 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatterns in the English Language: Phonological Networks, Percolation and Assembly Models
Paper and Code
Mar 23, 2015


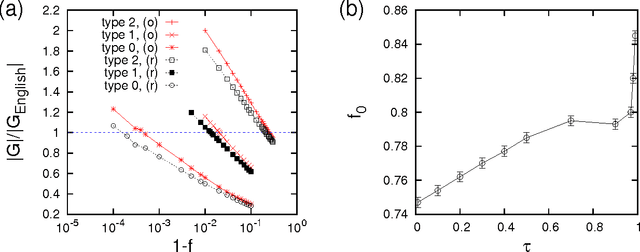
In this paper we provide a quantitative framework for the study of phonological networks (PNs) for the English language by carrying out principled comparisons to null models, either based on site percolation, randomization techniques, or network growth models. In contrast to previous work, we mainly focus on null models that reproduce lower order characteristics of the empirical data. We find that artificial networks matching connectivity properties of the English PN are exceedingly rare: this leads to the hypothesis that the word repertoire might have been assembled over time by preferentially introducing new words which are small modifications of old words. Our null models are able to explain the "power-law-like" part of the degree distributions and generally retrieve qualitative features of the PN such as high clustering, high assortativity coefficient, and small-world characteristics. However, the detailed comparison to expectations from null models also points out significant differences, suggesting the presence of additional constraints in word assembly. Key constraints we identify are the avoidance of large degrees, the avoidance of triadic closure, and the avoidance of large non-percolating clusters.