 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Authorship Verification using Linguistic Divergence
Mar 12, 2021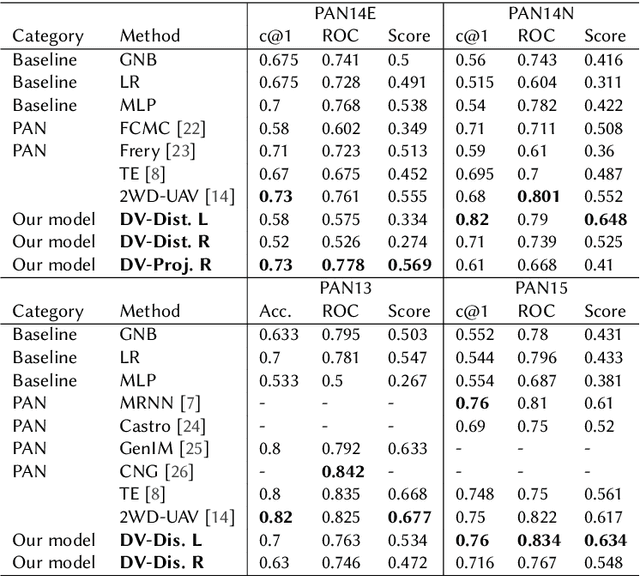
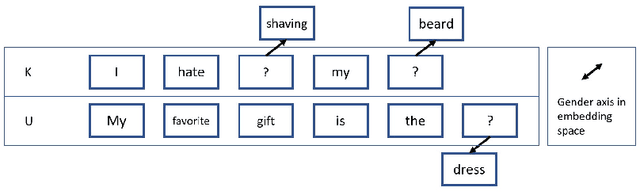
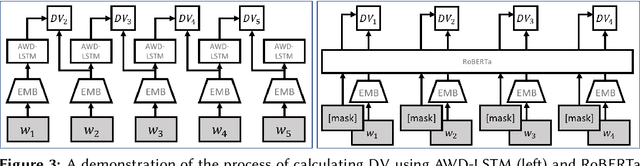
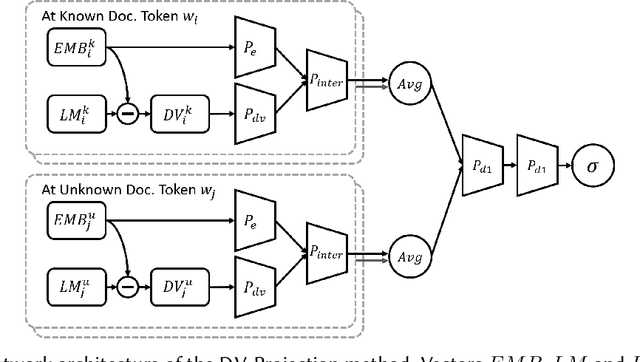
We propose an unsupervised solution to the Authorship Verification task that utilizes pre-trained deep language models to compute a new metric called DV-Distance. The proposed metric is a measure of the difference between the two authors comparing against pre-trained language models. Our design addresses the problem of non-comparability in authorship verification, frequently encountered in small or cross-domain corpora. To the best of our knowledge, this paper is the first one to introduce a method designed with non-comparability in mind from the ground up, rather than indirectly. It is also one of the first to use Deep Language Models in this setting. The approach is intuitive, and it is easy to understand and interpret through visualization. Experiments on four datasets show our methods matching or surpassing current state-of-the-art and strong baselines in most tasks.
