 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Sweep: an improved, binary quantifier
Aug 16, 2023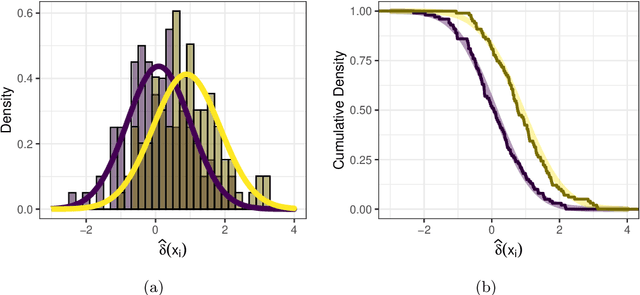
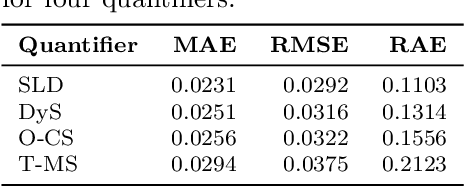
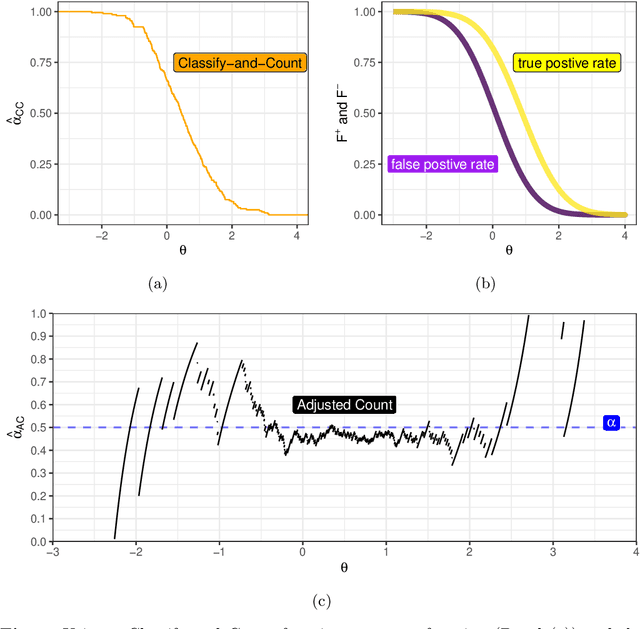
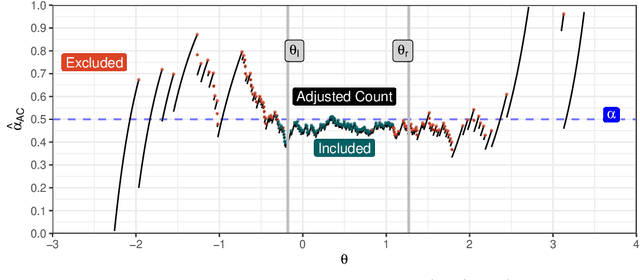
Quantification is a supervised machine learning task, focused on estimating the class prevalence of a dataset rather than labeling its individual observations. We introduce Continuous Sweep, a new parametric binary quantifier inspired by the well-performing Median Sweep. Median Sweep is currently one of the best binary quantifiers, but we have changed this quantifier on three points, namely 1) using parametric class distributions instead of empirical distributions, 2) optimizing decision boundaries instead of applying discrete decision rules, and 3) calculating the mean instead of the median. We derive analytic expressions for the bias and variance of Continuous Sweep under general model assumptions. This is one of the first theoretical contributions in the field of quantification learning. Moreover, these derivations enable us to find the optimal decision boundaries. Finally, our simulation study shows that Continuous Sweep outperforms Median Sweep in a wide range of situations.
