 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-based Graph-guided Domain Adaptation for Robust Cross-Session Emotion Recognition
Dec 29, 2025Accurate recognition of human emotional states is critical for effective human-machine interaction. Electroencephalography (EEG) offers a reliable source for emotion recognition due to its high temporal resolution and its direct reflection of neural activity. Nevertheless, variations across recording sessions present a major challenge for model generalization. To address this issue, we propose EGDA, a framework that reduces cross-session discrepancies by jointly aligning the global (marginal) and class-specific (conditional) distributions, while preserving the intrinsic structure of EEG data through graph regularization. Experimental results on the SEED-IV dataset demonstrate that EGDA achieves robust cross-session performance, obtaining accuracies of 81.22%, 80.15%, and 83.27% across three transfer tasks, and surpassing several baseline methods. Furthermore, the analysis highlights the Gamma frequency band as the most discriminative and identifies the central-parietal and prefrontal brain regions as critical for reliable emotion recognition.
From Decision to Action in Surgical Autonomy: Multi-Modal Large Language Models for Robot-Assisted Blood Suction
Aug 14, 2024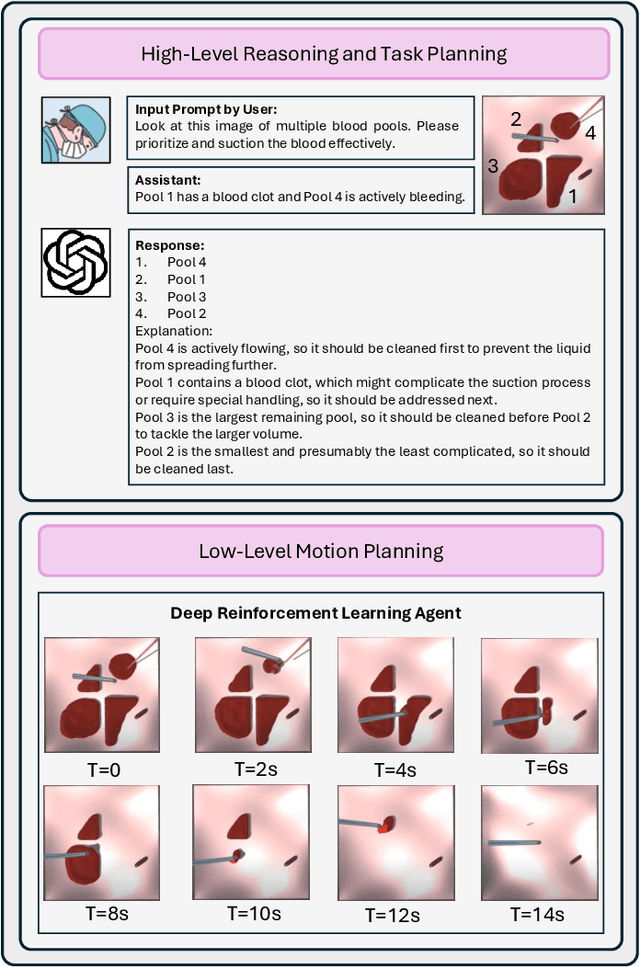
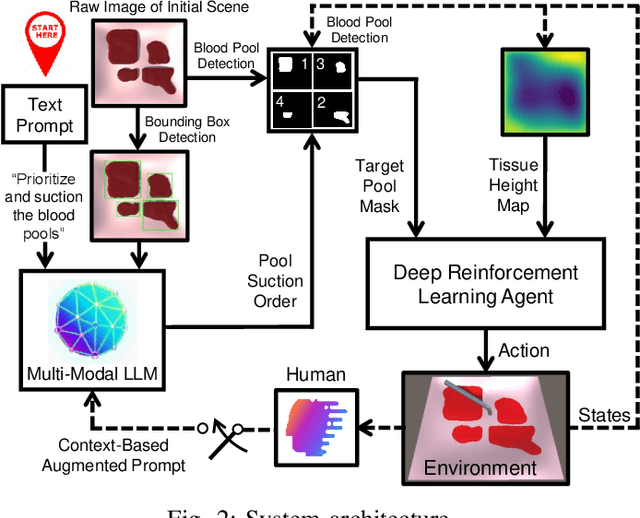
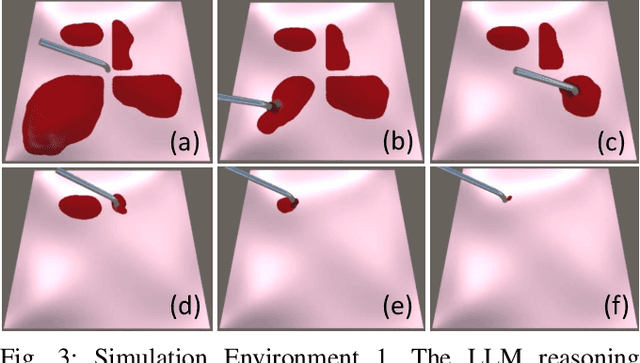

The rise of Large Language Models (LLMs) has impacted research in robotics and automation. While progress has been made in integrating LLMs into general robotics tasks, a noticeable void persists in their adoption in more specific domains such as surgery, where critical factors such as reasoning, explainability, and safety are paramount. Achieving autonomy in robotic surgery, which entails the ability to reason and adapt to changes in the environment, remains a significant challenge. In this work, we propose a multi-modal LLM integration in robot-assisted surgery for autonomous blood suction. The reasoning and prioritization are delegated to the higher-level task-planning LLM, and the motion planning and execution are handled by the lower-level deep reinforcement learning model, creating a distributed agency between the two components. As surgical operations are highly dynamic and may encounter unforeseen circumstances, blood clots and active bleeding were introduced to influence decision-making. Results showed that using a multi-modal LLM as a higher-level reasoning unit can account for these surgical complexities to achieve a level of reasoning previously unattainable in robot-assisted surgeries. These findings demonstrate the potential of multi-modal LLMs to significantly enhance contextual understanding and decision-making in robotic-assisted surgeries, marking a step toward autonomous surgical systems.