Multi-Aspect Sentiment Analysis with Latent Sentiment-Aspect Attribution
Dec 15, 2020

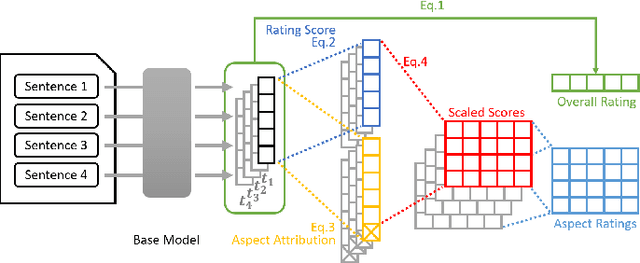
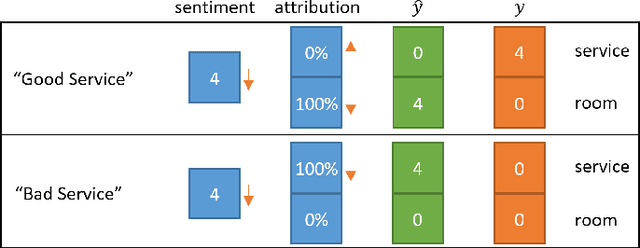
In this paper, we introduce a new framework called the sentiment-aspect attribution module (SAAM). SAAM works on top of traditional neural networks and is designed to address the problem of multi-aspect sentiment classification and sentiment regression. The framework works by exploiting the correlations between sentence-level embedding features and variations of document-level aspect rating scores. We demonstrate several variations of our framework on top of CNN and RNN based models. Experiments on a hotel review dataset and a beer review dataset have shown SAAM can improve sentiment analysis performance over corresponding base models. Moreover, because of the way our framework intuitively combines sentence-level scores into document-level scores, it is able to provide a deeper insight into data (e.g., semi-supervised sentence aspect labeling). Hence, we end the paper with a detailed analysis that shows the potential of our models for other applications such as sentiment snippet extraction.
Stance Prediction for Contemporary Issues: Data and Experiments
May 29, 2020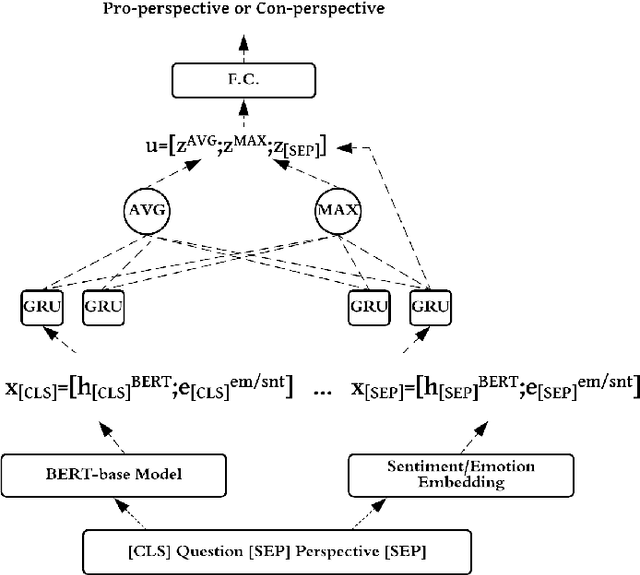


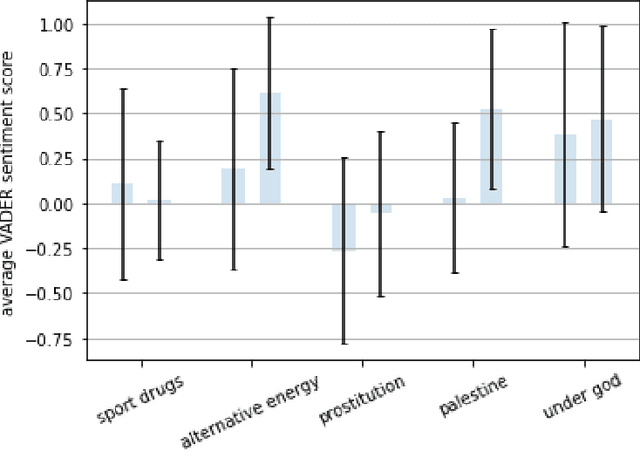
We investigate whether pre-trained bidirectional transformers with sentiment and emotion information improve stance detection in long discussions of contemporary issues. As a part of this work, we create a novel stance detection dataset covering 419 different controversial issues and their related pros and cons collected by procon.org in nonpartisan format. Experimental results show that a shallow recurrent neural network with sentiment or emotion information can reach competitive results compared to fine-tuned BERT with 20x fewer parameters. We also use a simple approach that explains which input phrases contribute to stance detection.
