 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Fold'em: How to answer Unanswerable questions
May 01, 2021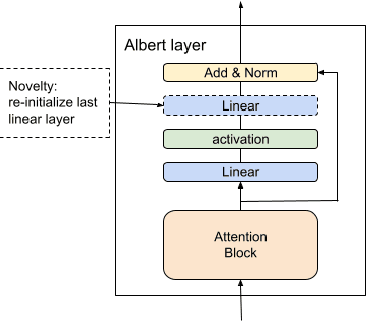
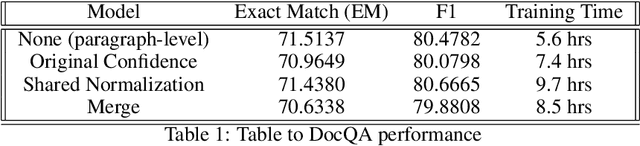
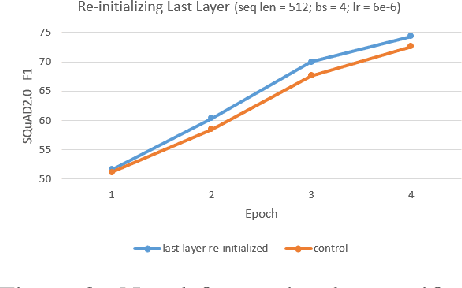

We present 3 different question-answering models trained on the SQuAD2.0 dataset -- BIDAF, DocumentQA and ALBERT Retro-Reader -- demonstrating the improvement of language models in the past three years. Through our research in fine-tuning pre-trained models for question-answering, we developed a novel approach capable of achieving a 2% point improvement in SQuAD2.0 F1 in reduced training time. Our method of re-initializing select layers of a parameter-shared language model is simple yet empirically powerful.
Spoiler Alert: Using Natural Language Processing to Detect Spoilers in Book Reviews
Feb 07, 2021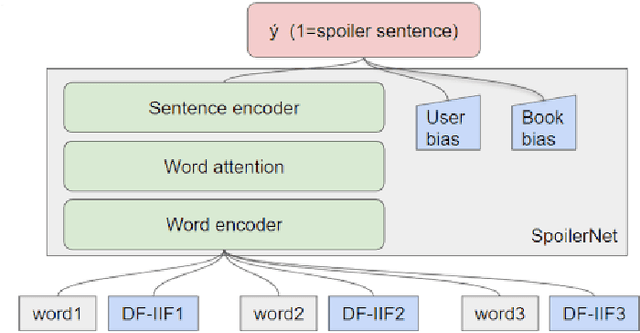
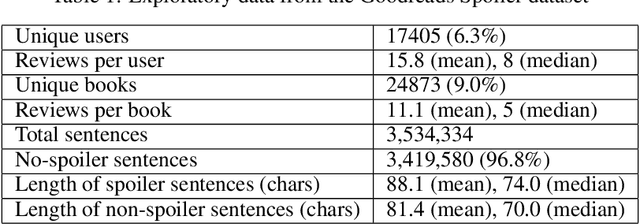
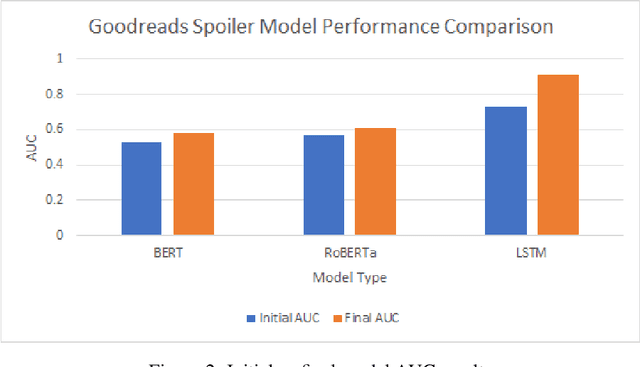
This paper presents an NLP (Natural Language Processing) approach to detecting spoilers in book reviews, using the University of California San Diego (UCSD) Goodreads Spoiler dataset. We explored the use of LSTM, BERT, and RoBERTa language models to perform spoiler detection at the sentence-level. This was contrasted with a UCSD paper which performed the same task, but using handcrafted features in its data preparation. Despite eschewing the use of handcrafted features, our results from the LSTM model were able to slightly exceed the UCSD team's performance in spoiler detection.