 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Tacit Information Embedded in CNN Layers for Visual Tracking
Oct 02, 2020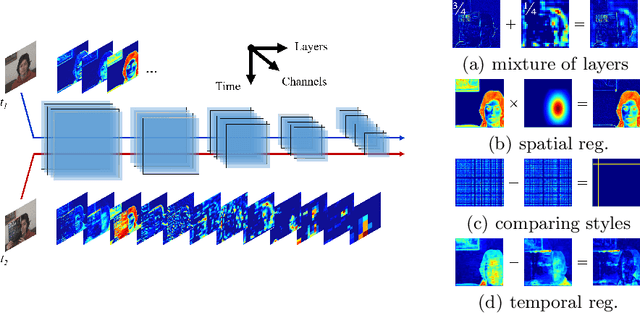



Different layers in CNNs provide not only different levels of abstraction for describing the objects in the input but also encode various implicit information about them. The activation patterns of different features contain valuable information about the stream of incoming images: spatial relations, temporal patterns, and co-occurrence of spatial and spatiotemporal (ST) features. The studies in visual tracking literature, so far, utilized only one of the CNN layers, a pre-fixed combination of them, or an ensemble of trackers built upon individual layers. In this study, we employ an adaptive combination of several CNN layers in a single DCF tracker to address variations of the target appearances and propose the use of style statistics on both spatial and temporal properties of the target, directly extracted from CNN layers for visual tracking. Experiments demonstrate that using the additional implicit data of CNNs significantly improves the performance of the tracker. Results demonstrate the effectiveness of using style similarity and activation consistency regularization in improving its localization and scale accuracy.
Adversarial Semi-Supervised Multi-Domain Tracking
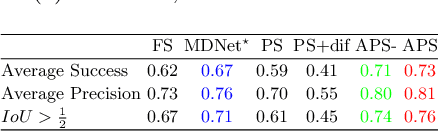
Sep 30, 2020

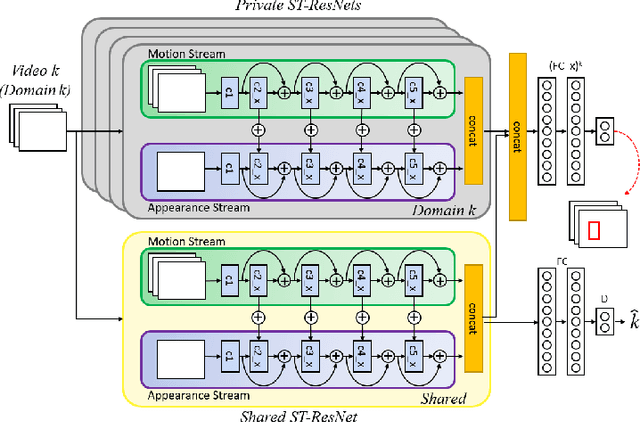
Neural networks for multi-domain learning empowers an effective combination of information from different domains by sharing and co-learning the parameters. In visual tracking, the emerging features in shared layers of a multi-domain tracker, trained on various sequences, are crucial for tracking in unseen videos. Yet, in a fully shared architecture, some of the emerging features are useful only in a specific domain, reducing the generalization of the learned feature representation. We propose a semi-supervised learning scheme to separate domain-invariant and domain-specific features using adversarial learning, to encourage mutual exclusion between them, and to leverage self-supervised learning for enhancing the shared features using the unlabeled reservoir. By employing these features and training dedicated layers for each sequence, we build a tracker that performs exceptionally on different types of videos.
AnimGAN: A Spatiotemporally-Conditioned Generative Adversarial Network for Character Animation
May 23, 2020