Imputation of missing values in multi-view data
Oct 26, 2022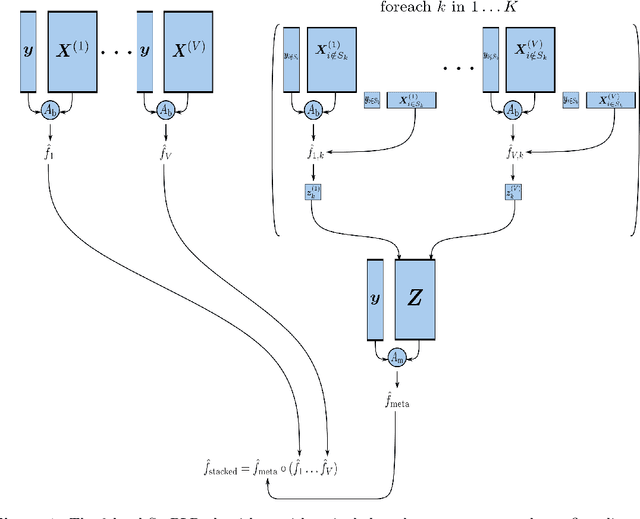
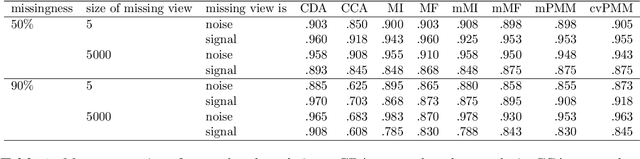
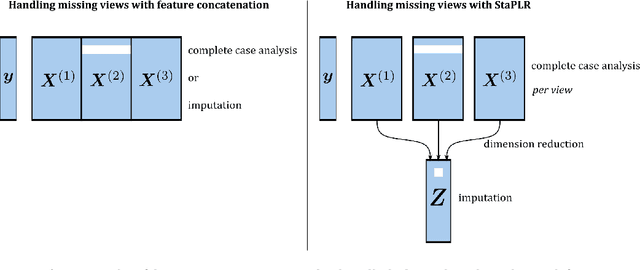
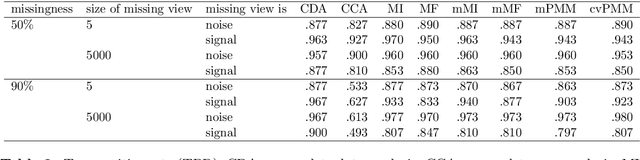
When missing values occur in multi-view data, all features in a view are likely to be missing simultaneously. This leads to very large quantities of missing data which, especially when combined with high-dimensionality, makes the application of conditional imputation methods computationally infeasible. We introduce a new meta-learning imputation method based on stacked penalized logistic regression (StaPLR), which performs imputation in a dimension-reduced space. We evaluate the new imputation method with several imputation algorithms using simulations. The results show that meta-level imputation of missing values leads to good results at a much lower computational cost, and makes the use of advanced imputation algorithms such as missForest and predictive mean matching possible in settings where they would otherwise be computationally infeasible.
Analyzing hierarchical multi-view MRI data with StaPLR: An application to Alzheimer's disease classification
Aug 12, 2021
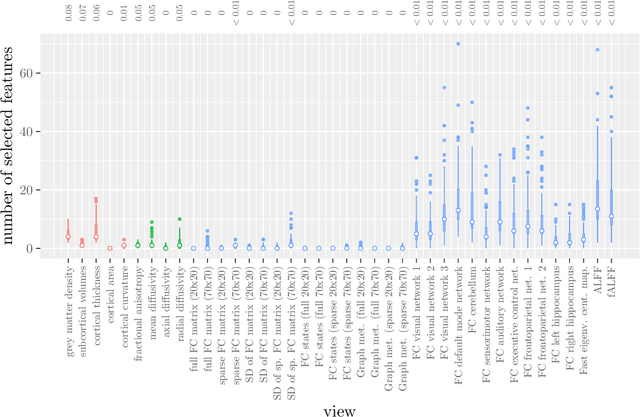
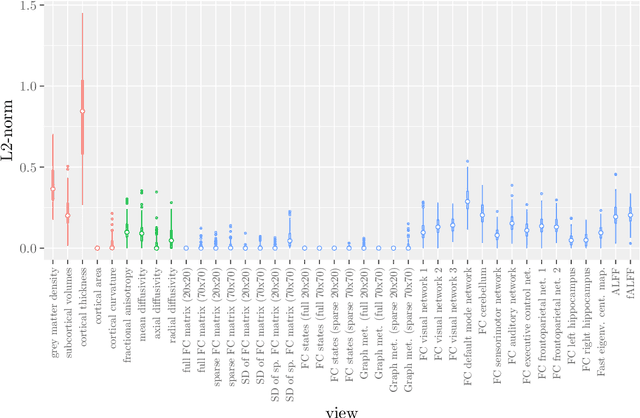
