Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo (language) modeling: a baseline for generative models of natural videos
May 04, 2016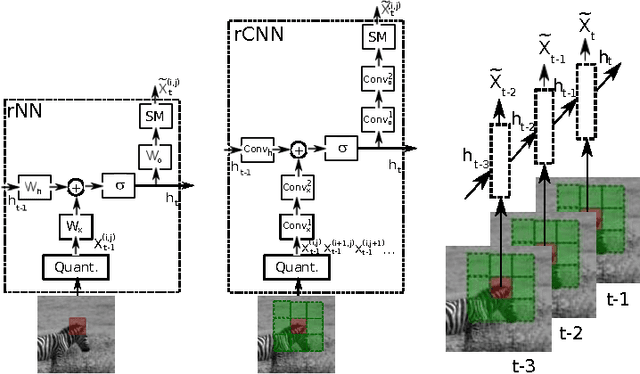



We propose a strong baseline model for unsupervised feature learning using video data. By learning to predict missing frames or extrapolate future frames from an input video sequence, the model discovers both spatial and temporal correlations which are useful to represent complex deformations and motion patterns. The models we propose are largely borrowed from the language modeling literature, and adapted to the vision domain by quantizing the space of image patches into a large dictionary. We demonstrate the approach on both a filling and a generation task. For the first time, we show that, after training on natural videos, such a model can predict non-trivial motions over short video sequences.
Via