 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Identification with Additive Noise Models: Quantifying the Effect of Noise
Oct 15, 2021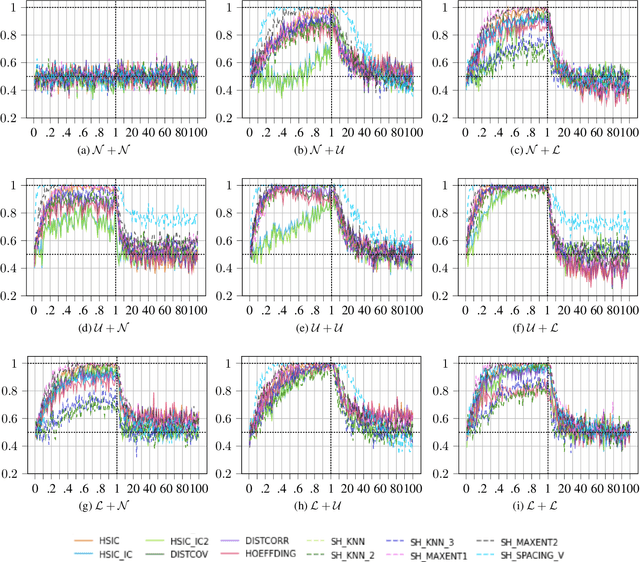


In recent years, a lot of research has been conducted within the area of causal inference and causal learning. Many methods have been developed to identify the cause-effect pairs in models and have been successfully applied to observational real-world data to determine the direction of causal relationships. Yet in bivariate situations, causal discovery problems remain challenging. One class of such methods, that also allows tackling the bivariate case, is based on Additive Noise Models (ANMs). Unfortunately, one aspect of these methods has not received much attention until now: what is the impact of different noise levels on the ability of these methods to identify the direction of the causal relationship. This work aims to bridge this gap with the help of an empirical study. We test Regression with Subsequent Independence Test (RESIT) using an exhaustive range of models where the level of additive noise gradually changes from 1\% to 10000\% of the causes' noise level (the latter remains fixed). Additionally, the experiments in this work consider several different types of distributions as well as linear and non-linear models. The results of the experiments show that ANMs methods can fail to capture the true causal direction for some levels of noise.
