 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUSH: a primal heuristic based on Feasibility PUmp and SHifting
Jul 30, 2022

This work describes PUSH, a primal heuristic combining Feasibility Pump and Shifting. The main idea is to replace the rounding phase of the Feasibility Pump with a suitable adaptation of the Shifting and other rounding heuristics. The algorithm presents different strategies, depending on the nature of the partial rounding obtained. In particular, we distinguish when the partial solution is feasible, infeasible with potential candidates, and infeasible without candidates. We used a threshold to indicate the percentage of variables to round with our algorithm and which other to round to the nearest integer. Most importantly, our algorithm tackles directly equality constraints without duplicating rows. We select the parameters of our algorithm on the 19 instances provided for the Mip Competition 2022. Finally, we compared our approach to other start heuristics, like Simple Rounding, Rounding, Shifting, and Feasibility Pump on the first 800 MIPLIB2017 instances ordered by the number of non-zeros.
An actor-critic algorithm with deep double recurrent agents to solve the job shop scheduling problem
Oct 18, 2021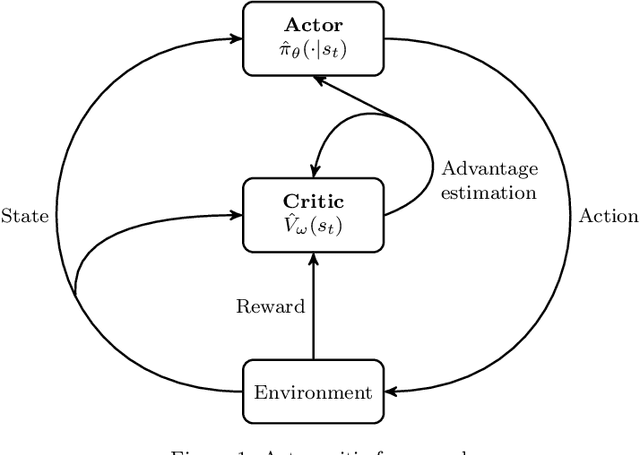
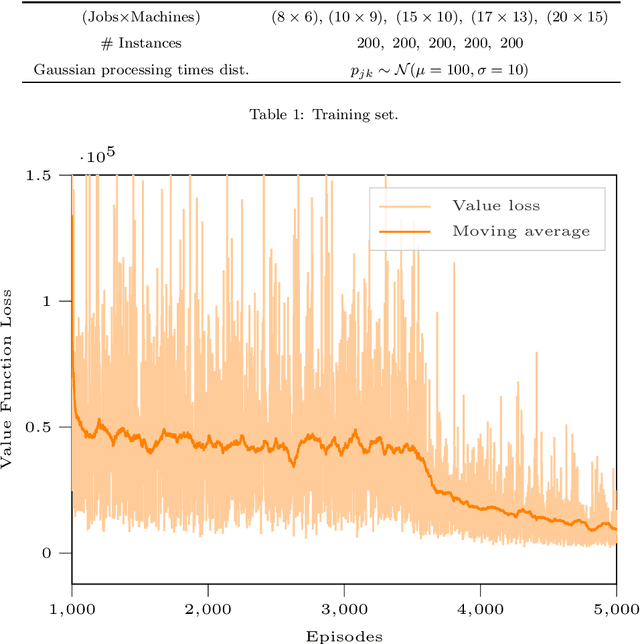
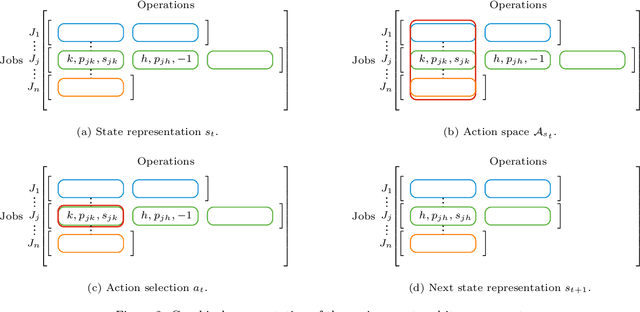

There is a growing interest in integrating machine learning techniques and optimization to solve challenging optimization problems. In this work, we propose a deep reinforcement learning methodology for the job shop scheduling problem (JSSP). The aim is to build up a greedy-like heuristic able to learn on some distribution of JSSP instances, different in the number of jobs and machines. The need for fast scheduling methods is well known, and it arises in many areas, from transportation to healthcare. We model the JSSP as a Markov Decision Process and then we exploit the efficacy of reinforcement learning to solve the problem. We adopt an actor-critic scheme, where the action taken by the agent is influenced by policy considerations on the state-value function. The procedures are adapted to take into account the challenging nature of JSSP, where the state and the action space change not only for every instance but also after each decision. To tackle the variability in the number of jobs and operations in the input, we modeled the agent using two incident LSTM models, a special type of deep neural network. Experiments show the algorithm reaches good solutions in a short time, proving that is possible to generate new greedy heuristics just from learning-based methodologies. Benchmarks have been generated in comparison with the commercial solver CPLEX. As expected, the model can generalize, to some extent, to larger problems or instances originated by a different distribution from the one used in training.
Solving the single-track train scheduling problem via Deep Reinforcement Learning
Sep 01, 2020
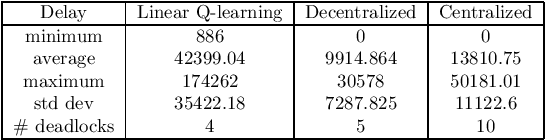


Every day, railways experience small inconveniences, both on the network and the fleet side, affecting the stability of rail traffic. When a disruption occurs, delays propagate through the network, resulting in demand mismatching and, in the long run, demand loss. When a critical situation arises, human dispatchers distributed over the line have the duty to do their best to minimize the impact of the disruptions. Unfortunately, human operators have a limited depth of perception of how what happens in distant areas of the network may affect their control zone. In recent years, decision science has focused on developing methods to solve the problem automatically, to improve the capabilities of human operators. In this paper, machine learning-based methods are investigated when dealing with the train dispatching problem. In particular, two different Deep Q-Learning methods are proposed. Numerical results show the superiority of these techniques respect to the classical linear Q-Learning based on matrices.