 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Approach for Prioritising Driving Behaviour Investigations in Telematic Auto Insurance Policies
Apr 22, 2024



Automotive insurers increasingly have access to telematic information via black-box recorders installed in the insured vehicle, and wish to identify undesirable behaviour which may signify increased risk or uninsured activities. However, identification of such behaviour with machine learning is non-trivial, and results are far from perfect, requiring human investigation to verify suspected cases. An appropriately formed priority score, generated by automated analysis of GPS data, allows underwriters to make more efficient use of their time, improving detection of the behaviour under investigation. An example of such behaviour is the use of a privately insured vehicle for commercial purposes, such as delivering meals and parcels. We first make use of trip GPS and accelerometer data, augmented by geospatial information, to train an imperfect classifier for delivery driving on a per-trip basis. We make use of a mixture of Beta-Binomial distributions to model the propensity of a policyholder to undertake trips which result in a positive classification as being drawn from either a rare high-scoring or common low-scoring group, and learn the parameters of this model using MCMC. This model provides us with a posterior probability that any policyholder will be a regular generator of automated alerts given any number of trips and alerts. This posterior probability is converted to a priority score, which was used to select the most valuable candidates for manual investigation. Testing over a 1-year period ranked policyholders by likelihood of commercial driving activity on a weekly basis. The top 0.9% have been reviewed at least once by the underwriters at the time of writing, and of those 99.4% have been confirmed as correctly identified, showing the approach has achieved a significant improvement in efficiency of human resource allocation compared to manual searching.
Fast Information-theoretic Bayesian Optimisation
Jun 06, 2018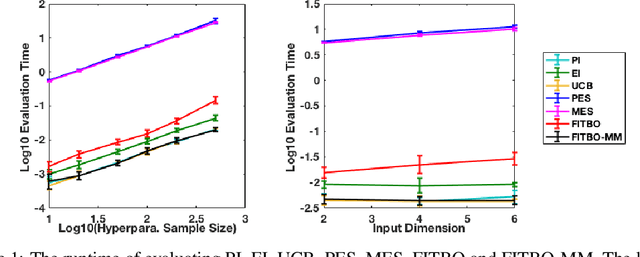
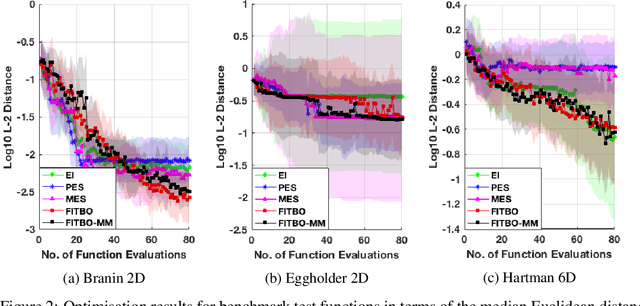
Information-theoretic Bayesian optimisation techniques have demonstrated state-of-the-art performance in tackling important global optimisation problems. However, current information-theoretic approaches require many approximations in implementation, introduce often-prohibitive computational overhead and limit the choice of kernels available to model the objective. We develop a fast information-theoretic Bayesian Optimisation method, FITBO, that avoids the need for sampling the global minimiser, thus significantly reducing computational overhead. Moreover, in comparison with existing approaches, our method faces fewer constraints on kernel choice and enjoys the merits of dealing with the output space. We demonstrate empirically that FITBO inherits the performance associated with information-theoretic Bayesian optimisation, while being even faster than simpler Bayesian optimisation approaches, such as Expected Improvement.
Optimization, fast and slow: optimally switching between local and Bayesian optimization
May 22, 2018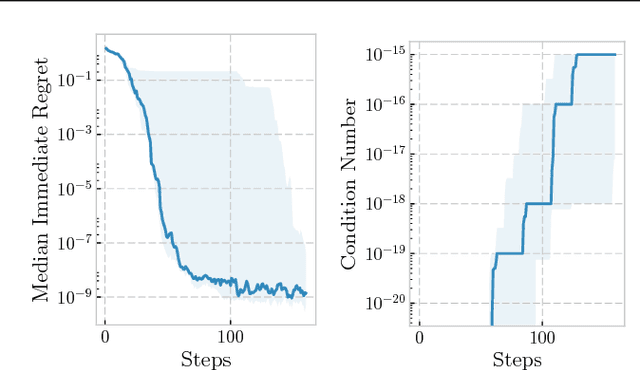

