 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Spatial Diffusions for Optoacoustic Tomography Image Reconstruction
Nov 08, 2024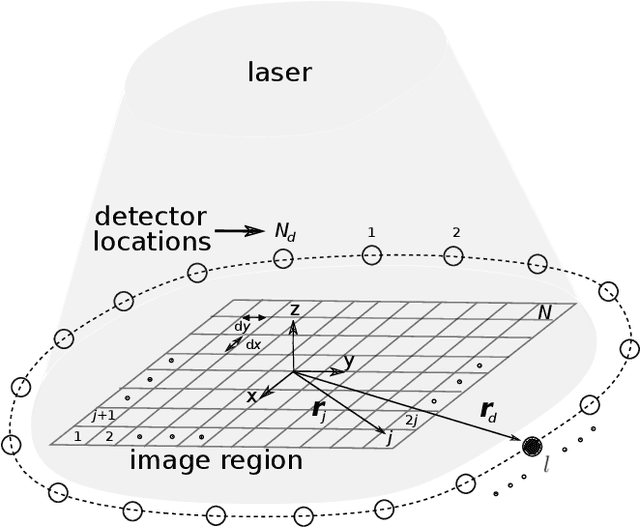
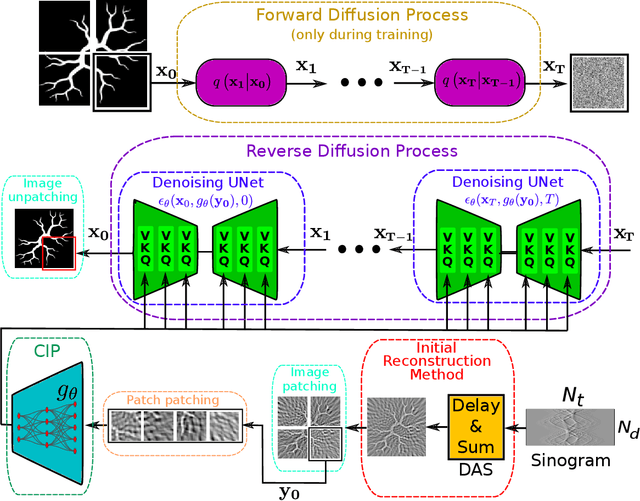
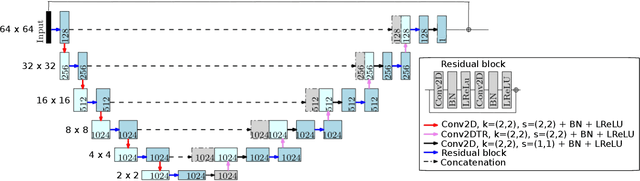
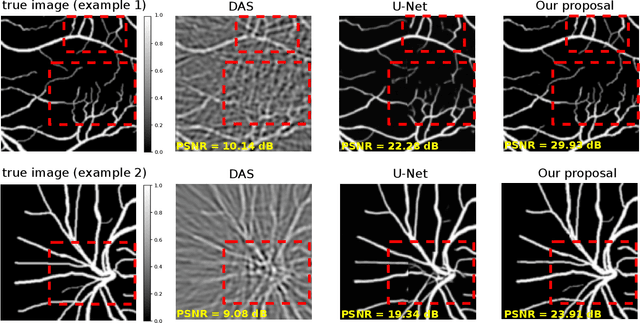
Optoacoustic tomography image reconstruction has been a problem of interest in recent years. By exploiting the exceptional generative power of the recently proposed diffusion models we consider a scheme which is based on a conditional diffusion process. Using a simple initial image reconstruction method such as Delay and Sum, we consider a specially designed autoencoder architecture which generates a latent representation which is used as conditional information in the generative diffusion process. Numerical results show the merits of our proposal in terms of quality metrics such as PSNR and SSIM, showing that the conditional information generated in terms of the initial reconstructed image is able to bias the generative process of the diffusion model in order to enhance the image, correct artifacts and even recover some finer details that the initial reconstruction method is not able to obtain.
