 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Implicit Human Responses to Robot Mistakes in a Learning from Demonstration Task
Paper and Code
Jun 08, 2016

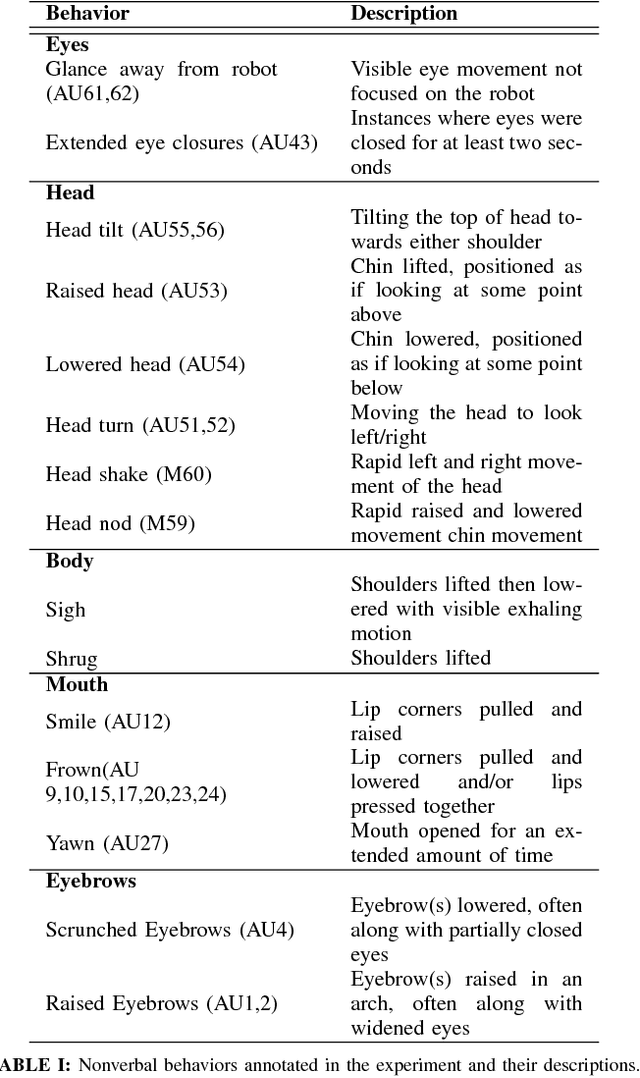
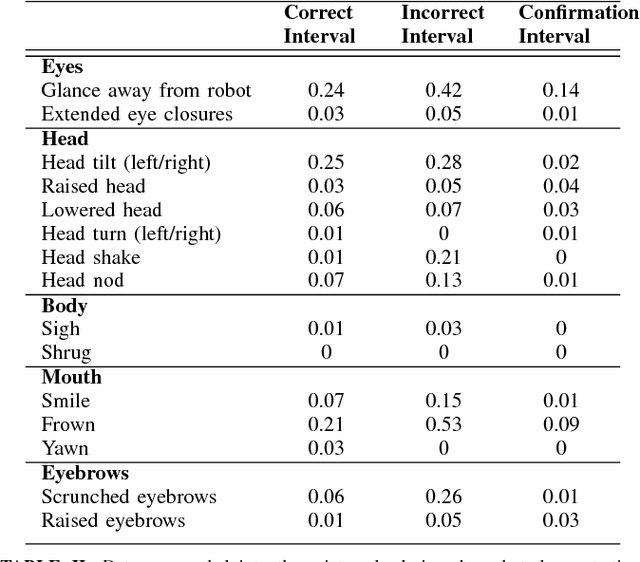
As robots enter human environments, they will be expected to accomplish a tremendous range of tasks. It is not feasible for robot designers to pre-program these behaviors or know them in advance, so one way to address this is through end-user programming, such as via learning from demonstration (LfD). While significant work has been done on the mechanics of enabling robot learning from human teachers, one unexplored aspect is enabling mutual feedback between both the human teacher and robot during the learning process, i.e., implicit learning. In this paper, we explore one aspect of this mutual understanding, grounding sequences, where both a human and robot provide non-verbal feedback to signify their mutual understanding during interaction. We conducted a study where people taught an autonomous humanoid robot a dance, and performed gesture analysis to measure people's responses to the robot during correct and incorrect demonstrations.