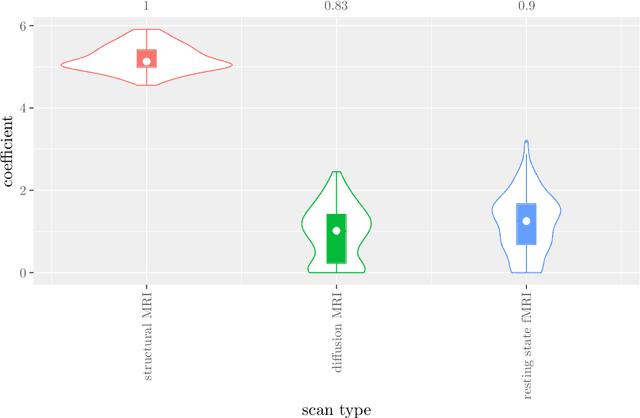
Multi-view data refers to a setting where features are divided into feature sets, for example because they correspond to different sources. Stacked penalized logistic regression (StaPLR) is a recently introduced method that can be used for classification and automatically selecting the views that are most important for prediction. We show how this method can easily be extended to a setting where the data has a hierarchical multi-view structure. We apply StaPLR to Alzheimer's disease classification where different MRI measures have been calculated from three scan types: structural MRI, diffusion-weighted MRI, and resting-state fMRI. StaPLR can identify which scan types and which MRI measures are most important for classification, and it outperforms elastic net regression in classification performance.
The MELODIC family for simultaneous binary logistic regression in a reduced space
Feb 16, 2021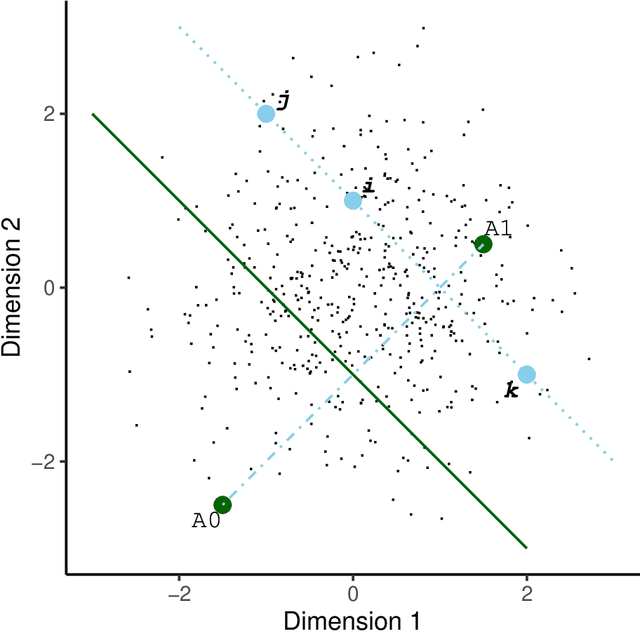
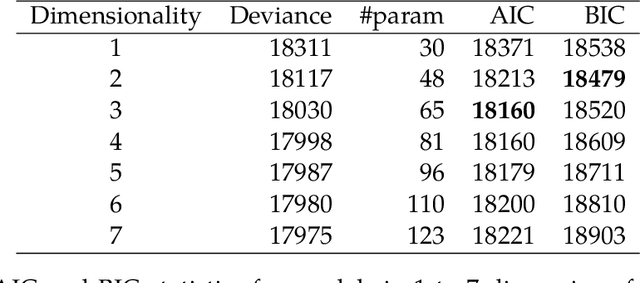
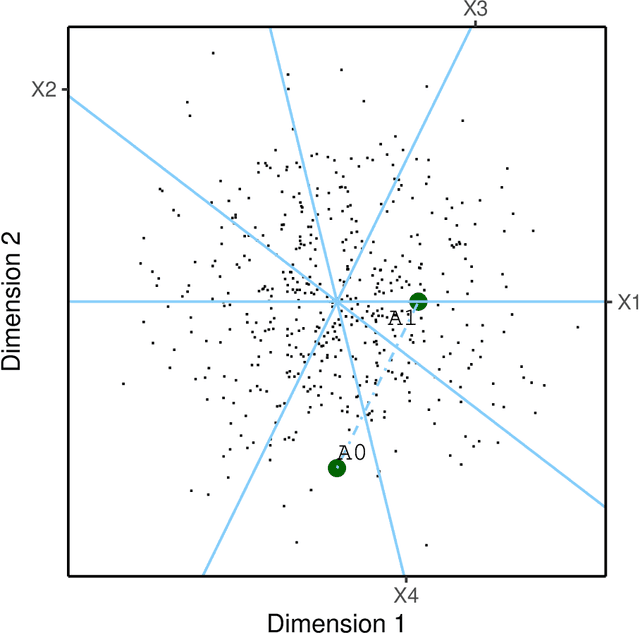
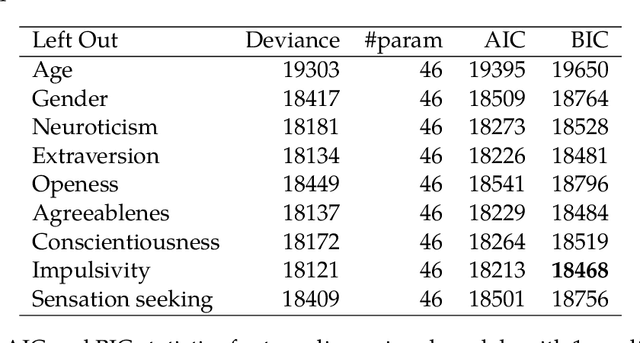
Logistic regression is a commonly used method for binary classification. Researchers often have more than a single binary response variable and simultaneous analysis is beneficial because it provides