 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCO-NNECT: A Framework for Revealing Commonsense Knowledge Paths as Explicitations of Implicit Knowledge in Texts
May 07, 2021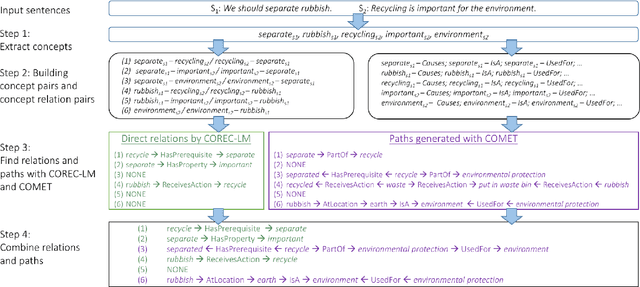
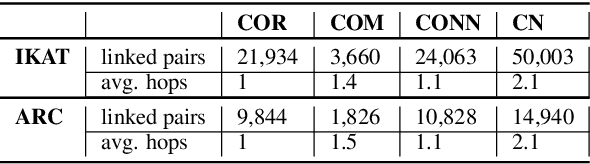

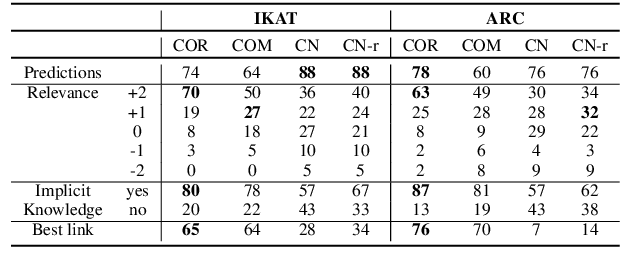
In this work we leverage commonsense knowledge in form of knowledge paths to establish connections between sentences, as a form of explicitation of implicit knowledge. Such connections can be direct (singlehop paths) or require intermediate concepts (multihop paths). To construct such paths we combine two model types in a joint framework we call Co-nnect: a relation classifier that predicts direct connections between concepts; and a target prediction model that generates target or intermediate concepts given a source concept and a relation, which we use to construct multihop paths. Unlike prior work that relies exclusively on static knowledge sources, we leverage language models finetuned on knowledge stored in ConceptNet, to dynamically generate knowledge paths, as explanations of implicit knowledge that connects sentences in texts. As a central contribution we design manual and automatic evaluation settings for assessing the quality of the generated paths. We conduct evaluations on two argumentative datasets and show that a combination of the two model types generates meaningful, high-quality knowledge paths between sentences that reveal implicit knowledge conveyed in text.
Implicit Knowledge in Argumentative Texts: An Annotated Corpus
Dec 04, 2019



When speaking or writing, people omit information that seems clear and evident, such that only part of the message is expressed in words. Especially in argumentative texts it is very common that (important) parts of the argument are implied and omitted. We hypothesize that for argument analysis it will be beneficial to reconstruct this implied information. As a starting point for filling such knowledge gaps, we build a corpus consisting of high-quality human annotations of missing and implied information in argumentative texts. To learn more about the characteristics of both the argumentative texts and the added information, we further annotate the data with semantic clause types and commonsense knowledge relations. The outcome of our work is a carefully de-signed and richly annotated dataset, for which we then provide an in-depth analysis by investigating characteristic distributions and correlations of the assigned labels. We reveal interesting patterns and intersections between the annotation categories and properties of our dataset, which enable insights into the characteristics of both argumentative texts and implicit knowledge in terms of structural features and semantic information. The results of our analysis can help to assist automated argument analysis and can guide the process of revealing implicit information in argumentative texts automatically.