 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnboxing Tree Ensembles for interpretability: a hierarchical visualization tool and a multivariate optimal re-built tree
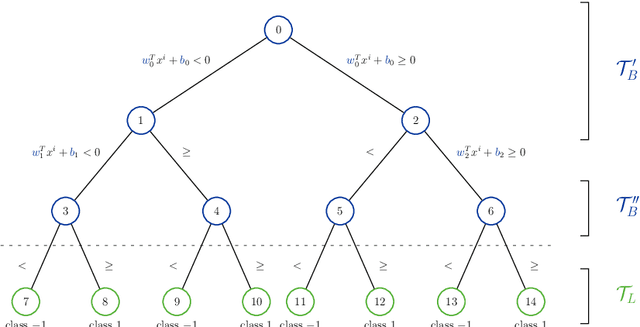
Feb 15, 2023The interpretability of models has become a crucial issue in Machine Learning because of algorithmic decisions' growing impact on real-world applications. Tree ensemble methods, such as Random Forests or XgBoost, are powerful learning tools for classification tasks. However, while combining multiple trees may provide higher prediction quality than a single one, it sacrifices the interpretability property resulting in "black-box" models. In light of this, we aim to develop an interpretable representation of a tree-ensemble model that can provide valuable insights into its behavior. First, given a target tree-ensemble model, we develop a hierarchical visualization tool based on a heatmap representation of the forest's feature use, considering the frequency of a feature and the level at which it is selected as an indicator of importance. Next, we propose a mixed-integer linear programming (MILP) formulation for constructing a single optimal multivariate tree that accurately mimics the target model predictions. The goal is to provide an interpretable surrogate model based on oblique hyperplane splits, which uses only the most relevant features according to the defined forest's importance indicators. The MILP model includes a penalty on feature selection based on their frequency in the forest to further induce sparsity of the splits. The natural formulation has been strengthened to improve the computational performance of mixed-integer software. Computational experience is carried out on benchmark datasets from the UCI repository using a state-of-the-art off-the-shelf solver. Results show that the proposed model is effective in yielding a shallow interpretable tree approximating the tree-ensemble decision function.
Margin Optimal Classification Trees
Oct 19, 2022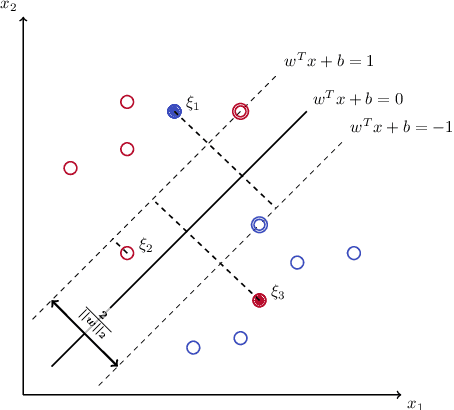

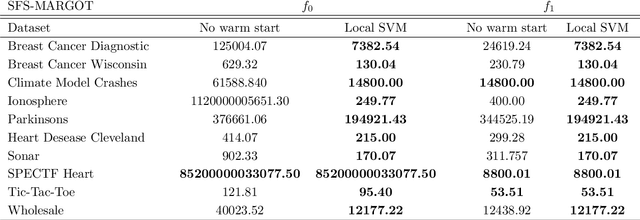
In recent years there has been growing attention to interpretable machine learning models which can give explanatory insights on their behavior. Thanks to their interpretability, decision trees have been intensively studied for classification tasks, and due to the remarkable advances in mixed-integer programming (MIP), various approaches have been proposed to formulate the problem of training an Optimal Classification Tree (OCT) as a MIP model. We present a novel mixed-integer quadratic formulation for the OCT problem, which exploits the generalization capabilities of Support Vector Machines for binary classification. Our model, denoted as Margin Optimal Classification Tree (MARGOT), encompasses the use of maximum margin multivariate hyperplanes nested in a binary tree structure. To enhance the interpretability of our approach, we analyse two alternative versions of MARGOT, which include feature selection constraints inducing local sparsity of the hyperplanes. First, MARGOT has been tested on non-linearly separable synthetic datasets in 2-dimensional feature space to provide a graphical representation of the maximum margin approach. Finally, the proposed models have been tested on benchmark datasets from the UCI repository. The MARGOT formulation turns out to be easier to solve than other OCT approaches, and the generated tree better generalizes on new observations. The two interpretable versions are effective in selecting the most relevant features and maintaining good prediction quality.
