 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Speech Recognition Using PCA Networks and LSTMs in a Tandem GMM-HMM System
Paper and Code
Oct 19, 2017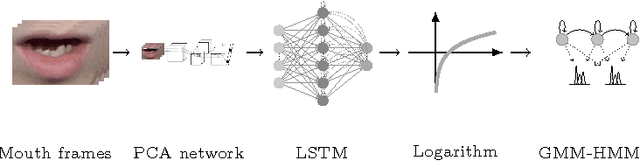
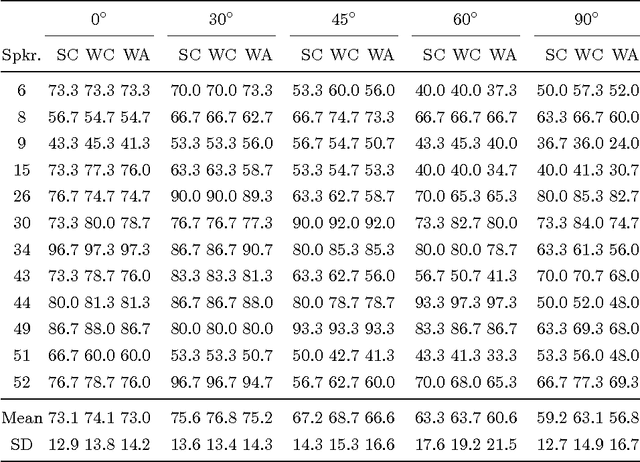

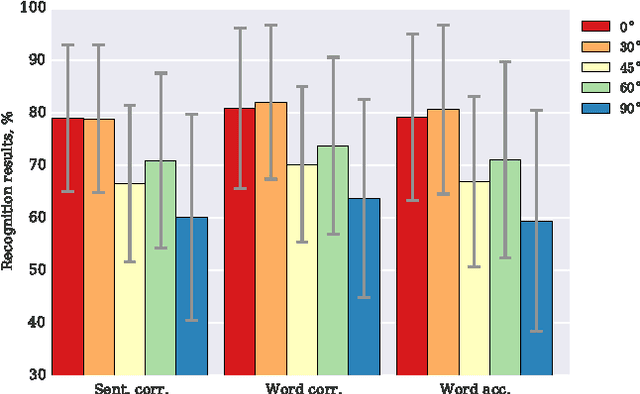
Automatic visual speech recognition is an interesting problem in pattern recognition especially when audio data is noisy or not readily available. It is also a very challenging task mainly because of the lower amount of information in the visual articulations compared to the audible utterance. In this work, principle component analysis is applied to the image patches - extracted from the video data - to learn the weights of a two-stage convolutional network. Block histograms are then extracted as the unsupervised learning features. These features are employed to learn a recurrent neural network with a set of long short-term memory cells to obtain spatiotemporal features. Finally, the obtained features are used in a tandem GMM-HMM system for speech recognition. Our results show that the proposed method has outperformed the baseline techniques applied to the OuluVS2 audiovisual database for phrase recognition with the frontal view cross-validation and testing sentence correctness reaching 79% and 73%, respectively, as compared to the baseline of 74% on cross-validation.