 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplex model of mental lexicon reveals explosive learning in humans
Jan 22, 2018



Word similarities affect language acquisition and use in a multi-relational way barely accounted for in the literature. We propose a multiplex network representation of this mental lexicon of word similarities as a natural framework for investigating large-scale cognitive patterns. Our representation accounts for semantic, taxonomic, and phonological interactions and it identifies a cluster of words which are used with greater frequency, are identified, memorised, and learned more easily, and have more meanings than expected at random. This cluster emerges around age 7 through an explosive transition not reproduced by null models. We relate this explosive emergence to polysemy -- redundancy in word meanings. Results indicate that the word cluster acts as a core for the lexicon, increasing both lexical navigability and robustness to linguistic degradation. Our findings provide quantitative confirmation of existing conjectures about core structure in the mental lexicon and the importance of integrating multi-relational word-word interactions in psycholinguistic frameworks.
Multiplex lexical networks reveal patterns in early word acquisition in children
May 26, 2017

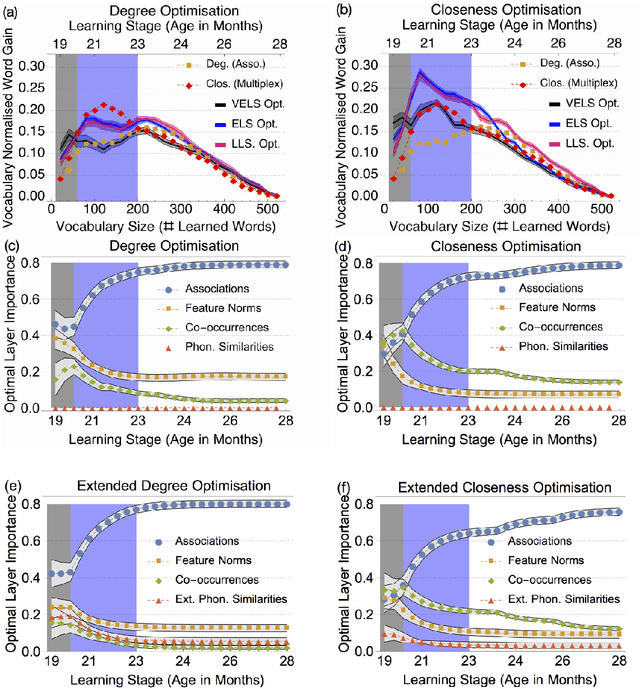

Network models of language have provided a way of linking cognitive processes to the structure and connectivity of language. However, one shortcoming of current approaches is focusing on only one type of linguistic relationship at a time, missing the complex multi-relational nature of language. In this work, we overcome this limitation by modelling the mental lexicon of English-speaking toddlers as a multiplex lexical network, i.e. a multi-layered network where N=529 words/nodes are connected according to four types of relationships: (i) free associations, (ii) feature sharing, (iii) co-occurrence, and (iv) phonological similarity. We provide analysis of the topology of the resulting multiplex and then proceed to evaluate single layers as well as the full multiplex structure on their ability to predict empirically observed age of acquisition data of English speaking toddlers. We find that the emerging multiplex network topology is an important proxy of the cognitive processes of acquisition, capable of capturing emergent lexicon structure. In fact, we show that the multiplex topology is fundamentally more powerful than individual layers in predicting the ordering with which words are acquired. Furthermore, multiplex analysis allows for a quantification of distinct phases of lexical acquisition in early learners: while initially all the multiplex layers contribute to word learning, after about month 23 free associations take the lead in driving word acquisition.
* 11 pages, 3 figures and 1 table. This paper was published on Scientific Reports: https://www.nature.com/articles/srep46730
Mental Lexicon Growth Modelling Reveals the Multiplexity of the English Language
Apr 05, 2016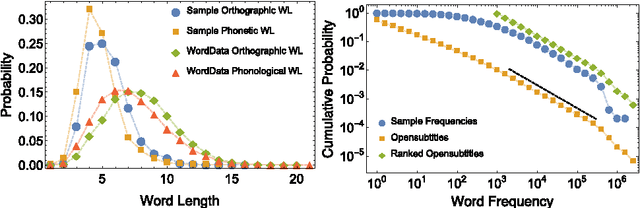