How Nonconformity Functions and Difficulty of Datasets Impact the Efficiency of Conformal Classifiers
Aug 12, 2021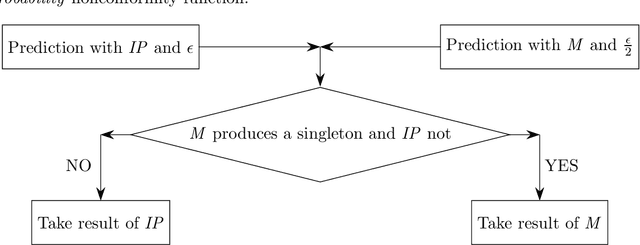

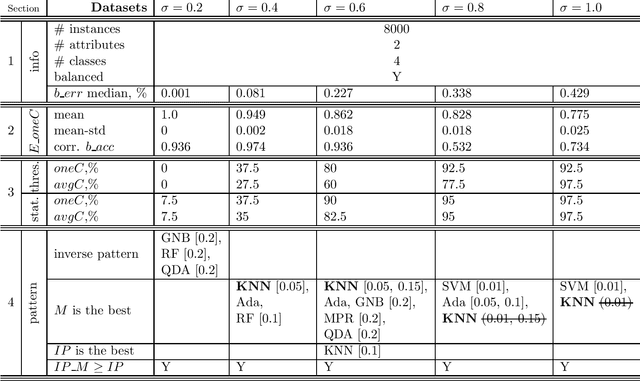
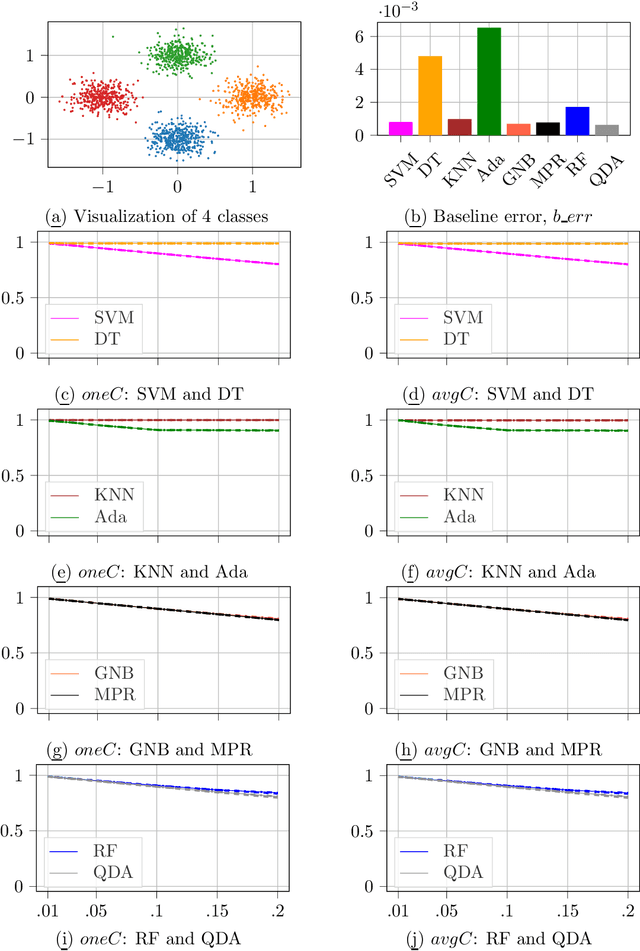
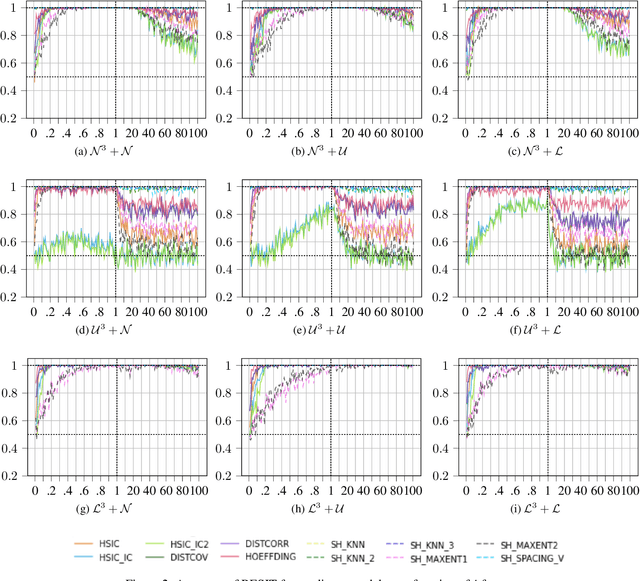
The property of conformal predictors to guarantee the required accuracy rate makes this framework attractive in various practical applications. However, this property is achieved at a price of reduction in precision. In the case of conformal classification, the systems can output multiple class labels instead of one. It is also known from the literature, that the choice of nonconformity function has a major impact on the efficiency of conformal classifiers. Recently, it was shown that different model-agnostic nonconformity functions result in conformal classifiers with different characteristics. For a Neural Network-based conformal classifier, the inverse probability (or hinge loss) allows minimizing the average number of predicted labels, and margin results in a larger fraction of singleton predictions. In this work, we aim to further extend this study. We perform an experimental evaluation using 8 different classification algorithms and discuss when the previously observed relationship holds or not. Additionally, we propose a successful method to combine the properties of these two nonconformity functions. The experimental evaluation is done using 11 real and 5 synthetic datasets.
