Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoiler Alert: Using Natural Language Processing to Detect Spoilers in Book Reviews
Paper and Code
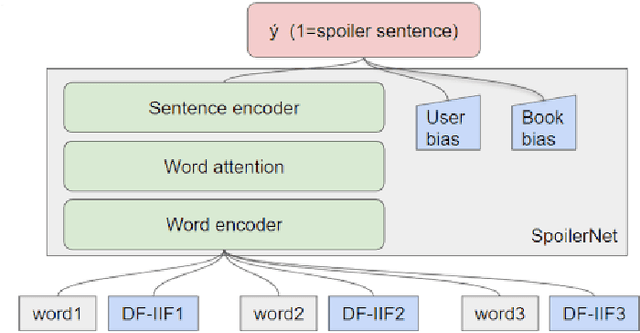
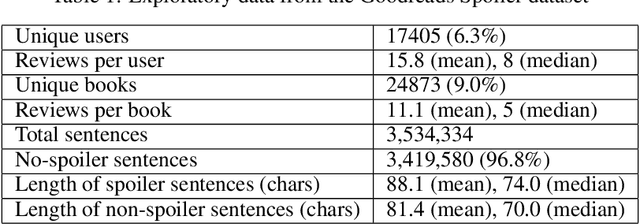
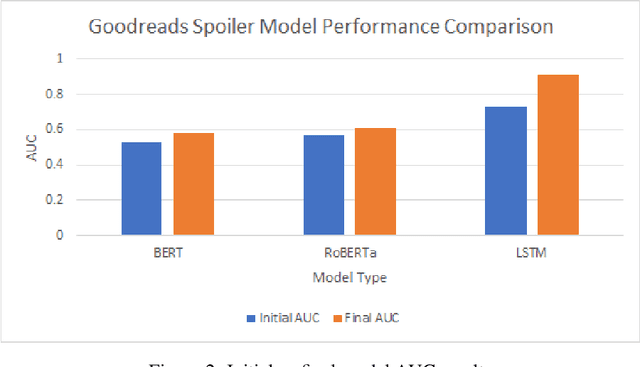
This paper presents an NLP (Natural Language Processing) approach to detecting spoilers in book reviews, using the University of California San Diego (UCSD) Goodreads Spoiler dataset. We explored the use of LSTM, BERT, and RoBERTa language models to perform spoiler detection at the sentence-level. This was contrasted with a UCSD paper which performed the same task, but using handcrafted features in its data preparation. Despite eschewing the use of handcrafted features, our results from the LSTM model were able to slightly exceed the UCSD team's performance in spoiler detection.
View paper on