Invariant Representations in Deep Learning for Optoacoustic Imaging
Apr 29, 2023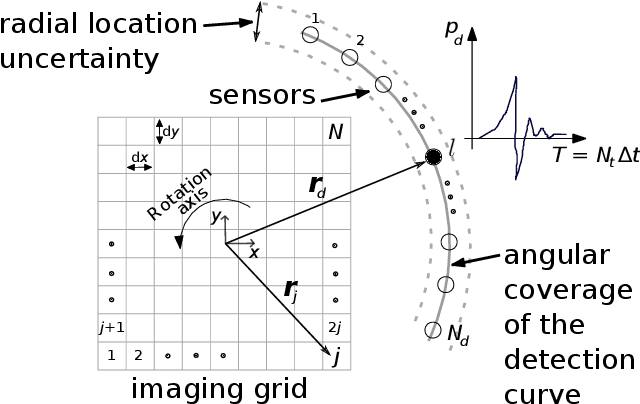
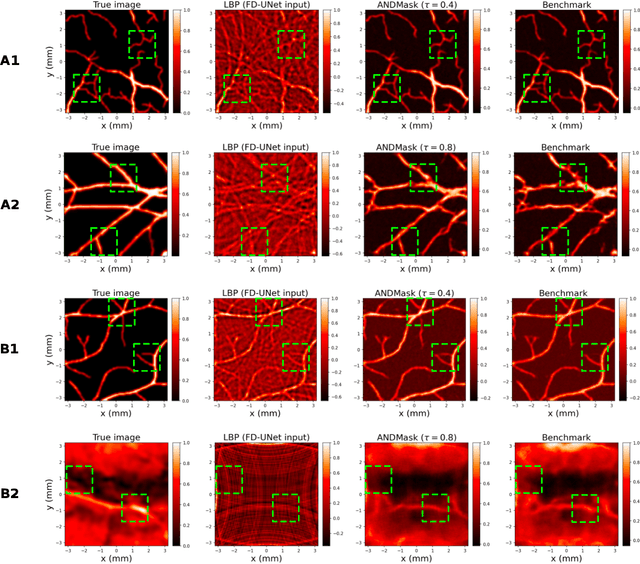


Image reconstruction in optoacoustic tomography (OAT) is a trending learning task highly dependent on measured physical magnitudes present at sensing time. The large number of different settings, and also the presence of uncertainties or partial knowledge of parameters, can lead to reconstructions algorithms that are specifically tailored and designed to a particular configuration which could not be the one that will be ultimately faced in a final practical situation. Being able to learn reconstruction algorithms that are robust to different environments (e.g. the different OAT image reconstruction settings) or invariant to such environments is highly valuable because it allows to focus on what truly matters for the application at hand and discard what are considered spurious features. In this work we explore the use of deep learning algorithms based on learning invariant and robust representations for the OAT inverse problem. In particular, we consider the application of the ANDMask scheme due to its easy adaptation to the OAT problem. Numerical experiments are conducted showing that, when out-of-distribution generalization (against variations in parameters such as the location of the sensors) is imposed, there is no degradation of the performance and, in some cases, it is even possible to achieve improvements with respect to standard deep learning approaches where invariance robustness is not explicitly considered.
Combining band-frequency separation and deep neural networks for optoacoustic imaging
Oct 14, 2022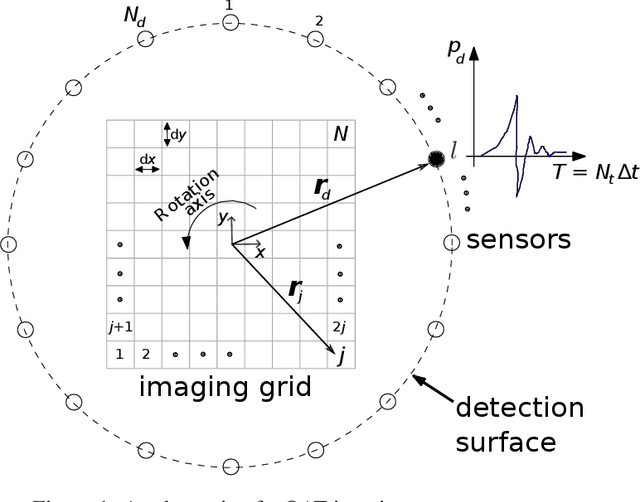
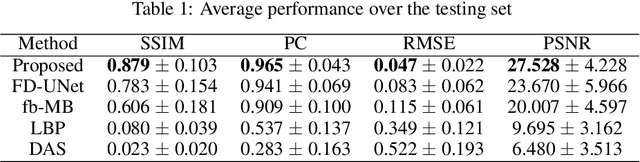
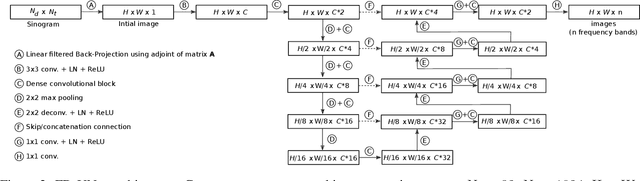
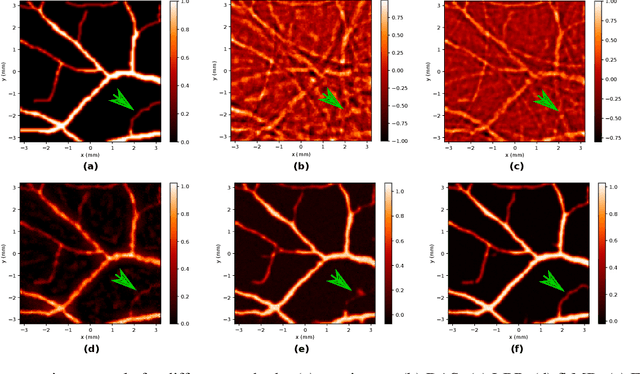
In this paper we consider the problem of image reconstruction in optoacoustic tomography. In particular, we devise a deep neural architecture that can explicitly take into account the band-frequency information contained in the sinogram. This is accomplished by two means. First, we jointly use a linear filtered back-projection method and a fully dense UNet for the generation of the images corresponding to each one of the frequency bands considered in the separation. Secondly, in order to train the model, we introduce a special loss function consisting of three terms: (i) a separating frequency bands term; (ii) a sinogram-based consistency term and (iii) a term that directly measures the quality of image reconstruction and which takes advantage of the presence of ground-truth images present in training dataset. Numerical experiments show that the proposed model, which can be easily trainable by standard optimization methods, presents an excellent generalization performance quantified by a number of metrics commonly used in practice. Also, in the testing phase, our solution has a comparable (in some cases lower) computational complexity, which is a desirable feature for real-time implementation of optoacoustic imaging.