 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Fashion Recommendation and Compatibility Prediction Using Relational Network
May 13, 2020
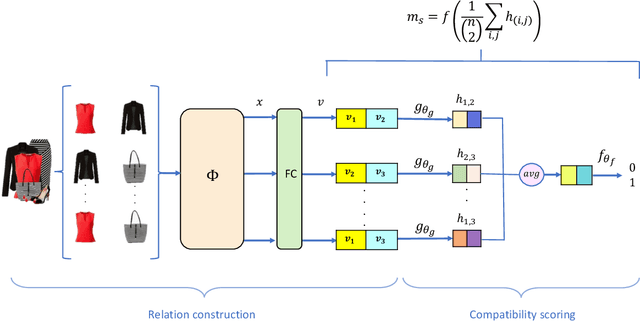
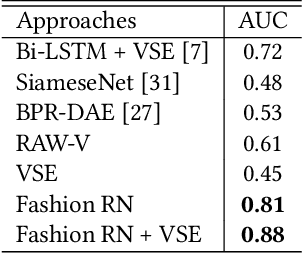
Fashion is an inherently visual concept and computer vision and artificial intelligence (AI) are playing an increasingly important role in shaping the future of this domain. Many research has been done on recommending fashion products based on the learned user preferences. However, in addition to recommending single items, AI can also help users create stylish outfits from items they already have, or purchase additional items that go well with their current wardrobe. Compatibility is the key factor in creating stylish outfits from single items. Previous studies have mostly focused on modeling pair-wise compatibility. There are a few approaches that consider an entire outfit, but these approaches have limitations such as requiring rich semantic information, category labels, and fixed order of items. Thus, they fail to effectively determine compatibility when such information is not available. In this work, we adopt a Relation Network (RN) to develop new compatibility learning models, Fashion RN and FashionRN-VSE, that addresses the limitations of existing approaches. FashionRN learns the compatibility of an entire outfit, with an arbitrary number of items, in an arbitrary order. We evaluated our model using a large dataset of 49,740 outfits that we collected from Polyvore website. Quantitatively, our experimental results demonstrate state of the art performance compared with alternative methods in the literature in both compatibility prediction and fill-in-the-blank test. Qualitatively, we also show that the item embedding learned by FashionRN indicate the compatibility among fashion items.
Exploring Implicit Human Responses to Robot Mistakes in a Learning from Demonstration Task
Jun 08, 2016

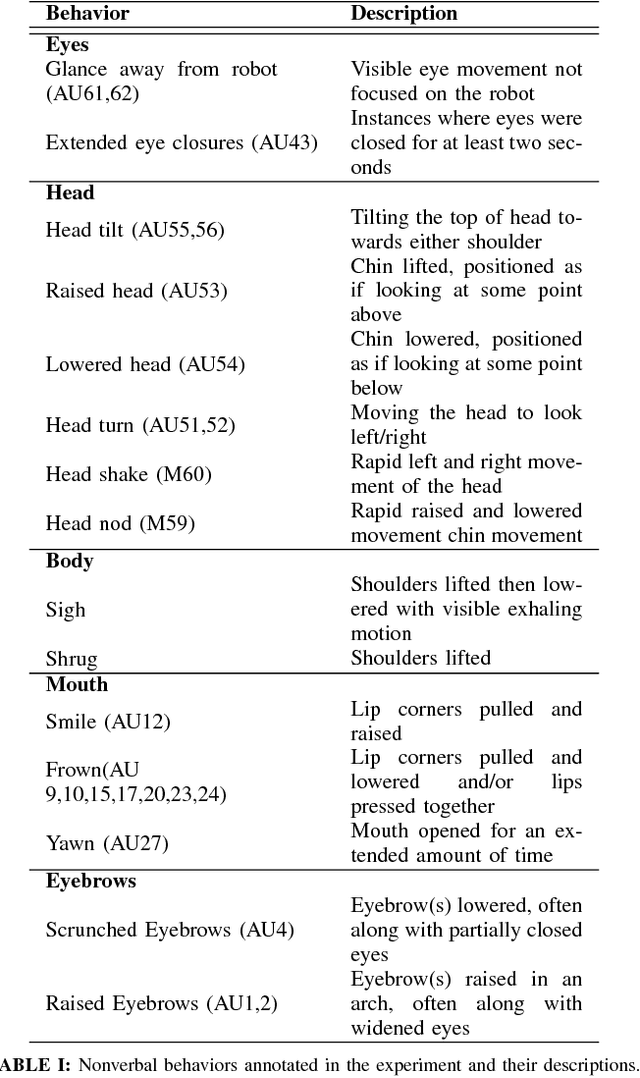
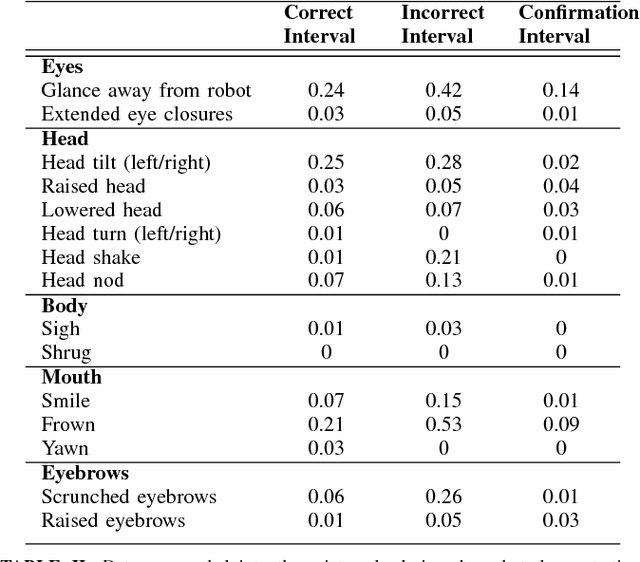
As robots enter human environments, they will be expected to accomplish a tremendous range of tasks. It is not feasible for robot designers to pre-program these behaviors or know them in advance, so one way to address this is through end-user programming, such as via learning from demonstration (LfD). While significant work has been done on the mechanics of enabling robot learning from human teachers, one unexplored aspect is enabling mutual feedback between both the human teacher and robot during the learning process, i.e., implicit learning. In this paper, we explore one aspect of this mutual understanding, grounding sequences, where both a human and robot provide non-verbal feedback to signify their mutual understanding during interaction. We conducted a study where people taught an autonomous humanoid robot a dance, and performed gesture analysis to measure people's responses to the robot during correct and incorrect demonstrations.