 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Conditional Image Embedding Framework Leveraging Large Vision Language Models
Dec 26, 2025Conditional image embeddings are feature representations that focus on specific aspects of an image indicated by a given textual condition (e.g., color, genre), which has been a challenging problem. Although recent vision foundation models, such as CLIP, offer rich representations of images, they are not designed to focus on a specified condition. In this paper, we propose DIOR, a method that leverages a large vision-language model (LVLM) to generate conditional image embeddings. DIOR is a training-free approach that prompts the LVLM to describe an image with a single word related to a given condition. The hidden state vector of the LVLM's last token is then extracted as the conditional image embedding. DIOR provides a versatile solution that can be applied to any image and condition without additional training or task-specific priors. Comprehensive experimental results on conditional image similarity tasks demonstrate that DIOR outperforms existing training-free baselines, including CLIP. Furthermore, DIOR achieves superior performance compared to methods that require additional training across multiple settings.
QCoder Benchmark: Bridging Language Generation and Quantum Hardware through Simulator-Based Feedback
Oct 30, 2025Large language models (LLMs) have increasingly been applied to automatic programming code generation. This task can be viewed as a language generation task that bridges natural language, human knowledge, and programming logic. However, it remains underexplored in domains that require interaction with hardware devices, such as quantum programming, where human coders write Python code that is executed on a quantum computer. To address this gap, we introduce QCoder Benchmark, an evaluation framework that assesses LLMs on quantum programming with feedback from simulated hardware devices. Our benchmark offers two key features. First, it supports evaluation using a quantum simulator environment beyond conventional Python execution, allowing feedback of domain-specific metrics such as circuit depth, execution time, and error classification, which can be used to guide better generation. Second, it incorporates human-written code submissions collected from real programming contests, enabling both quantitative comparisons and qualitative analyses of LLM outputs against human-written codes. Our experiments reveal that even advanced models like GPT-4o achieve only around 18.97% accuracy, highlighting the difficulty of the benchmark. In contrast, reasoning-based models such as o3 reach up to 78% accuracy, outperforming averaged success rates of human-written codes (39.98%). We release the QCoder Benchmark dataset and public evaluation API to support further research.
Prompting for Numerical Sequences: A Case Study on Market Comment Generation
Apr 03, 2024

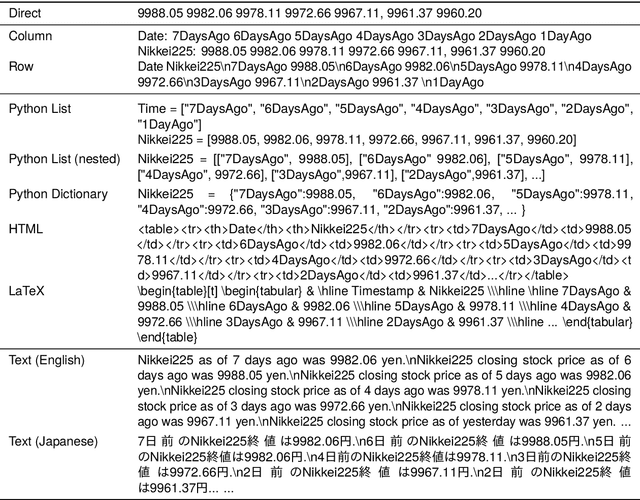

Large language models (LLMs) have been applied to a wide range of data-to-text generation tasks, including tables, graphs, and time-series numerical data-to-text settings. While research on generating prompts for structured data such as tables and graphs is gaining momentum, in-depth investigations into prompting for time-series numerical data are lacking. Therefore, this study explores various input representations, including sequences of tokens and structured formats such as HTML, LaTeX, and Python-style codes. In our experiments, we focus on the task of Market Comment Generation, which involves taking a numerical sequence of stock prices as input and generating a corresponding market comment. Contrary to our expectations, the results show that prompts resembling programming languages yield better outcomes, whereas those similar to natural languages and longer formats, such as HTML and LaTeX, are less effective. Our findings offer insights into creating effective prompts for tasks that generate text from numerical sequences.