 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimGAN: A Spatiotemporally-Conditioned Generative Adversarial Network for Character Animation
Paper and Code
May 23, 2020


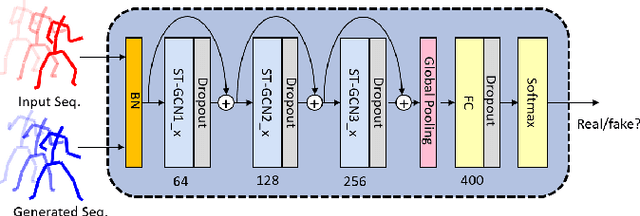
Producing realistic character animations is one of the essential tasks in human-AI interactions. Considered as a sequence of poses of a humanoid, the task can be considered as a sequence generation problem with spatiotemporal smoothness and realism constraints. Additionally, we wish to control the behavior of AI agents by giving them what to do and, more specifically, how to do it. We proposed a spatiotemporally-conditioned GAN that generates a sequence that is similar to a given sequence in terms of semantics and spatiotemporal dynamics. Using LSTM-based generator and graph ConvNet discriminator, this system is trained end-to-end on a large gathered dataset of gestures, expressions, and actions. Experiments showed that compared to traditional conditional GAN, our method creates plausible, realistic, and semantically relevant humanoid animation sequences that match user expectations.