 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the training of sparse and dense deep neural networks: less parameters, same performance
Jun 17, 2021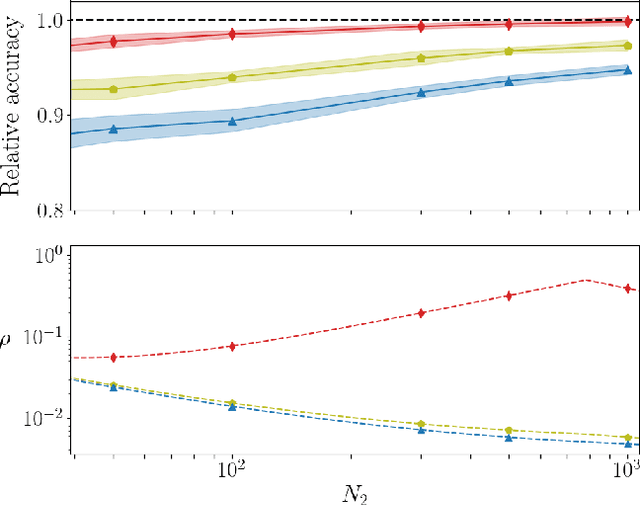
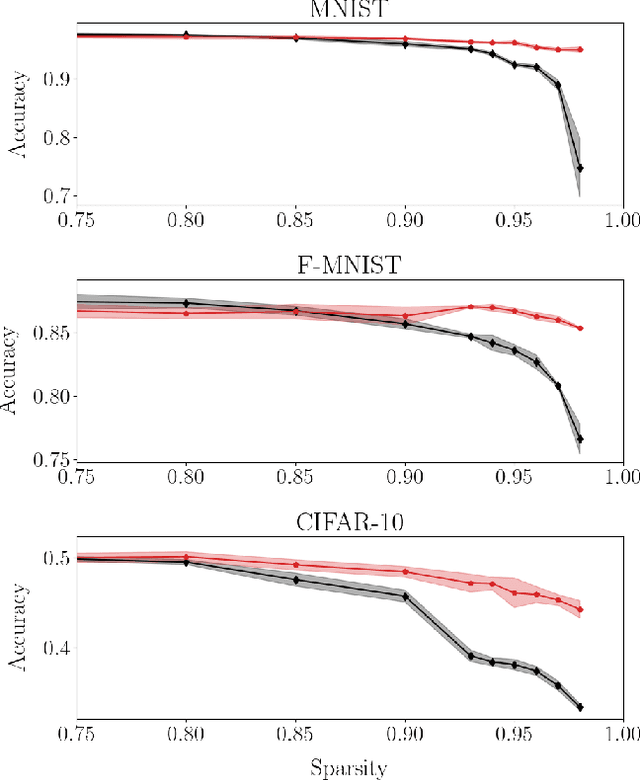
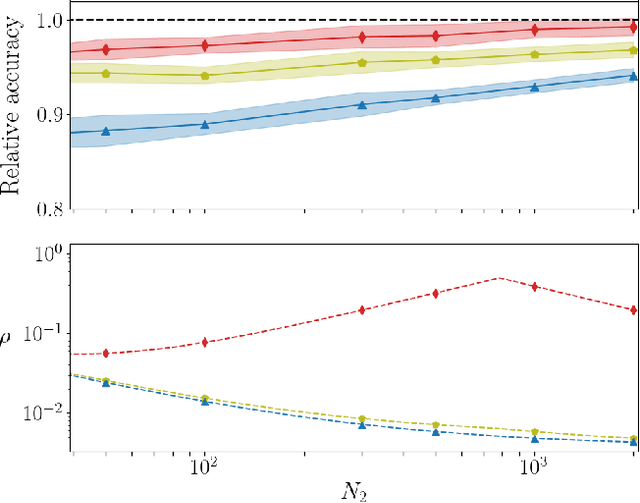
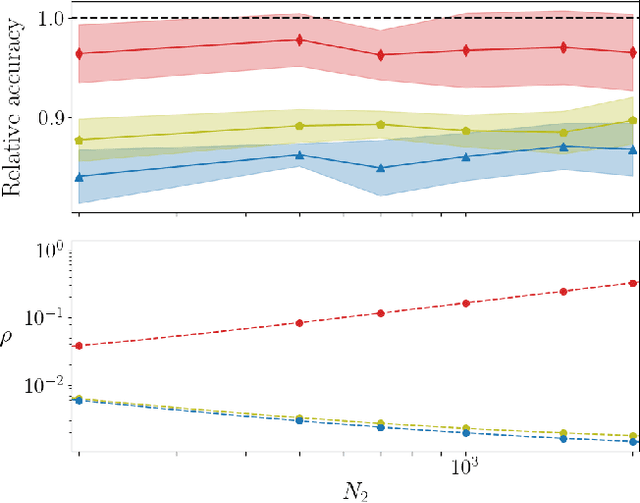
Deep neural networks can be trained in reciprocal space, by acting on the eigenvalues and eigenvectors of suitable transfer operators in direct space. Adjusting the eigenvalues, while freezing the eigenvectors, yields a substantial compression of the parameter space. This latter scales by definition with the number of computing neurons. The classification scores, as measured by the displayed accuracy, are however inferior to those attained when the learning is carried in direct space, for an identical architecture and by employing the full set of trainable parameters (with a quadratic dependence on the size of neighbor layers). In this Letter, we propose a variant of the spectral learning method as appeared in Giambagli et al {Nat. Comm.} 2021, which leverages on two sets of eigenvalues, for each mapping between adjacent layers. The eigenvalues act as veritable knobs which can be freely tuned so as to (i) enhance, or alternatively silence, the contribution of the input nodes, (ii) modulate the excitability of the receiving nodes with a mechanism which we interpret as the artificial analogue of the homeostatic plasticity. The number of trainable parameters is still a linear function of the network size, but the performances of the trained device gets much closer to those obtained via conventional algorithms, these latter requiring however a considerably heavier computational cost. The residual gap between conventional and spectral trainings can be eventually filled by employing a suitable decomposition for the non trivial block of the eigenvectors matrix. Each spectral parameter reflects back on the whole set of inter-nodes weights, an attribute which we shall effectively exploit to yield sparse networks with stunning classification abilities, as compared to their homologues trained with conventional means.