 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARL-GPT: Foundation Model for Multi-Agent Reinforcement Learning
Apr 07, 2026Recent advances in multi-agent reinforcement learning (MARL) have demonstrated success in numerous challenging domains and environments, but typically require specialized models for each task. In this work, we propose a coherent methodology that makes it possible for a single GPT-based model to learn and perform well across diverse MARL environments and tasks, including StarCraft Multi-Agent Challenge, Google Research Football and POGEMA. Our method, MARL-GPT, applies offline reinforcement learning to train at scale on the expert trajectories (400M for SMACv2, 100M for GRF, and 1B for POGEMA) combined with a single transformer-based observation encoder that requires no task-specific tuning. Experiments show that MARL-GPT achieves competitive performance compared to specialized baselines in all tested environments. Thus, our findings suggest that it is, indeed, possible to build a multi-task transformer-based model for a wide variety of (significantly different) multi-agent problems paving the way to the fundamental MARL model (akin to ChatGPT, Llama, Mistral etc. in natural language modeling).
Learn to Follow: Decentralized Lifelong Multi-agent Pathfinding via Planning and Learning
Oct 02, 2023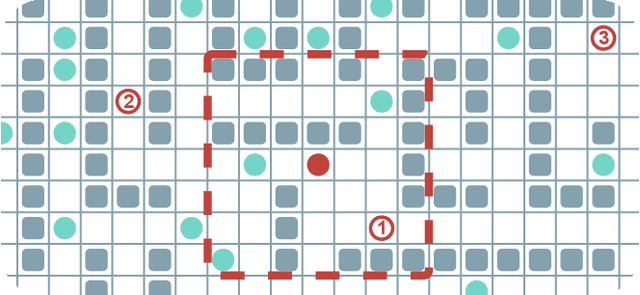



Multi-agent Pathfinding (MAPF) problem generally asks to find a set of conflict-free paths for a set of agents confined to a graph and is typically solved in a centralized fashion. Conversely, in this work, we investigate the decentralized MAPF setting, when the central controller that posses all the information on the agents' locations and goals is absent and the agents have to sequientially decide the actions on their own without having access to a full state of the environment. We focus on the practically important lifelong variant of MAPF, which involves continuously assigning new goals to the agents upon arrival to the previous ones. To address this complex problem, we propose a method that integrates two complementary approaches: planning with heuristic search and reinforcement learning through policy optimization. Planning is utilized to construct and re-plan individual paths. We enhance our planning algorithm with a dedicated technique tailored to avoid congestion and increase the throughput of the system. We employ reinforcement learning to discover the collision avoidance policies that effectively guide the agents along the paths. The policy is implemented as a neural network and is effectively trained without any reward-shaping or external guidance. We evaluate our method on a wide range of setups comparing it to the state-of-the-art solvers. The results show that our method consistently outperforms the learnable competitors, showing higher throughput and better ability to generalize to the maps that were unseen at the training stage. Moreover our solver outperforms a rule-based one in terms of throughput and is an order of magnitude faster than a state-of-the-art search-based solver.
Reinforcement Learning with Success Induced Task Prioritization
Dec 30, 2022Many challenging reinforcement learning (RL) problems require designing a distribution of tasks that can be applied to train effective policies. This distribution of tasks can be specified by the curriculum. A curriculum is meant to improve the results of learning and accelerate it. We introduce Success Induced Task Prioritization (SITP), a framework for automatic curriculum learning, where a task sequence is created based on the success rate of each task. In this setting, each task is an algorithmically created environment instance with a unique configuration. The algorithm selects the order of tasks that provide the fastest learning for agents. The probability of selecting any of the tasks for the next stage of learning is determined by evaluating its performance score in previous stages. Experiments were carried out in the Partially Observable Grid Environment for Multiple Agents (POGEMA) and Procgen benchmark. We demonstrate that SITP matches or surpasses the results of other curriculum design methods. Our method can be implemented with handful of minor modifications to any standard RL framework and provides useful prioritization with minimal computational overhead.