 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Position Bias of Transformer Models in Passage Re-Ranking
Jan 18, 2021
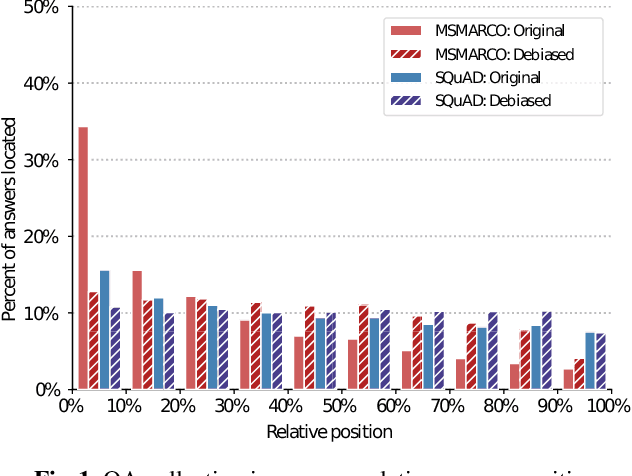


Supervised machine learning models and their evaluation strongly depends on the quality of the underlying dataset. When we search for a relevant piece of information it may appear anywhere in a given passage. However, we observe a bias in the position of the correct answer in the text in two popular Question Answering datasets used for passage re-ranking. The excessive favoring of earlier positions inside passages is an unwanted artefact. This leads to three common Transformer-based re-ranking models to ignore relevant parts in unseen passages. More concerningly, as the evaluation set is taken from the same biased distribution, the models overfitting to that bias overestimate their true effectiveness. In this work we analyze position bias on datasets, the contextualized representations, and their effect on retrieval results. We propose a debiasing method for retrieval datasets. Our results show that a model trained on a position-biased dataset exhibits a significant decrease in re-ranking effectiveness when evaluated on a debiased dataset. We demonstrate that by mitigating the position bias, Transformer-based re-ranking models are equally effective on a biased and debiased dataset, as well as more effective in a transfer-learning setting between two differently biased datasets.
Fine-Grained Relevance Annotations for Multi-Task Document Ranking and Question Answering
Aug 12, 2020
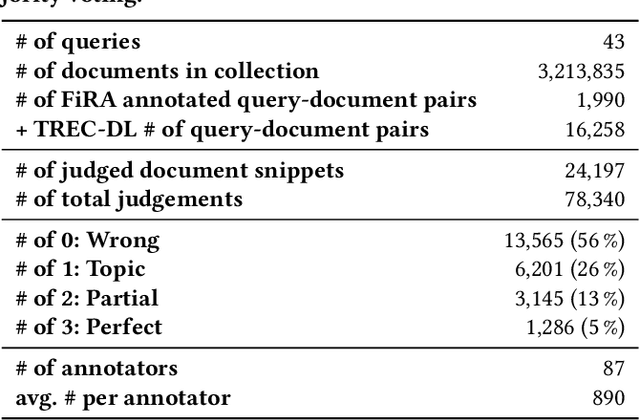
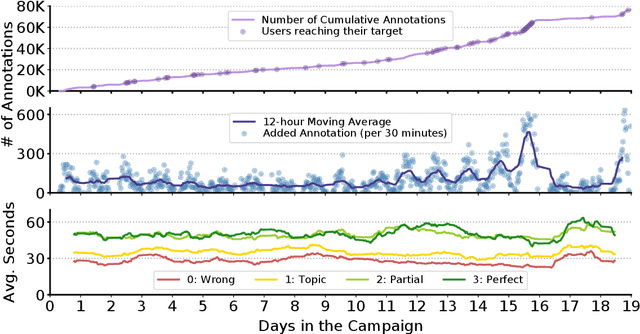

There are many existing retrieval and question answering datasets. However, most of them either focus on ranked list evaluation or single-candidate question answering. This divide makes it challenging to properly evaluate approaches concerned with ranking documents and providing snippets or answers for a given query. In this work, we present FiRA: a novel dataset of Fine-Grained Relevance Annotations. We extend the ranked retrieval annotations of the Deep Learning track of TREC 2019 with passage and word level graded relevance annotations for all relevant documents. We use our newly created data to study the distribution of relevance in long documents, as well as the attention of annotators to specific positions of the text. As an example, we evaluate the recently introduced TKL document ranking model. We find that although TKL exhibits state-of-the-art retrieval results for long documents, it misses many relevant passages.
TU Wien @ TREC Deep Learning '19 -- Simple Contextualization for Re-ranking
Dec 03, 2019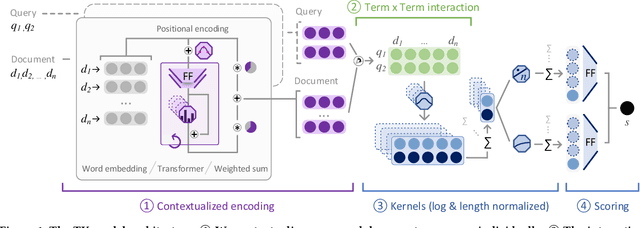

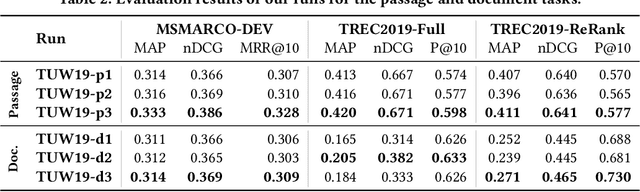

The usage of neural network models puts multiple objectives in conflict with each other: Ideally we would like to create a neural model that is effective, efficient, and interpretable at the same time. However, in most instances we have to choose which property is most important to us. We used the opportunity of the TREC 2019 Deep Learning track to evaluate the effectiveness of a balanced neural re-ranking approach. We submitted results of the TK (Transformer-Kernel) model: a neural re-ranking model for ad-hoc search using an efficient contextualization mechanism. TK employs a very small number of lightweight Transformer layers to contextualize query and document word embeddings. To score individual term interactions, we use a document-length enhanced kernel-pooling, which enables users to gain insight into the model. Our best result for the passage ranking task is: 0.420 MAP, 0.671 nDCG, 0.598 P@10 (TUW19-p3 full). Our best result for the document ranking task is: 0.271 MAP, 0.465 nDCG, 0.730 P@10 (TUW19-d3 re-ranking).