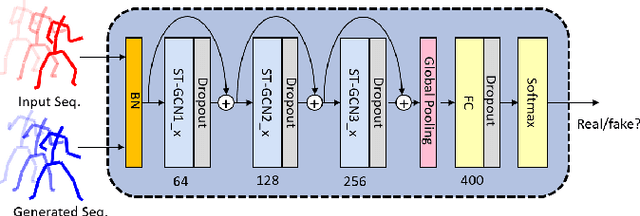
Producing realistic character animations is one of the essential tasks in human-AI interactions. Considered as a sequence of poses of a humanoid, the task can be considered as a sequence generation problem with spatiotemporal smoothness and realism constraints. Additionally, we wish to control the behavior of AI agents by giving them what to do and, more specifically, how to do it. We proposed a spatiotemporally-conditioned GAN that generates a sequence that is similar to a given sequence in terms of semantics and spatiotemporal dynamics. Using LSTM-based generator and graph ConvNet discriminator, this system is trained end-to-end on a large gathered dataset of gestures, expressions, and actions. Experiments showed that compared to traditional conditional GAN, our method creates plausible, realistic, and semantically relevant humanoid animation sequences that match user expectations.
Long and Short Memory Balancing in Visual Co-Tracking using Q-Learning
Feb 14, 2019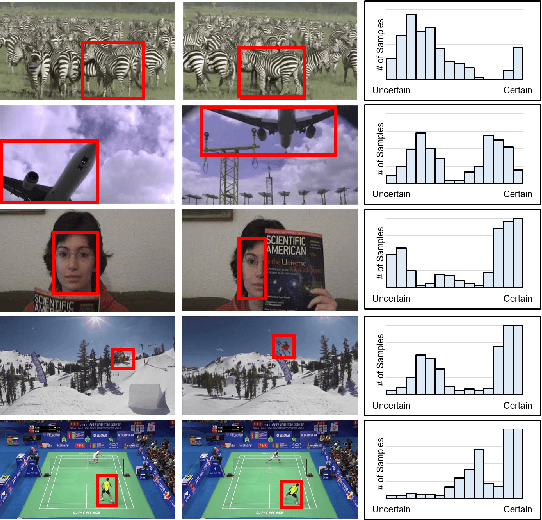

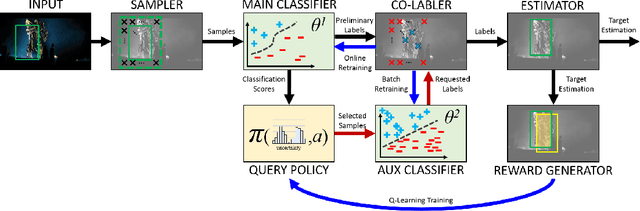

Employing one or more additional classifiers to break the self-learning loop in tracing-by-detection has gained considerable attention. Most of such trackers merely utilize the redundancy to address the accumulating label error in the tracking loop, and suffer from high computational complexity as well as tracking challenges that may interrupt all classifiers (e.g. temporal occlusions). We propose the active co-tracking framework, in which the main classifier of the tracker labels samples of the video sequence, and only consults auxiliary classifier when it is uncertain. Based on the source of the uncertainty and the differences of two classifiers (e.g. accuracy, speed, update frequency, etc.), different policies should be taken to exchange the information between two classifiers. Here, we introduce a reinforcement learning approach to find the appropriate policy by considering the state of the tracker in a specific sequence. The proposed method yields promising results in comparison to the best tracking-by-detection approaches.
Information-Maximizing Sampling to Promote Tracking-by-Detection
Jun 07, 2018

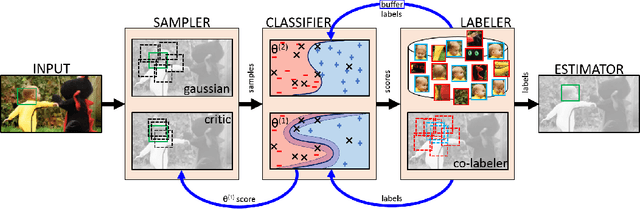
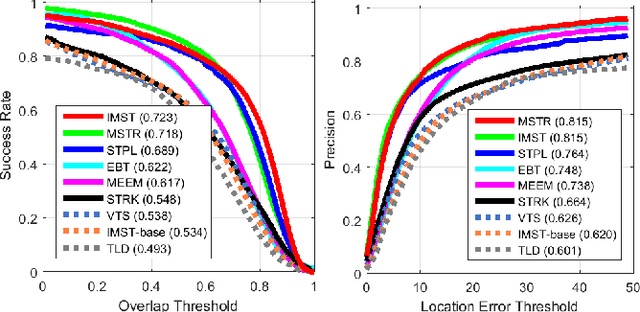
The performance of an adaptive tracking-by-detection algorithm not only depends on the classification and updating processes but also on the sampling. Typically, such trackers select their samples from the vicinity of the last predicted object location, or from its expected location using a pre-defined motion model, which does not exploit the contents of the samples nor the information provided by the classifier. We introduced the idea of most informative sampling, in which the sampler attempts to select samples that trouble the classifier of a discriminative tracker. We then proposed an active discriminative co-tracker that embed an adversarial sampler to increase its robustness against various tracking challenges. Experiments show that our proposed tracker outperforms state-of-the-art trackers on various benchmark videos.
Active Collaborative Ensemble Tracking
Apr 28, 2017