insight into the dependencies among response variables as well as between the predictor variables and the responses. Moreover, in such a simultaneous analysis the equations can lend each other strength, which might increase predictive accuracy. In this paper, we propose the MELODIC family for simultaneous binary logistic regression modeling. In this family, the regression models are defined in a Euclidean space of reduced dimension, based on a distance rule. The model may be interpreted in terms of logistic regression coefficients or in terms of a biplot. We discuss a fast iterative majorization (or MM) algorithm for parameter estimation. Two applications are shown in detail: one relating personality characteristics to drug consumption profiles and one relating personality characteristics to depressive and anxiety disorders. We present a thorough comparison of our MELODIC family with alternative approaches for multivariate binary data.
View selection in multi-view stacking: Choosing the meta-learner
Oct 30, 2020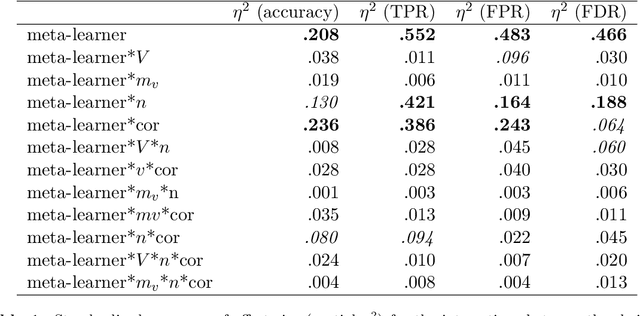
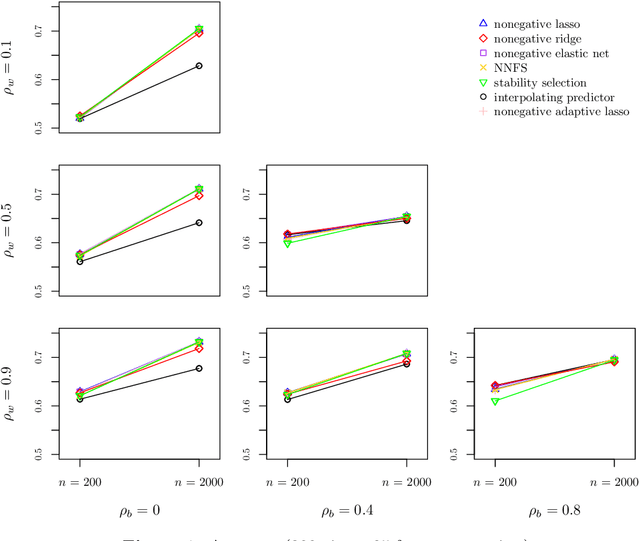
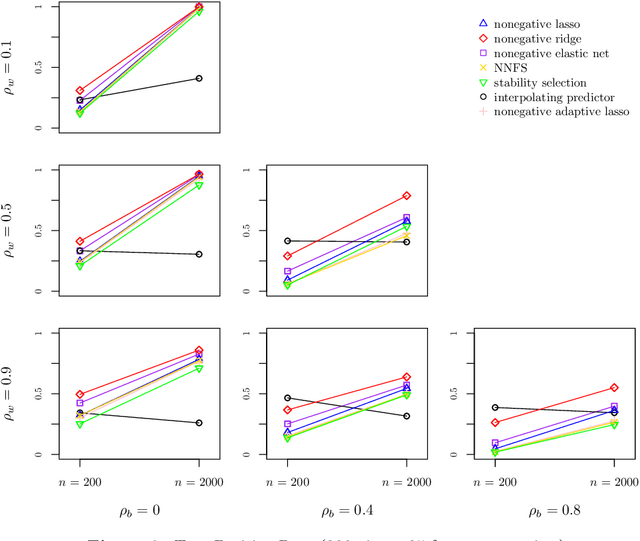

