 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Moralization Corpus: Frame-Based Annotation and Analysis of Moralizing Speech Acts across Diverse Text Genres
Dec 17, 2025Moralizations - arguments that invoke moral values to justify demands or positions - are a yet underexplored form of persuasive communication. We present the Moralization Corpus, a novel multi-genre dataset designed to analyze how moral values are strategically used in argumentative discourse. Moralizations are pragmatically complex and often implicit, posing significant challenges for both human annotators and NLP systems. We develop a frame-based annotation scheme that captures the constitutive elements of moralizations - moral values, demands, and discourse protagonists - and apply it to a diverse set of German texts, including political debates, news articles, and online discussions. The corpus enables fine-grained analysis of moralizing language across communicative formats and domains. We further evaluate several large language models (LLMs) under varied prompting conditions for the task of moralization detection and moralization component extraction and compare it to human annotations in order to investigate the challenges of automatic and manual analysis of moralizations. Results show that detailed prompt instructions has a greater effect than few-shot or explanation-based prompting, and that moralization remains a highly subjective and context-sensitive task. We release all data, annotation guidelines, and code to foster future interdisciplinary research on moral discourse and moral reasoning in NLP.
CO-NNECT: A Framework for Revealing Commonsense Knowledge Paths as Explicitations of Implicit Knowledge in Texts
May 07, 2021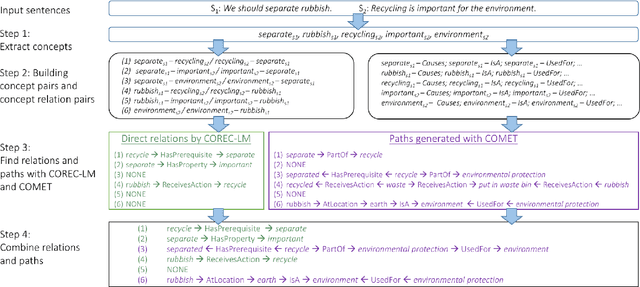
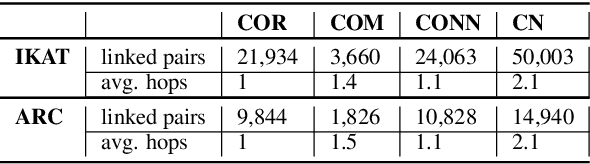

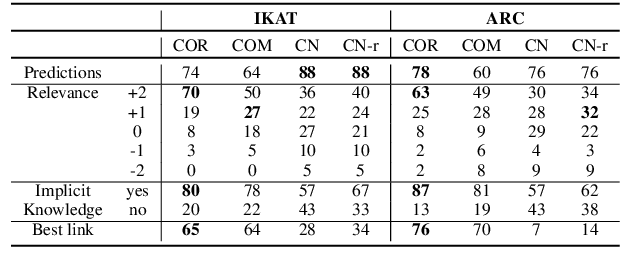
In this work we leverage commonsense knowledge in form of knowledge paths to establish connections between sentences, as a form of explicitation of implicit knowledge. Such connections can be direct (singlehop paths) or require intermediate concepts (multihop paths). To construct such paths we combine two model types in a joint framework we call Co-nnect: a relation classifier that predicts direct connections between concepts; and a target prediction model that generates target or intermediate concepts given a source concept and a relation, which we use to construct multihop paths. Unlike prior work that relies exclusively on static knowledge sources, we leverage language models finetuned on knowledge stored in ConceptNet, to dynamically generate knowledge paths, as explanations of implicit knowledge that connects sentences in texts. As a central contribution we design manual and automatic evaluation settings for assessing the quality of the generated paths. We conduct evaluations on two argumentative datasets and show that a combination of the two model types generates meaningful, high-quality knowledge paths between sentences that reveal implicit knowledge conveyed in text.
Implicit Knowledge in Argumentative Texts: An Annotated Corpus
Dec 04, 2019