SCR-Apriori for Mining `Sets of Contrasting Rules'
Dec 20, 2019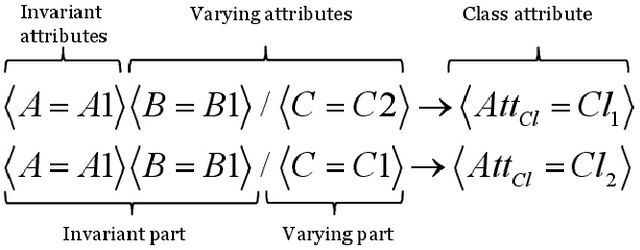
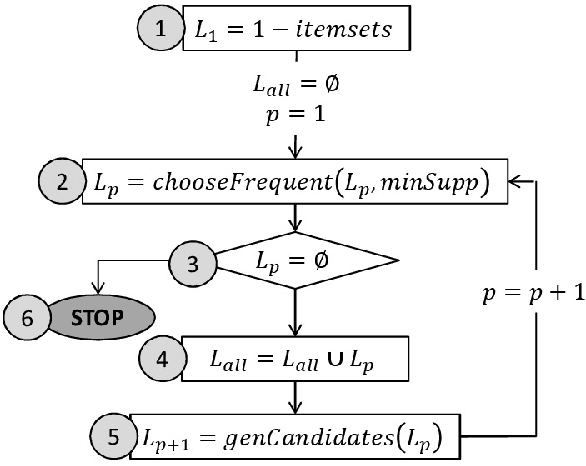
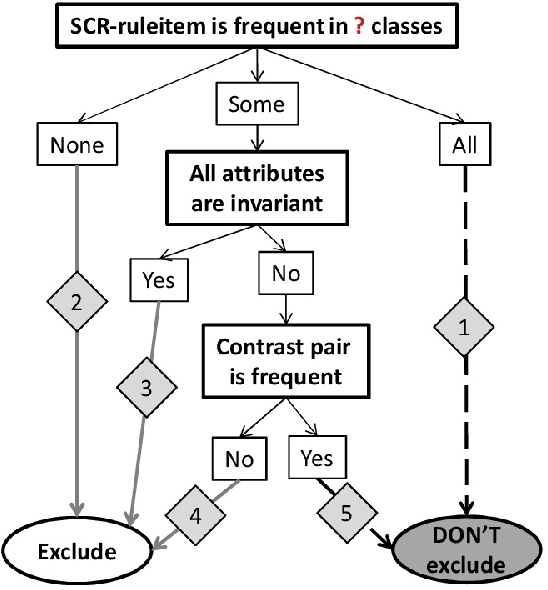
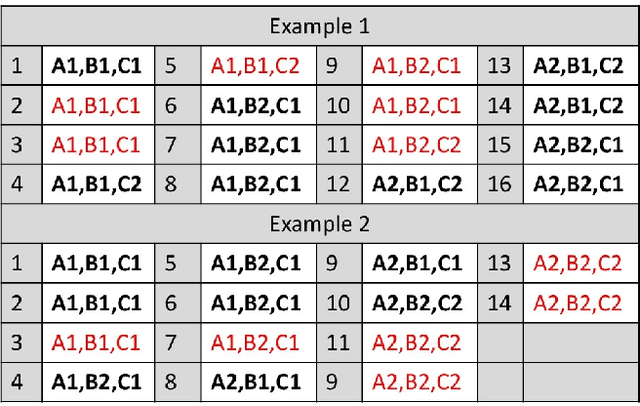
In this paper, we propose an efficient algorithm for mining novel `Set of Contrasting Rules'-pattern (SCR-pattern), which consists of several association rules. This pattern is of high interest due to the guaranteed quality of the rules forming it and its ability to discover useful knowledge. However, SCR-pattern has no efficient mining algorithm. We propose SCR-Apriori algorithm, which results in the same set of SCR-patterns as the state-of-the-art approache, but is less computationally expensive. We also show experimentally that by incorporating the knowledge about the pattern structure into Apriori algorithm, SCR-Apriori can significantly prune the search space of frequent itemsets to be analysed.