 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning in Supply-Chain Games
Jul 08, 2022We study a repeated game between a supplier and a retailer who want to maximize their respective profits without full knowledge of the problem parameters. After characterizing the uniqueness of the Stackelberg equilibrium of the stage game with complete information, we show that even with partial knowledge of the joint distribution of demand and production costs, natural learning dynamics guarantee convergence of the joint strategy profile of supplier and retailer to the Stackelberg equilibrium of the stage game. We also prove finite-time bounds on the supplier's regret and asymptotic bounds on the retailer's regret, where the specific rates depend on the type of knowledge preliminarily available to the players. In the special case when the supplier is not strategic (vertical integration), we prove optimal finite-time regret bounds on the retailer's regret (or, equivalently, the social welfare) when costs and demand are adversarially generated and the demand is censored.
Making the most of your day: online learning for optimal allocation of time
Feb 16, 2021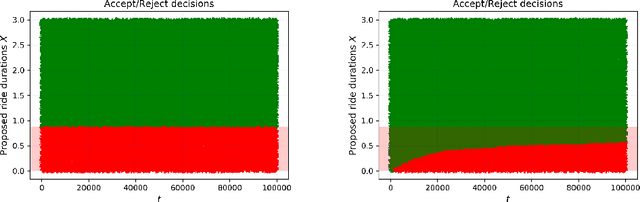
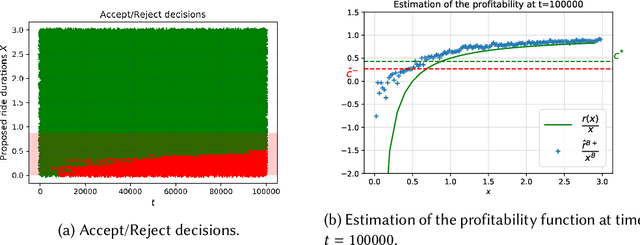
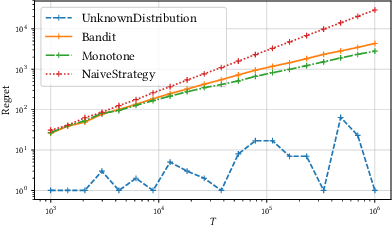
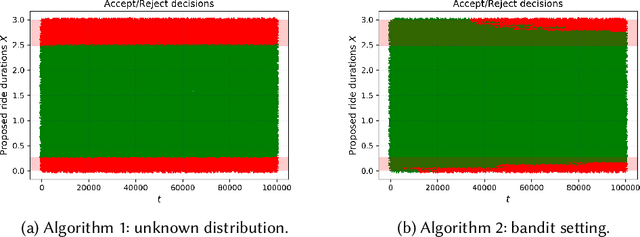
We study online learning for optimal allocation when the resource to be allocated is time. Examples of possible applications include a driver filling a day with rides, a landlord renting an estate, etc. Following our initial motivation, a driver receives ride proposals sequentially according to a Poisson process and can either accept or reject a proposed ride. If she accepts the proposal, she is busy for the duration of the ride and obtains a reward that depends on the ride duration. If she rejects it, she remains on hold until a new ride proposal arrives. We study the regret incurred by the driver first when she knows her reward function but does not know the distribution of the ride duration, and then when she does not know her reward function, either. Faster rates are finally obtained by adding structural assumptions on the distribution of rides or on the reward function. This natural setting bears similarities with contextual (one-armed) bandits, but with the crucial difference that the normalized reward associated to a context depends on the whole distribution of contexts.
Speed of Social Learning from Reviews in Non-Stationary Environments
Jul 20, 2020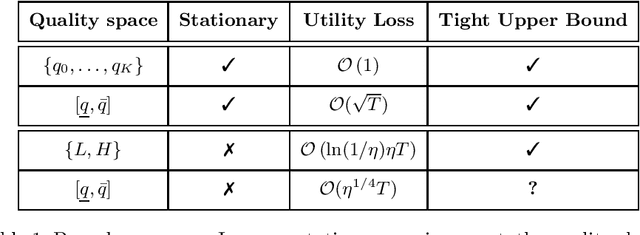
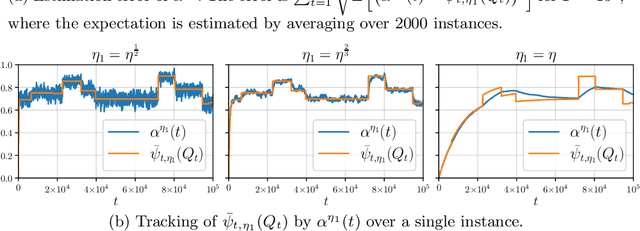
Potential buyers of a product or service tend to first browse feedback from previous consumers through review platforms. This behavior is modeled by a market of Bayesian consumers with heterogeneous preferences, who sequentially decide whether to buy an item based on reviews of previous buyers. While the belief of the item quality in simple settings is known to converge to its true value, this paper extends this result to more general cases, besides providing convergence rates. In practice, the quality of an item may change over time as new competitors can appear in the market or the product/service can undergo modifications. This paper studies such dynamics with changing points model and shows that the cost of learning remains low, when expressed in total utility earned by consumers.