 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Langevin Dynamics: towards interpretable Neural Stochastic Differential Equations
Nov 17, 2022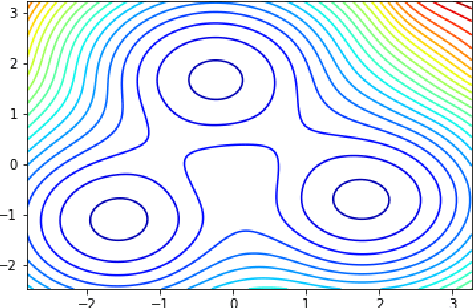
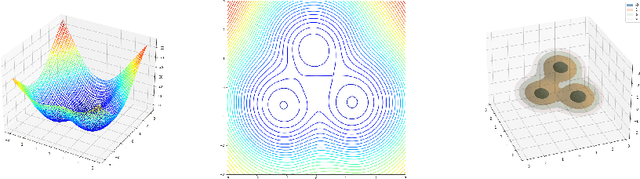
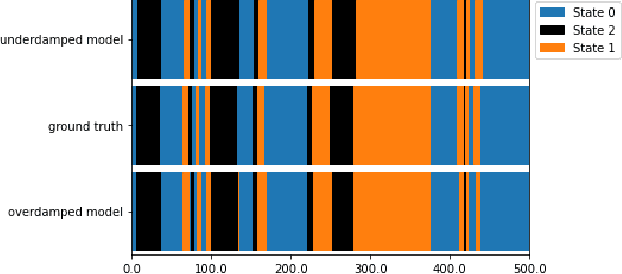
Neural Stochastic Differential Equations (NSDE) have been trained as both Variational Autoencoders, and as GANs. However, the resulting Stochastic Differential Equations can be hard to interpret or analyse due to the generic nature of the drift and diffusion fields. By restricting our NSDE to be of the form of Langevin dynamics, and training it as a VAE, we obtain NSDEs that lend themselves to more elaborate analysis and to a wider range of visualisation techniques than a generic NSDE. More specifically, we obtain an energy landscape, the minima of which are in one-to-one correspondence with latent states underlying the used data. This not only allows us to detect states underlying the data dynamics in an unsupervised manner, but also to infer the distribution of time spent in each state according to the learned SDE. More in general, restricting an NSDE to Langevin dynamics enables the use of a large set of tools from computational molecular dynamics for the analysis of the obtained results.
Universal Approximation in Dropout Neural Networks
Dec 18, 2020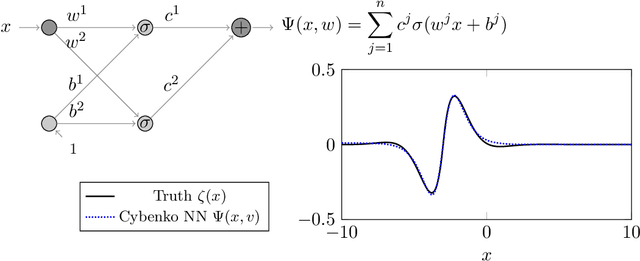
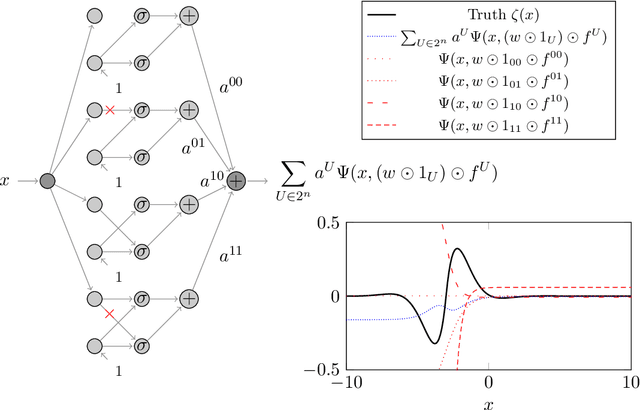
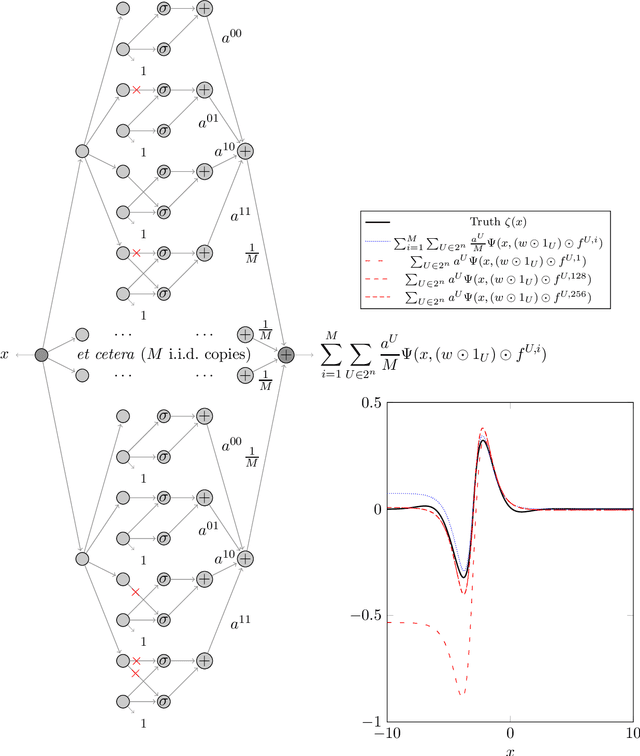
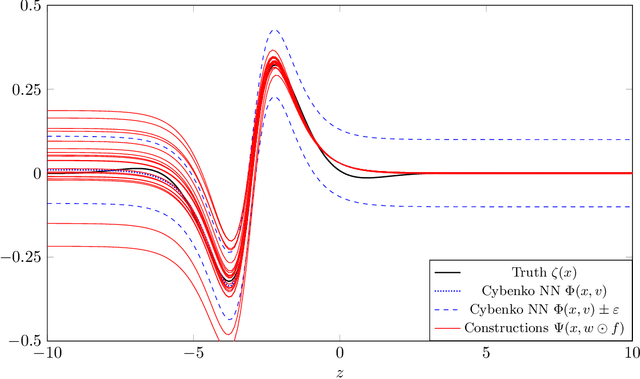
We prove two universal approximation theorems for a range of dropout neural networks. These are feed-forward neural networks in which each edge is given a random $\{0,1\}$-valued filter, that have two modes of operation: in the first each edge output is multiplied by its random filter, resulting in a random output, while in the second each edge output is multiplied by the expectation of its filter, leading to a deterministic output. It is common to use the random mode during training and the deterministic mode during testing and prediction. Both theorems are of the following form: Given a function to approximate and a threshold $\varepsilon>0$, there exists a dropout network that is $\varepsilon$-close in probability and in $L^q$. The first theorem applies to dropout networks in the random mode. It assumes little on the activation function, applies to a wide class of networks, and can even be applied to approximation schemes other than neural networks. The core is an algebraic property that shows that deterministic networks can be exactly matched in expectation by random networks. The second theorem makes stronger assumptions and gives a stronger result. Given a function to approximate, it provides existence of a network that approximates in both modes simultaneously. Proof components are a recursive replacement of edges by independent copies, and a special first-layer replacement that couples the resulting larger network to the input. The functions to be approximated are assumed to be elements of general normed spaces, and the approximations are measured in the corresponding norms. The networks are constructed explicitly. Because of the different methods of proof, the two results give independent insight into the approximation properties of random dropout networks. With this, we establish that dropout neural networks broadly satisfy a universal-approximation property.