 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable End-to-End Prostate Cancer Relapse Prediction from H&E Images Combining Self-Attention Multiple Instance Learning with a Recurrent Neural Network
Nov 26, 2021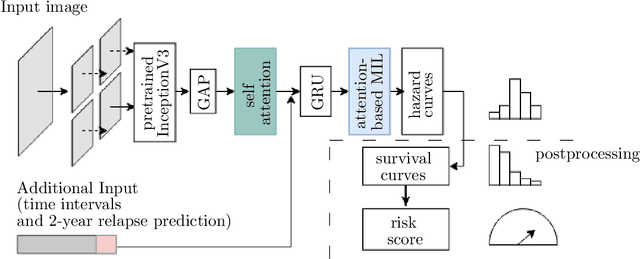
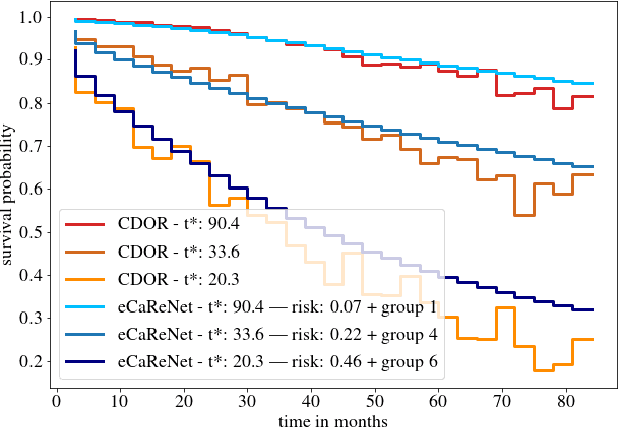
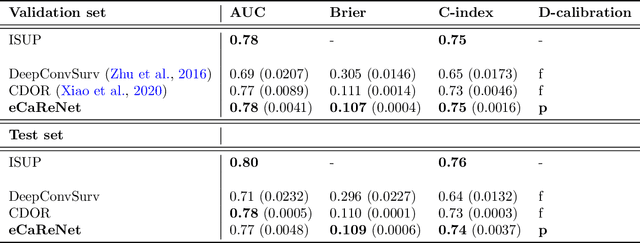
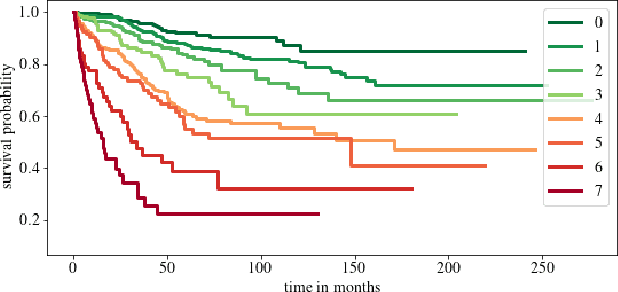
Clinical decision support for histopathology image data mainly focuses on strongly supervised annotations, which offers intuitive interpretability, but is bound by expert performance. Here, we propose an explainable cancer relapse prediction network (eCaReNet) and show that end-to-end learning without strong annotations offers state-of-the-art performance while interpretability can be included through an attention mechanism. On the use case of prostate cancer survival prediction, using 14,479 images and only relapse times as annotations, we reach a cumulative dynamic AUC of 0.78 on a validation set, being on par with an expert pathologist (and an AUC of 0.77 on a separate test set). Our model is well-calibrated and outputs survival curves as well as a risk score and group per patient. Making use of the attention weights of a multiple instance learning layer, we show that malignant patches have a higher influence on the prediction than benign patches, thus offering an intuitive interpretation of the prediction. Our code is available at www.github.com/imsb-uke/ecarenet.
