 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpacts of floating-point non-associativity on reproducibility for HPC and deep learning applications
Aug 09, 2024Run-by-run variability in parallel programs caused by floating-point non-associativity (FPNA) has been known to significantly affect reproducibility in iterative algorithms, due to accumulating errors. Non-reproducibility negatively affects efficiency and effectiveness of correctness testing for stochastic programs. Recently, the sensitivity of deep learning (DL) training and inference pipelines to FPNA have been found to be extreme, and can prevent certification for commercial applications, accurate assessment of robustness and sensitivity, and bug detection. New approaches in scientific computing applications have coupled DL models with high-performance computing (HPC) simulations, leading to an aggravation of debugging and testing challenges. Here we perform an investigation of the statistical properties of FPNA within modern parallel programming models, analyze performance and productivity impacts of replacing atomic operations with deterministic alternatives on GPUs, and examine the recently-added deterministic options within the PyTorch framework within the context of GPU deployment, uncovering and quantifying the impacts of input parameters triggering run-by-run variability and reporting on the reliability and completeness of the documentation. Finally, we evaluate the strategy of exploiting automatic determinism provided by deterministic hardware, using the Groq LPU$^{TM}$ accelerator for inference portions of the DL pipeline. We demonstrate the benefits that this strategy can provide within reproducibility and correctness efforts.
SuperNeuro: A Fast and Scalable Simulator for Neuromorphic Computing
May 04, 2023
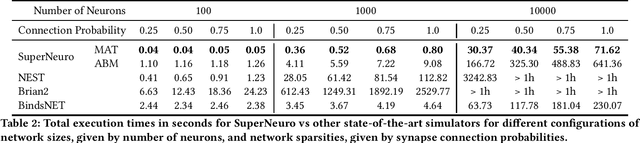
In many neuromorphic workflows, simulators play a vital role for important tasks such as training spiking neural networks (SNNs), running neuroscience simulations, and designing, implementing and testing neuromorphic algorithms. Currently available simulators are catered to either neuroscience workflows (such as NEST and Brian2) or deep learning workflows (such as BindsNET). While the neuroscience-based simulators are slow and not very scalable, the deep learning-based simulators do not support certain functionalities such as synaptic delay that are typical of neuromorphic workloads. In this paper, we address this gap in the literature and present SuperNeuro, which is a fast and scalable simulator for neuromorphic computing, capable of both homogeneous and heterogeneous simulations as well as GPU acceleration. We also present preliminary results comparing SuperNeuro to widely used neuromorphic simulators such as NEST, Brian2 and BindsNET in terms of computation times. We demonstrate that SuperNeuro can be approximately 10--300 times faster than some of the other simulators for small sparse networks. On large sparse and large dense networks, SuperNeuro can be approximately 2.2 and 3.4 times faster than the other simulators respectively.