When speaking or writing, people omit information that seems clear and evident, such that only part of the message is expressed in words. Especially in argumentative texts it is very common that (important) parts of the argument are implied and omitted. We hypothesize that for argument analysis it will be beneficial to reconstruct this implied information. As a starting point for filling such knowledge gaps, we build a corpus consisting of high-quality human annotations of missing and implied information in argumentative texts. To learn more about the characteristics of both the argumentative texts and the added information, we further annotate the data with semantic clause types and commonsense knowledge relations. The outcome of our work is a carefully de-signed and richly annotated dataset, for which we then provide an in-depth analysis by investigating characteristic distributions and correlations of the assigned labels. We reveal interesting patterns and intersections between the annotation categories and properties of our dataset, which enable insights into the characteristics of both argumentative texts and implicit knowledge in terms of structural features and semantic information. The results of our analysis can help to assist automated argument analysis and can guide the process of revealing implicit information in argumentative texts automatically.
Assessing the Difficulty of Classifying ConceptNet Relations in a Multi-Label Classification Setting
May 14, 2019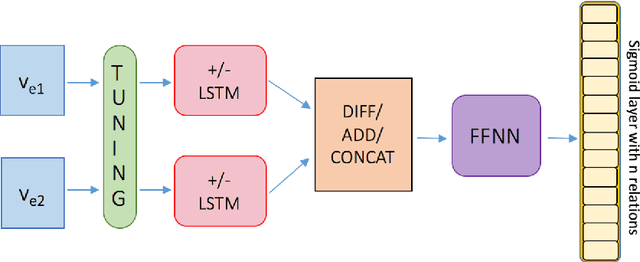

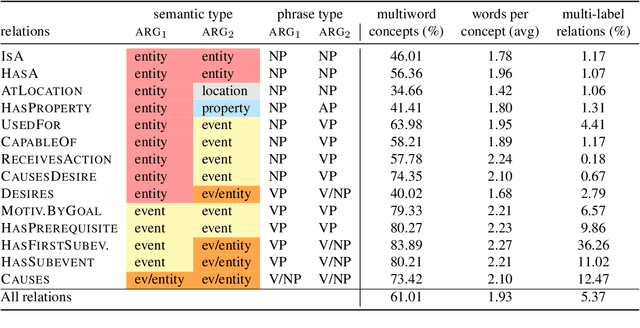
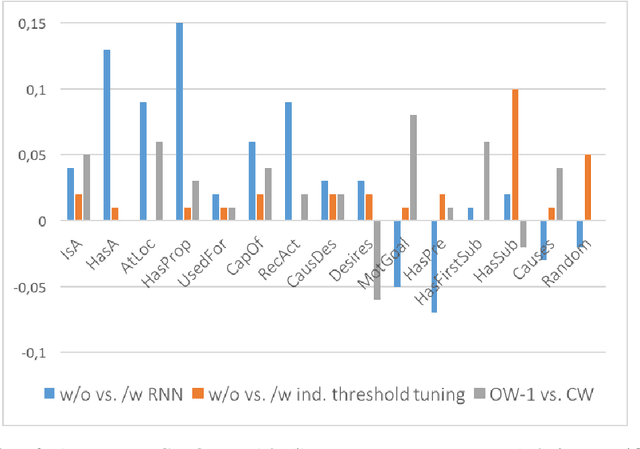
Commonsense knowledge relations are crucial for advanced NLU tasks. We examine the learnability of such relations as represented in CONCEPTNET, taking into account their specific properties, which can make relation classification difficult: a given concept pair can be linked by multiple relation types, and relations can have multi-word arguments of diverse semantic types. We explore a neural open world multi-label classification approach that focuses on the evaluation of classification accuracy for individual relations. Based on an in-depth study of the specific properties of the CONCEPTNET resource, we investigate the impact of different relation representations and model variations. Our analysis reveals that the complexity of argument types and relation ambiguity are the most important challenges to address. We design a customized evaluation method to address the incompleteness of the resource that can be expanded in future work.