 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Spatial Diffusions for Optoacoustic Tomography Image Reconstruction
Paper and Code
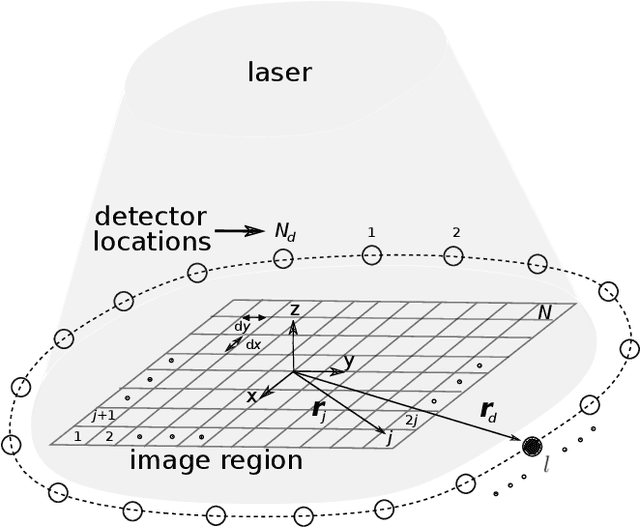
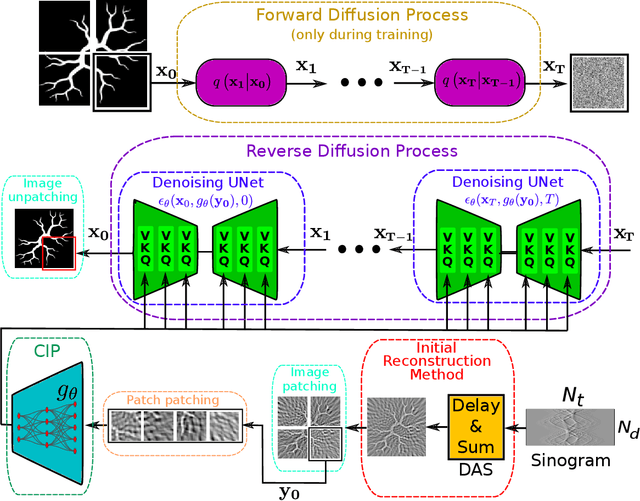
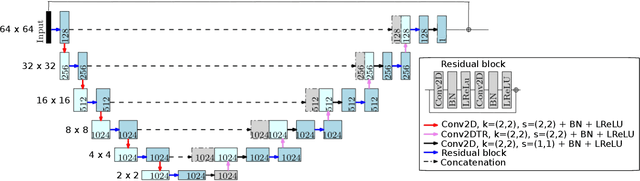
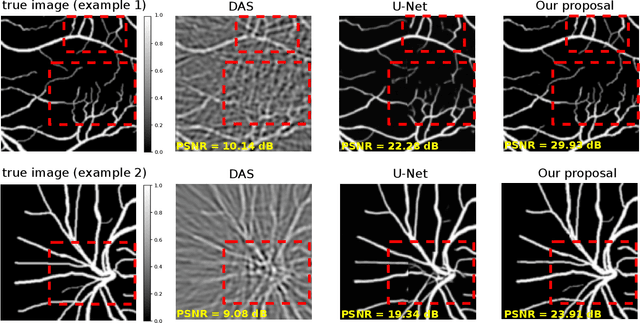
Optoacoustic tomography image reconstruction has been a problem of interest in recent years. By exploiting the exceptional generative power of the recently proposed diffusion models we consider a scheme which is based on a conditional diffusion process. Using a simple initial image reconstruction method such as Delay and Sum, we consider a specially designed autoencoder architecture which generates a latent representation which is used as conditional information in the generative diffusion process. Numerical results show the merits of our proposal in terms of quality metrics such as PSNR and SSIM, showing that the conditional information generated in terms of the initial reconstructed image is able to bias the generative process of the diffusion model in order to enhance the image, correct artifacts and even recover some finer details that the initial reconstruction method is not able to obtain.