Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Fold'em: How to answer Unanswerable questions
Paper and Code
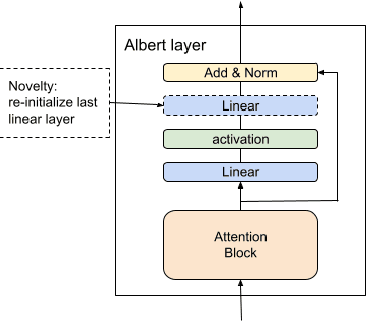
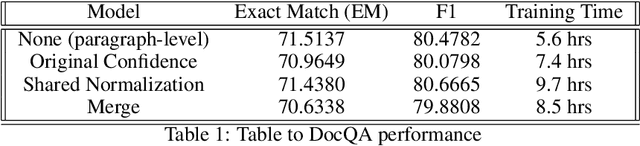
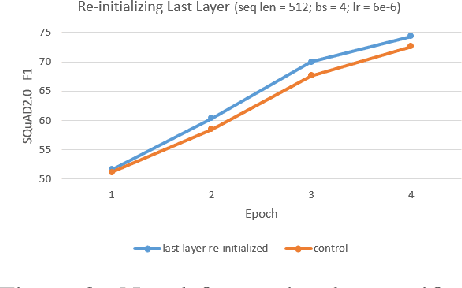

We present 3 different question-answering models trained on the SQuAD2.0 dataset -- BIDAF, DocumentQA and ALBERT Retro-Reader -- demonstrating the improvement of language models in the past three years. Through our research in fine-tuning pre-trained models for question-answering, we developed a novel approach capable of achieving a 2% point improvement in SQuAD2.0 F1 in reduced training time. Our method of re-initializing select layers of a parameter-shared language model is simple yet empirically powerful.
View paper on