 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Relation Extraction with OpenIE
Dec 19, 2022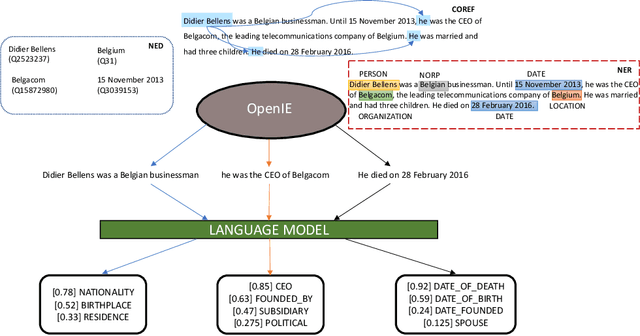
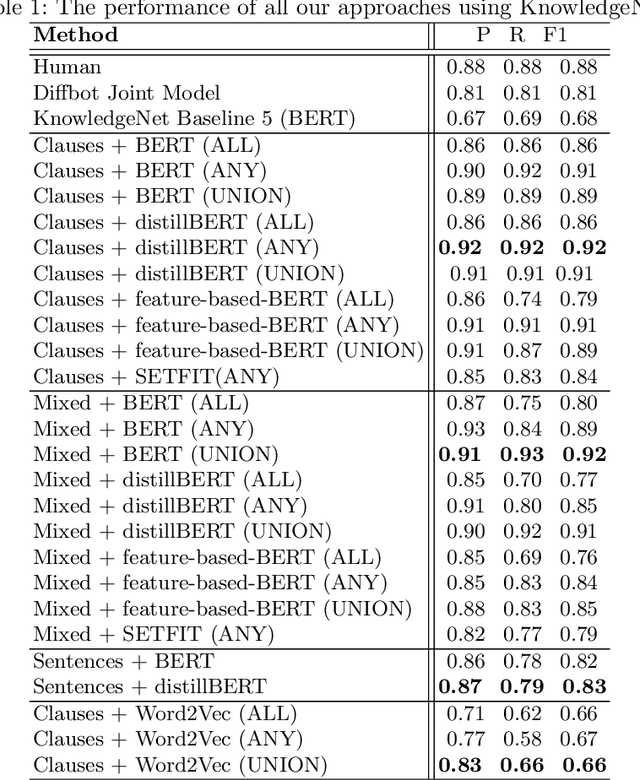
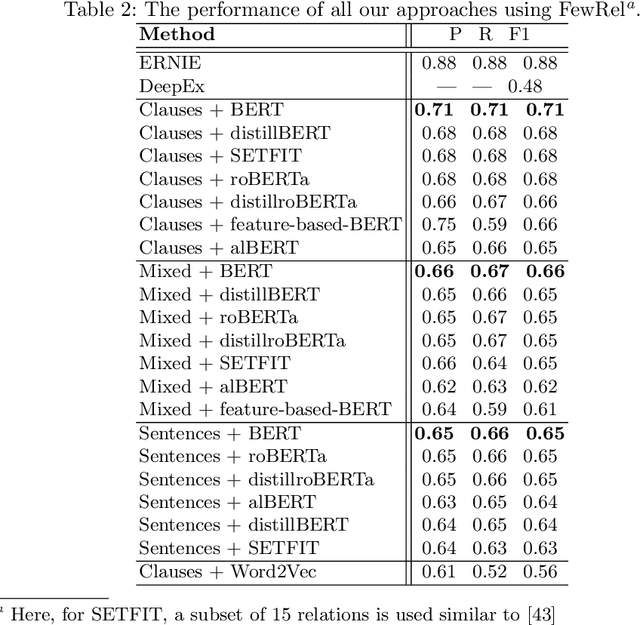
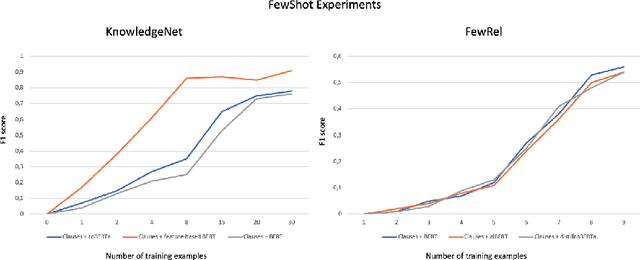
Relation extraction (RE) is a sub-discipline of information extraction (IE) which focuses on the prediction of a relational predicate from a natural-language input unit (such as a sentence, a clause, or even a short paragraph consisting of multiple sentences and/or clauses). Together with named-entity recognition (NER) and disambiguation (NED), RE forms the basis for many advanced IE tasks such as knowledge-base (KB) population and verification. In this work, we explore how recent approaches for open information extraction (OpenIE) may help to improve the task of RE by encoding structured information about the sentences' principal units, such as subjects, objects, verbal phrases, and adverbials, into various forms of vectorized (and hence unstructured) representations of the sentences. Our main conjecture is that the decomposition of long and possibly convoluted sentences into multiple smaller clauses via OpenIE even helps to fine-tune context-sensitive language models such as BERT (and its plethora of variants) for RE. Our experiments over two annotated corpora, KnowledgeNet and FewRel, demonstrate the improved accuracy of our enriched models compared to existing RE approaches. Our best results reach 92% and 71% of F1 score for KnowledgeNet and FewRel, respectively, proving the effectiveness of our approach on competitive benchmarks.
BigText-QA: Question Answering over a Large-Scale Hybrid Knowledge Graph
Dec 12, 2022Answering complex questions over textual resources remains a challenging problem$\unicode{x2013}$especially when interpreting the fine-grained relationships among multiple entities that occur within a natural-language question or clue. Curated knowledge bases (KBs), such as YAGO, DBpedia, Freebase and Wikidata, have been widely used in this context and gained great acceptance for question-answering (QA) applications in the past decade. While current KBs offer a concise representation of structured knowledge, they lack the variety of formulations and semantic nuances as well as the context of information provided by the natural-language sources. With BigText-QA, we aim to develop an integrated QA system which is able to answer questions based on a more redundant form of a knowledge graph (KG) that organizes both structured and unstructured (i.e., "hybrid") knowledge in a unified graphical representation. BigText-QA thereby is able to combine the best of both worlds$\unicode{x2013}$a canonical set of named entities, mapped to a structured background KB (such as YAGO or Wikidata), as well as an open set of textual clauses providing highly diversified relational paraphrases with rich context information.
Comparison of Syntactic Parsers on Biomedical Texts
Aug 17, 2020



Syntactic parsing is an important step in the automated text analysis which aims at information extraction. Quality of the syntactic parsing determines to a large extent the recall and precision of the text mining results. In this paper we evaluate the performance of several popular syntactic parsers in application to the biomedical text mining.