 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceLiVT: Face Recognition using Linear Vision Transformer with Structural Reparameterization For Mobile Device
Jun 12, 2025This paper introduces FaceLiVT, a lightweight yet powerful face recognition model that integrates a hybrid Convolution Neural Network (CNN)-Transformer architecture with an innovative and lightweight Multi-Head Linear Attention (MHLA) mechanism. By combining MHLA alongside a reparameterized token mixer, FaceLiVT effectively reduces computational complexity while preserving competitive accuracy. Extensive evaluations on challenging benchmarks; including LFW, CFP-FP, AgeDB-30, IJB-B, and IJB-C; highlight its superior performance compared to state-of-the-art lightweight models. MHLA notably improves inference speed, allowing FaceLiVT to deliver high accuracy with lower latency on mobile devices. Specifically, FaceLiVT is 8.6 faster than EdgeFace, a recent hybrid CNN-Transformer model optimized for edge devices, and 21.2 faster than a pure ViT-Based model. With its balanced design, FaceLiVT offers an efficient and practical solution for real-time face recognition on resource-constrained platforms.
MicroViT: A Vision Transformer with Low Complexity Self Attention for Edge Device
Feb 09, 2025The Vision Transformer (ViT) has demonstrated state-of-the-art performance in various computer vision tasks, but its high computational demands make it impractical for edge devices with limited resources. This paper presents MicroViT, a lightweight Vision Transformer architecture optimized for edge devices by significantly reducing computational complexity while maintaining high accuracy. The core of MicroViT is the Efficient Single Head Attention (ESHA) mechanism, which utilizes group convolution to reduce feature redundancy and processes only a fraction of the channels, thus lowering the burden of the self-attention mechanism. MicroViT is designed using a multi-stage MetaFormer architecture, stacking multiple MicroViT encoders to enhance efficiency and performance. Comprehensive experiments on the ImageNet-1K and COCO datasets demonstrate that MicroViT achieves competitive accuracy while significantly improving 3.6 faster inference speed and reducing energy consumption with 40% higher efficiency than the MobileViT series, making it suitable for deployment in resource-constrained environments such as mobile and edge devices.
PGT-Net: Progressive Guided Multi-task Neural Network for Small-area Wet Fingerprint Denoising and Recognition
Aug 14, 2023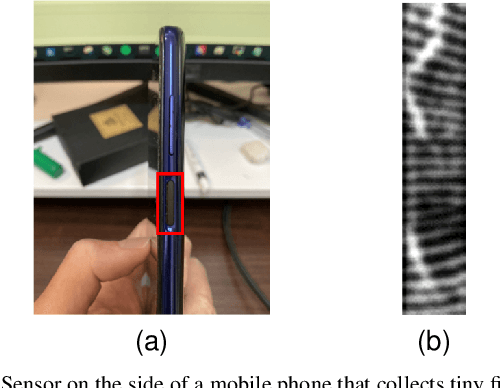

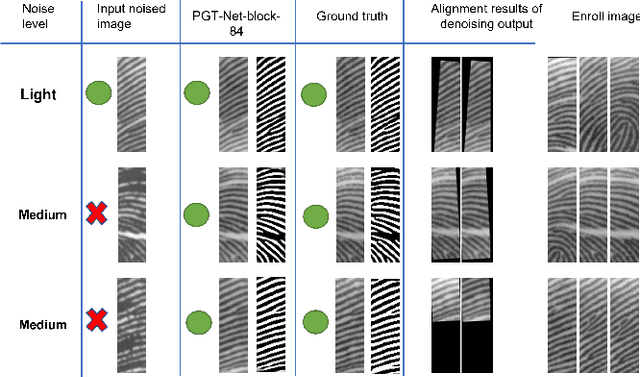

Fingerprint recognition on mobile devices is an important method for identity verification. However, real fingerprints usually contain sweat and moisture which leads to poor recognition performance. In addition, for rolling out slimmer and thinner phones, technology companies reduce the size of recognition sensors by embedding them with the power button. Therefore, the limited size of fingerprint data also increases the difficulty of recognition. Denoising the small-area wet fingerprint images to clean ones becomes crucial to improve recognition performance. In this paper, we propose an end-to-end trainable progressive guided multi-task neural network (PGT-Net). The PGT-Net includes a shared stage and specific multi-task stages, enabling the network to train binary and non-binary fingerprints sequentially. The binary information is regarded as guidance for output enhancement which is enriched with the ridge and valley details. Moreover, a novel residual scaling mechanism is introduced to stabilize the training process. Experiment results on the FW9395 and FT-lightnoised dataset provided by FocalTech shows that PGT-Net has promising performance on the wet-fingerprint denoising and significantly improves the fingerprint recognition rate (FRR). On the FT-lightnoised dataset, the FRR of fingerprint recognition can be declined from 17.75% to 4.47%. On the FW9395 dataset, the FRR of fingerprint recognition can be declined from 9.45% to 1.09%.