A discriminative ensemble tracker employs multiple classifiers, each of which casts a vote on all of the obtained samples. The votes are then aggregated in an attempt to localize the target object. Such method relies on collective competence and the diversity of the ensemble to approach the target/non-target classification task from different views. However, by updating all of the ensemble using a shared set of samples and their final labels, such diversity is lost or reduced to the diversity provided by the underlying features or internal classifiers' dynamics. Additionally, the classifiers do not exchange information with each other while striving to serve the collective goal, i.e., better classification. In this study, we propose an active collaborative information exchange scheme for ensemble tracking. This, not only orchestrates different classifier towards a common goal but also provides an intelligent update mechanism to keep the diversity of classifiers and to mitigate the shortcomings of one with the others. The data exchange is optimized with regard to an ensemble uncertainty utility function, and the ensemble is updated via co-training. The evaluations demonstrate promising results realized by the proposed algorithm for the real-world online tracking.
Efficient Asymmetric Co-Tracking using Uncertainty Sampling
Mar 31, 2017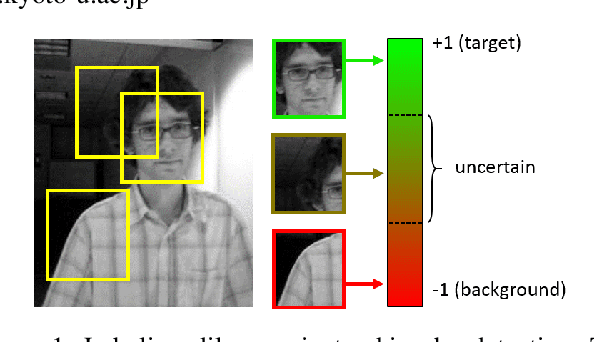
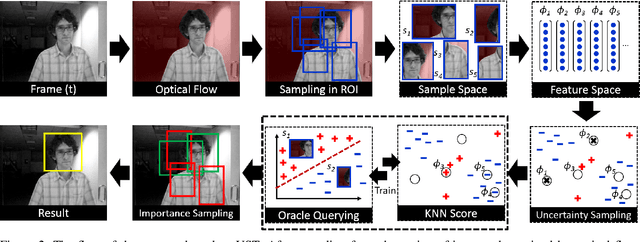

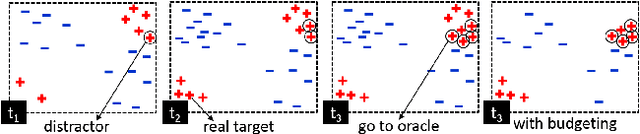
Adaptive tracking-by-detection approaches are popular for tracking arbitrary objects. They treat the tracking problem as a classification task and use online learning techniques to update the object model. However, these approaches are heavily invested in the efficiency and effectiveness of their detectors. Evaluating a massive number of samples for each frame (e.g., obtained by a sliding window) forces the detector to trade the accuracy in favor of speed. Furthermore, misclassification of borderline samples in the detector introduce accumulating errors in tracking. In this study, we propose a co-tracking based on the efficient cooperation of two detectors: a rapid adaptive exemplar-based detector and another more sophisticated but slower detector with a long-term memory. The sampling labeling and co-learning of the detectors are conducted by an uncertainty sampling unit, which improves the speed and accuracy of the system. We also introduce a budgeting mechanism which prevents the unbounded growth in the number of examples in the first detector to maintain its rapid response. Experiments demonstrate the efficiency and effectiveness of the proposed tracker against its baselines and its superior performance against state-of-the-art trackers on various benchmark videos.