 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBET: Explaining Deep Reinforcement Learning through The Error-Prone Decisions
Jan 14, 2024Despite the impressive capabilities of Deep Reinforcement Learning (DRL) agents in many challenging scenarios, their black-box decision-making process significantly limits their deployment in safety-sensitive domains. Several previous self-interpretable works focus on revealing the critical states of the agent's decision. However, they cannot pinpoint the error-prone states. To address this issue, we propose a novel self-interpretable structure, named Backbone Extract Tree (BET), to better explain the agent's behavior by identify the error-prone states. At a high level, BET hypothesizes that states in which the agent consistently executes uniform decisions exhibit a reduced propensity for errors. To effectively model this phenomenon, BET expresses these states within neighborhoods, each defined by a curated set of representative states. Therefore, states positioned at a greater distance from these representative benchmarks are more prone to error. We evaluate BET in various popular RL environments and show its superiority over existing self-interpretable models in terms of explanation fidelity. Furthermore, we demonstrate a use case for providing explanations for the agents in StarCraft II, a sophisticated multi-agent cooperative game. To the best of our knowledge, we are the first to explain such a complex scenarios using a fully transparent structure.
Fidelity-Induced Interpretable Policy Extraction for Reinforcement Learning
Sep 12, 2023Deep Reinforcement Learning (DRL) has achieved remarkable success in sequential decision-making problems. However, existing DRL agents make decisions in an opaque fashion, hindering the user from establishing trust and scrutinizing weaknesses of the agents. While recent research has developed Interpretable Policy Extraction (IPE) methods for explaining how an agent takes actions, their explanations are often inconsistent with the agent's behavior and thus, frequently fail to explain. To tackle this issue, we propose a novel method, Fidelity-Induced Policy Extraction (FIPE). Specifically, we start by analyzing the optimization mechanism of existing IPE methods, elaborating on the issue of ignoring consistency while increasing cumulative rewards. We then design a fidelity-induced mechanism by integrate a fidelity measurement into the reinforcement learning feedback. We conduct experiments in the complex control environment of StarCraft II, an arena typically avoided by current IPE methods. The experiment results demonstrate that FIPE outperforms the baselines in terms of interaction performance and consistency, meanwhile easy to understand.
Content-based similar document image retrieval using fusion of CNN features
Sep 01, 2017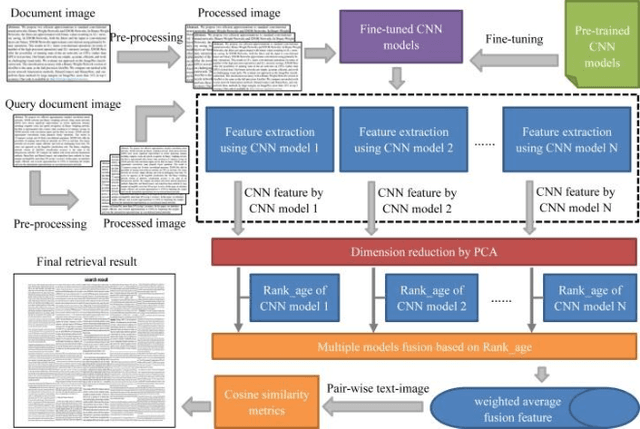
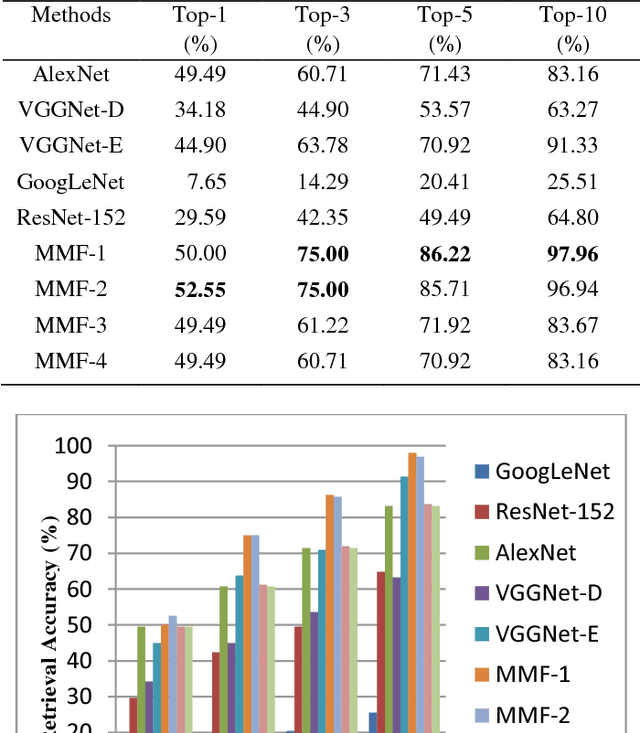


Rapid increase of digitized document give birth to high demand of document image retrieval. While conventional document image retrieval approaches depend on complex OCR-based text recognition and text similarity detection, this paper proposes a new content-based approach, in which more attention is paid to features extraction and fusion. In the proposed approach, multiple features of document images are extracted by different CNN models. After that, the extracted CNN features are reduced and fused into weighted average feature. Finally, the document images are ranked based on feature similarity to a provided query image. Experimental procedure is performed on a group of document images that transformed from academic papers, which contain both English and Chinese document, the results show that the proposed approach has good ability to retrieve document images with similar text content, and the fusion of CNN features can effectively improve the retrieval accuracy.