groups. As our contributions to the task, we are the first paper to incorporate features extracted from the room layout image, and the first to incorporate a deep network to generate an image representation of the proposed o-spaces. Specifically, this novel network builds on the PointNet architecture which allows unordered inputs of variable sizes. We present accuracies which demonstrate the ability to rival and sometimes outperform the best models, but due to a data imbalance issue we do not yet outperform existing models in our test results.