An actor-critic algorithm with deep double recurrent agents to solve the job shop scheduling problem
Oct 18, 2021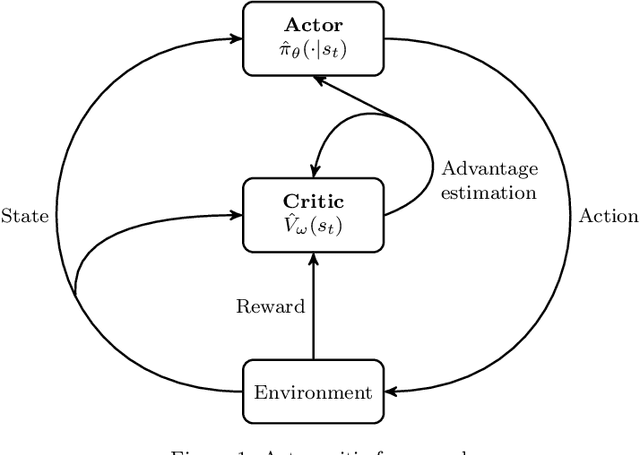
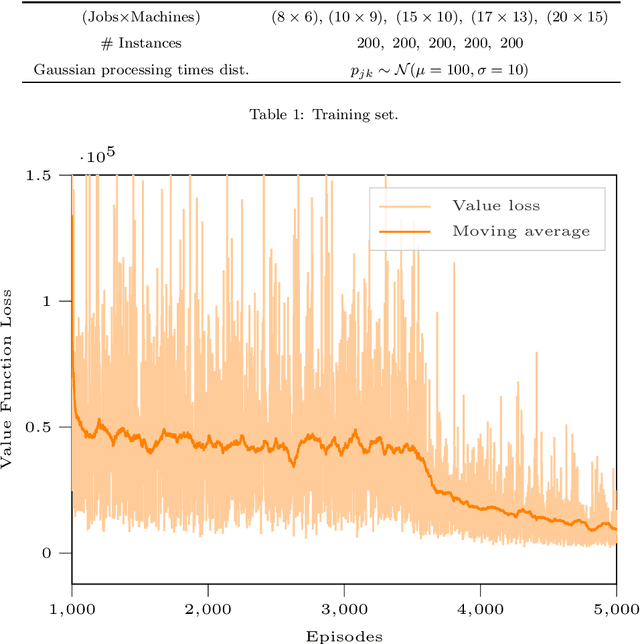
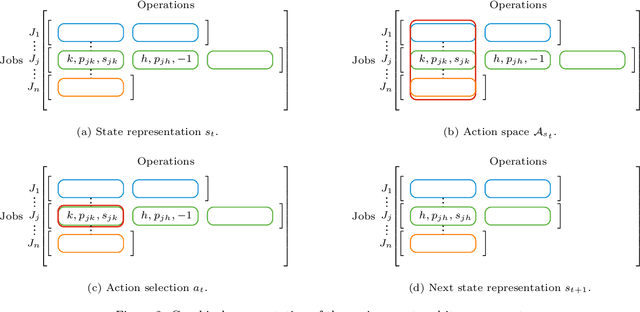

There is a growing interest in integrating machine learning techniques and optimization to solve challenging optimization problems. In this work, we propose a deep reinforcement learning methodology for the job shop scheduling problem (JSSP). The aim is to build up a greedy-like heuristic able to learn on some distribution of JSSP instances, different in the number of jobs and machines. The need for fast scheduling methods is well known, and it arises in many areas, from transportation to healthcare. We model the JSSP as a Markov Decision Process and then we exploit the efficacy of reinforcement learning to solve the problem. We adopt an actor-critic scheme, where the action taken by the agent is influenced by policy considerations on the state-value function. The procedures are adapted to take into account the challenging nature of JSSP, where the state and the action space change not only for every instance but also after each decision. To tackle the variability in the number of jobs and operations in the input, we modeled the agent using two incident LSTM models, a special type of deep neural network. Experiments show the algorithm reaches good solutions in a short time, proving that is possible to generate new greedy heuristics just from learning-based methodologies. Benchmarks have been generated in comparison with the commercial solver CPLEX. As expected, the model can generalize, to some extent, to larger problems or instances originated by a different distribution from the one used in training.