Multi-view stacking is a framework for combining information from different views (i.e. different feature sets) describing the same set of objects. In this framework, a base-learner algorithm is trained on each view separately, and their predictions are then combined by a meta-learner algorithm. In a previous study, stacked penalized logistic regression, a special case of multi-view stacking, has been shown to be useful in identifying which views are most important for prediction. In this article we expand this research by considering seven different algorithms to use as the meta-learner, and evaluating their view selection and classification performance in simulations and two applications on real gene-expression data sets. Our results suggest that if both view selection and classification accuracy are important to the research at hand, then the nonnegative lasso, nonnegative adaptive lasso and nonnegative elastic net are suitable meta-learners. Exactly which among these three is to be preferred depends on the research context. The remaining four meta-learners, namely nonnegative ridge regression, nonnegative forward selection, stability selection and the interpolating predictor, show little advantages in order to be preferred over the other three.
Stacked Penalized Logistic Regression for Selecting Views in Multi-View Learning
Nov 06, 2018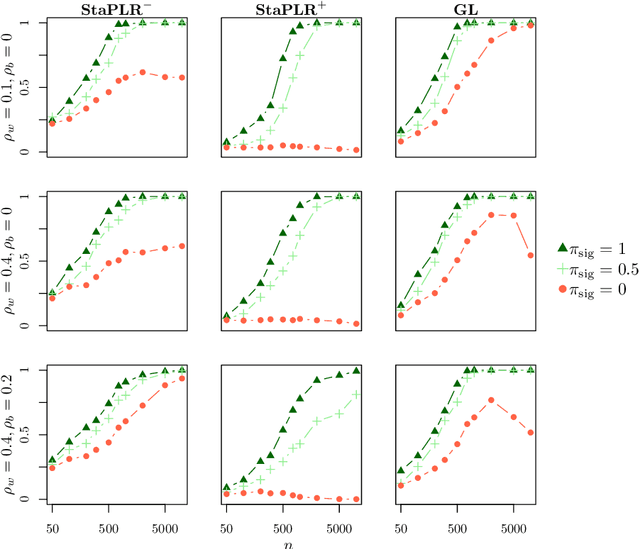
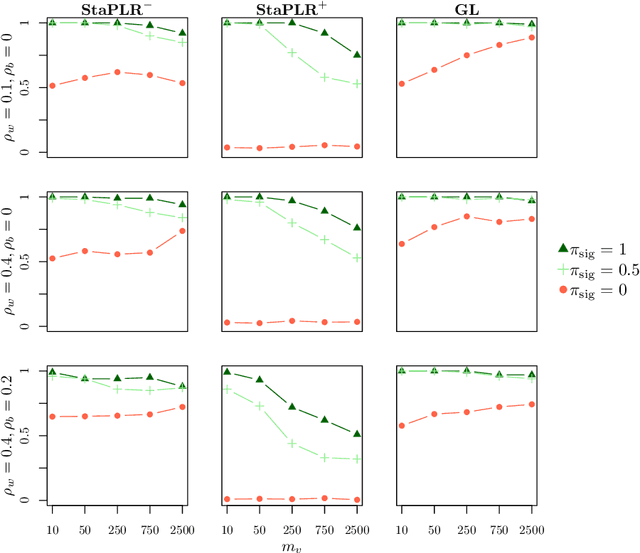