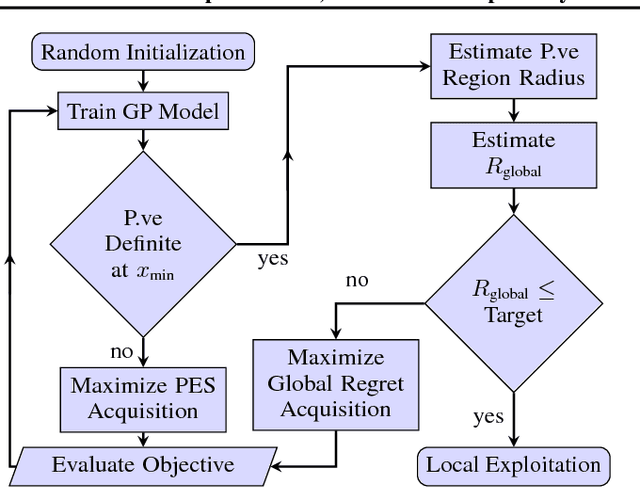

We develop the first Bayesian Optimization algorithm, BLOSSOM, which selects between multiple alternative acquisition functions and traditional local optimization at each step. This is combined with a novel stopping condition based on expected regret. This pairing allows us to obtain the best characteristics of both local and Bayesian optimization, making efficient use of function evaluations while yielding superior convergence to the global minimum on a selection of optimization problems, and also halting optimization once a principled and intuitive stopping condition has been fulfilled.
Practical Bayesian Optimization for Variable Cost Objectives
May 15, 2018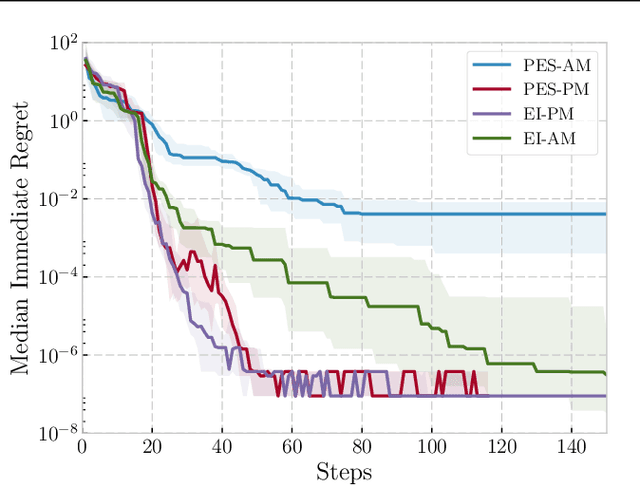
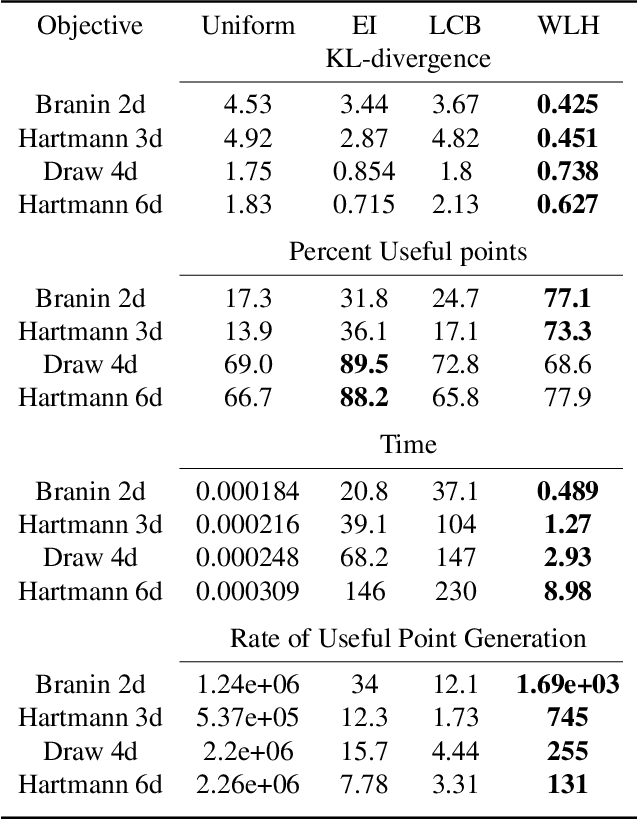
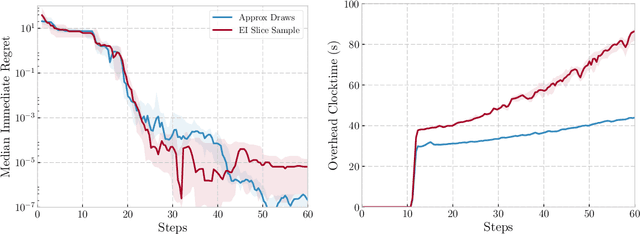
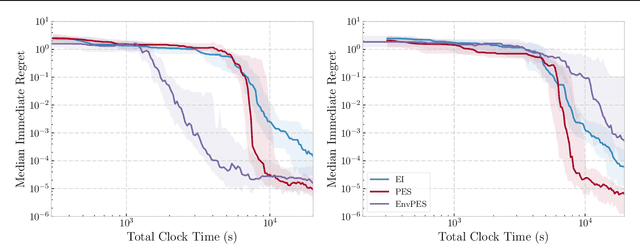
We propose a novel Bayesian Optimization approach for black-box functions with an environmental variable whose value determines the tradeoff between evaluation cost and the fidelity of the evaluations. Further, we use a novel approach to sampling support points, allowing faster construction of the acquisition function. This allows us to achieve optimization with lower overheads than previous approaches and is implemented for a more general class of problem. We show this approach to be effective on synthetic and real world benchmark problems.