Deep learning-based bias transfer for overcoming laboratory differences of microscopic images
May 25, 2021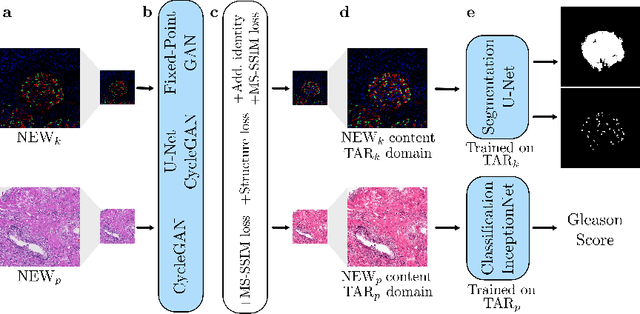
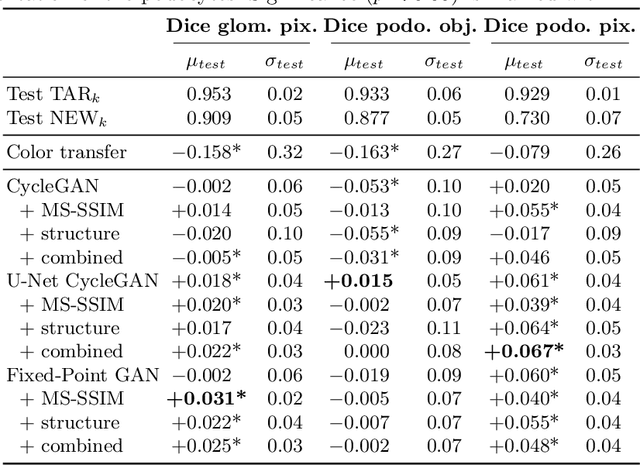
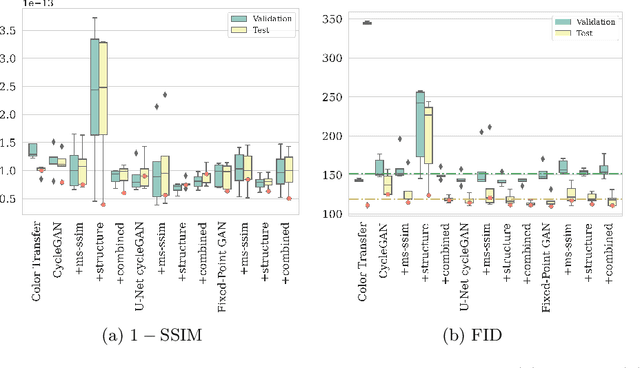
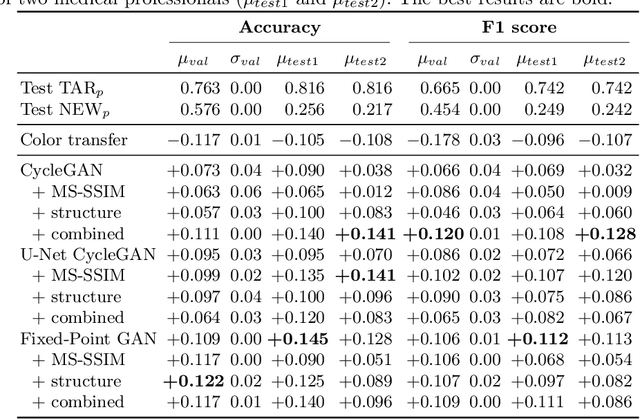
The automated analysis of medical images is currently limited by technical and biological noise and bias. The same source tissue can be represented by vastly different images if the image acquisition or processing protocols vary. For an image analysis pipeline, it is crucial to compensate such biases to avoid misinterpretations. Here, we evaluate, compare, and improve existing generative model architectures to overcome domain shifts for immunofluorescence (IF) and Hematoxylin and Eosin (H&E) stained microscopy images. To determine the performance of the generative models, the original and transformed images were segmented or classified by deep neural networks that were trained only on images of the target bias. In the scope of our analysis, U-Net cycleGANs trained with an additional identity and an MS-SSIM-based loss and Fixed-Point GANs trained with an additional structure loss led to the best results for the IF and H&E stained samples, respectively. Adapting the bias of the samples significantly improved the pixel-level segmentation for human kidney glomeruli and podocytes and improved the classification accuracy for human prostate biopsies by up to 14%.
Combining Multiple Views for Visual Speech Recognition
Jun 28, 2018
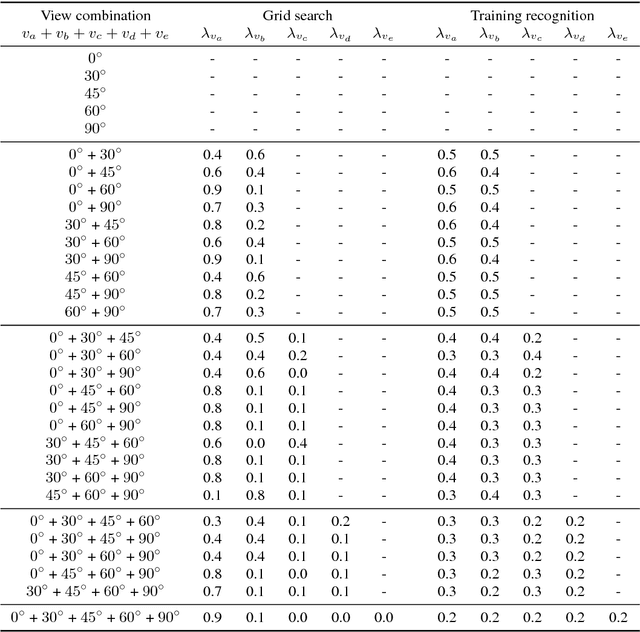
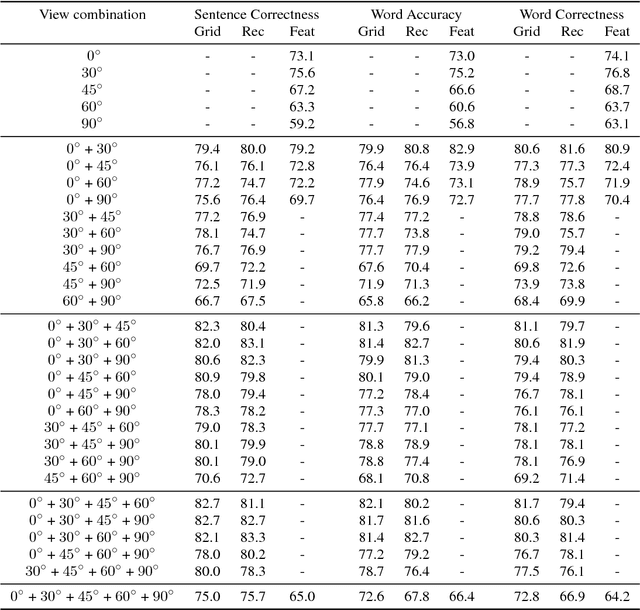
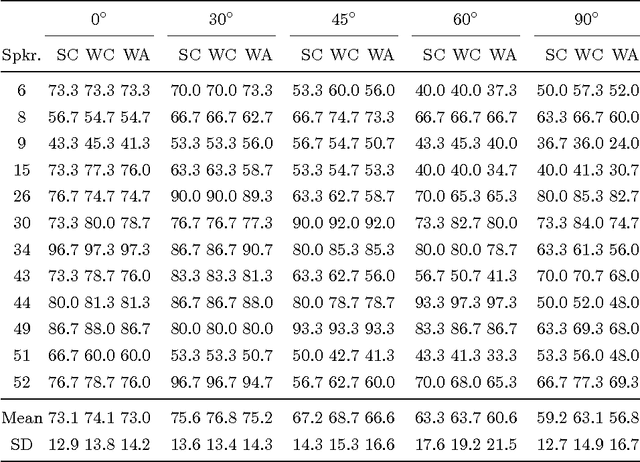
Visual speech recognition is a challenging research problem with a particular practical application of aiding audio speech recognition in noisy scenarios. Multiple camera setups can be beneficial for the visual speech recognition systems in terms of improved performance and robustness. In this paper, we explore this aspect and provide a comprehensive study on combining multiple views for visual speech recognition. The