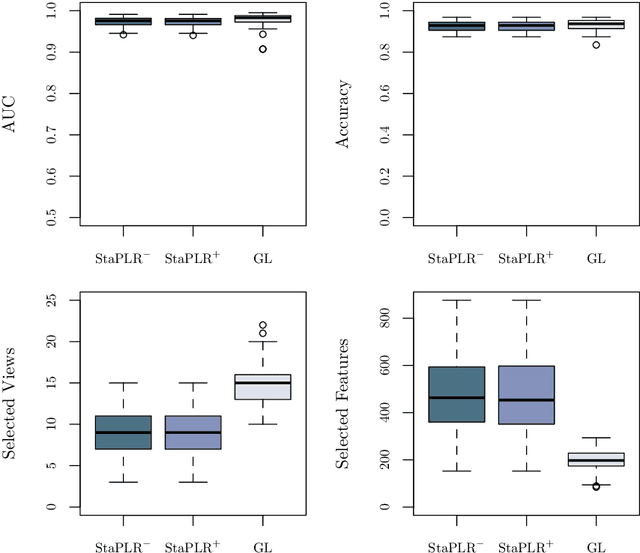
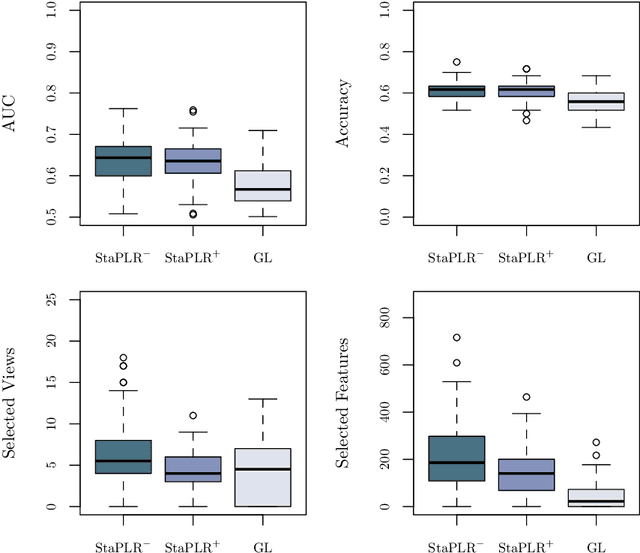
In multi-view learning, features are organized into multiple sets called views. Multi-view stacking (MVS) is an ensemble learning framework which learns a prediction function from each view separately, and then learns a meta-function which optimally combines the view-specific predictions. In case studies, MVS has been shown to increase prediction accuracy. However, the framework can also be used for selecting a subset of important views. We propose a method for selecting views based on MVS, which we call stacked penalized logistic regression (StaPLR). Compared to existing view-selection methods like the group lasso, StaPLR can make use of faster optimization algorithms and is easily parallelized. We show that nonnegativity constraints on the parameters of the function which combines the views are important for preventing unimportant views from entering the model. We investigate the view selection and classification performance of StaPLR and the group lasso through simulations, and consider two real data examples. We observe that StaPLR is less likely to select irrelevant views, leading to models that are sparser at the view level, but which have comparable or increased predictive performance.