Experiments with Neural Networks for Small and Large Scale Authorship Verification
Mar 17, 2018
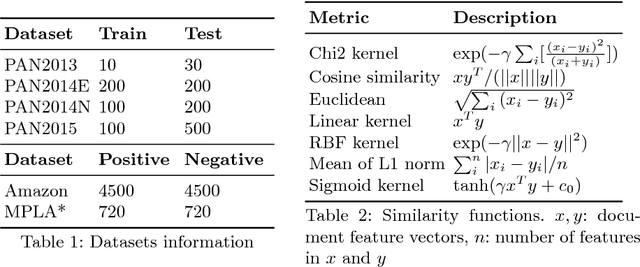
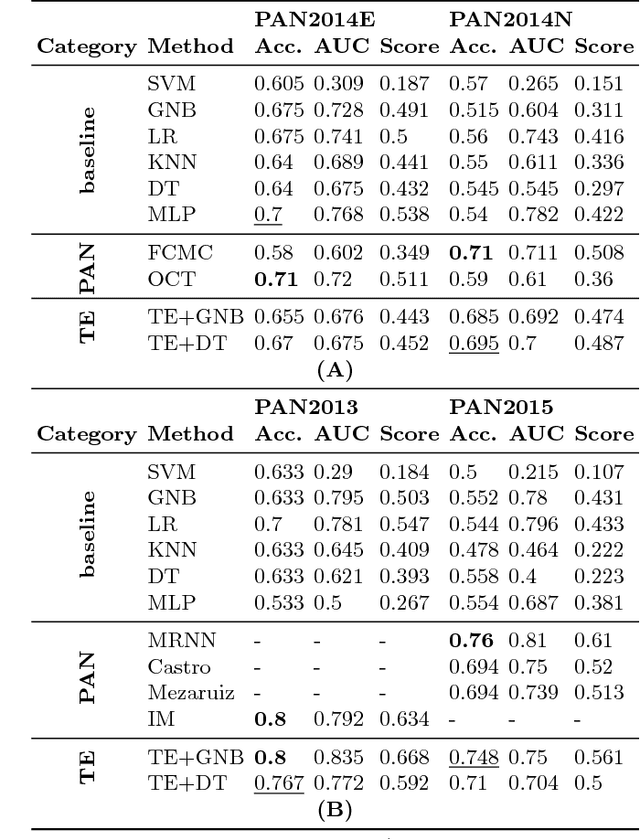
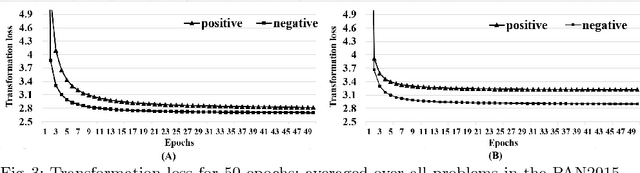
We propose two models for a special case of authorship verification problem. The task is to investigate whether the two documents of a given pair are written by the same author. We consider the authorship verification problem for both small and large scale datasets. The underlying small-scale problem has two main challenges: First, the authors of the documents are unknown to us because no previous writing samples are available. Second, the two documents are short (a few hundred to a few thousand words) and may differ considerably in the genre and/or topic. To solve it we propose transformation encoder to transform one document of the pair into the other. This document transformation generates a loss which is used as a recognizable feature to verify if the authors of the pair are identical. For the large scale problem where various authors are engaged and more examples are available with larger length, a parallel recurrent neural network is proposed. It compares the language models of the two documents. We evaluate our methods on various types of datasets including Authorship Identification datasets of PAN competition, Amazon reviews, and machine learning articles. Experiments show that both methods achieve stable and competitive performance compared to the baselines.
Detecting Sockpuppets in Deceptive Opinion Spam
Mar 09, 2017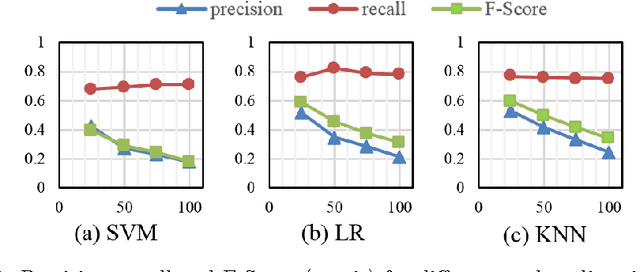


This paper explores the problem of sockpuppet detection in deceptive opinion spam using authorship attribution and verification approaches. Two methods are explored. The first is a feature subsampling scheme that uses the KL-Divergence on stylistic language models of an author to find discriminative features. The second is a transduction scheme, spy induction that leverages the diversity of authors in the unlabeled test set by sending a set of spies (positive samples) from the training set to retrieve hidden samples in the unlabeled test set using nearest and farthest neighbors. Experiments using ground truth sockpuppet data show the effectiveness of the proposed schemes.