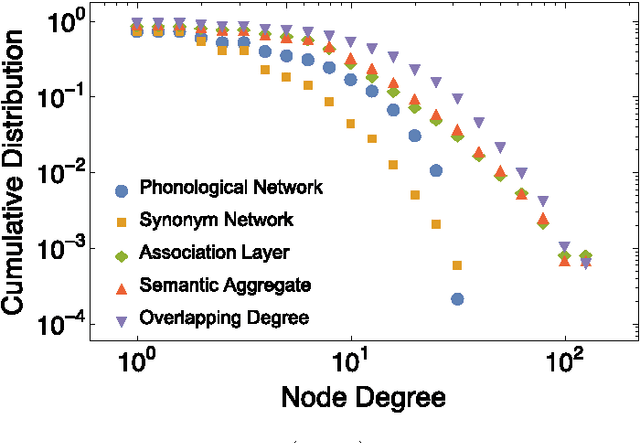
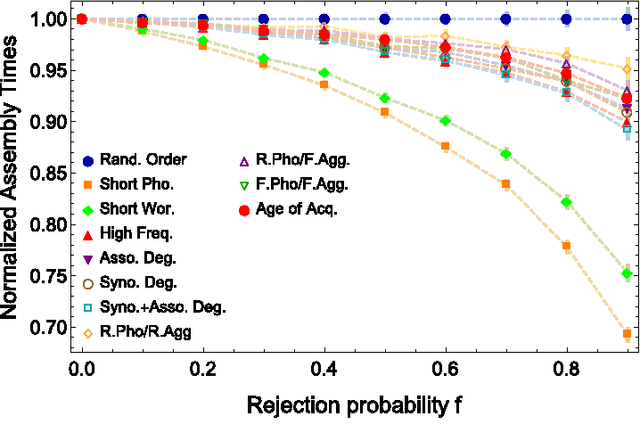
In this work we extend previous analyses of linguistic networks by adopting a multi-layer network framework for modelling the human mental lexicon, i.e. an abstract mental repository where words and concepts are stored together with their linguistic patterns. Across a three-layer linguistic multiplex, we model English words as nodes and connect them according to (i) phonological similarities, (ii) synonym relationships and (iii) free word associations. Our main aim is to exploit this multi-layered structure to explore the influence of phonological and semantic relationships on lexicon assembly over time. We propose a model of lexicon growth which is driven by the phonological layer: words are suggested according to different orderings of insertion (e.g. shorter word length, highest frequency, semantic multiplex features) and accepted or rejected subject to constraints. We then measure times of network assembly and compare these to empirical data about the age of acquisition of words. In agreement with empirical studies in psycholinguistics, our results provide quantitative evidence for the hypothesis that word acquisition is driven by features at multiple levels of organisation within language.
Patterns in the English Language: Phonological Networks, Percolation and Assembly Models
Mar 23, 2015


In this paper we provide a quantitative framework for the study of phonological networks (PNs) for the English language by carrying out principled comparisons to null models, either based on site percolation, randomization techniques, or network growth models. In contrast to previous work, we mainly focus on null models that reproduce lower order characteristics of the empirical data. We find that artificial networks matching connectivity properties of the English PN are exceedingly rare: this leads to the hypothesis that the word repertoire might have been assembled over time by preferentially introducing new words which are small modifications of old words. Our null models are able to explain the "power-law-like" part of the degree distributions and generally retrieve qualitative features of the PN such as high clustering, high assortativity coefficient, and small-world characteristics. However, the detailed comparison to expectations from null models also points out significant differences, suggesting the presence of additional constraints in word assembly. Key constraints we identify are the avoidance of large degrees, the avoidance of triadic closure, and the avoidance of large non-percolating clusters.