thorough analysis covers fusion of all possible view angle combinations both at feature level and decision level. The employed visual speech recognition system in this study extracts features through a PCA-based convolutional neural network, followed by an LSTM network. Finally, these features are processed in a tandem system, being fed into a GMM-HMM scheme. The decision fusion acts after this point by combining the Viterbi path log-likelihoods. The results show that the complementary information contained in recordings from different view angles improves the results significantly. For example, the sentence correctness on the test set is increased from 76% for the highest performing single view ($30^\circ$) to up to 83% when combining this view with the frontal and $60^\circ$ view angles.
Visual Speech Recognition Using PCA Networks and LSTMs in a Tandem GMM-HMM System
Oct 19, 2017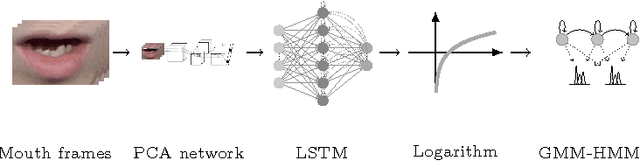

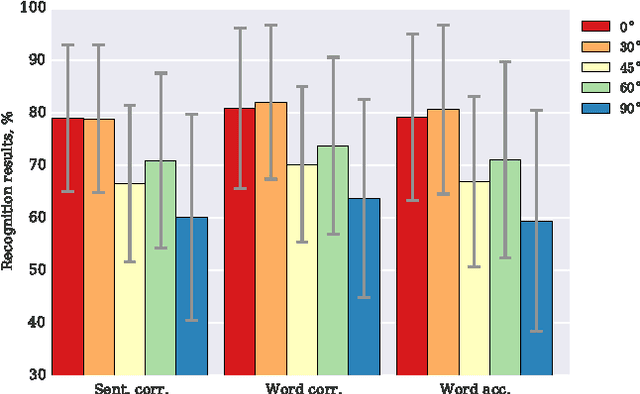
Automatic visual speech recognition is an interesting problem in pattern recognition especially when audio data is noisy or not readily available. It is also a very challenging task mainly because of the lower amount of information in the visual articulations compared to the audible utterance. In this work, principle component analysis is applied to the image patches - extracted from the video data - to learn the weights of a two-stage convolutional network. Block histograms are then extracted as the unsupervised learning features. These features are employed to learn a recurrent neural network with a set of long short-term memory cells to obtain spatiotemporal features. Finally, the obtained features are used in a tandem GMM-HMM system for speech recognition. Our results show that the proposed method has outperformed the baseline techniques applied to the OuluVS2 audiovisual database for phrase recognition with the frontal view cross-validation and testing sentence correctness reaching 79% and 73%, respectively, as compared to the baseline of 74% on cross-validation.