 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoMA: Model-based Mirror Ascent for Offline Reinforcement Learning
Jan 21, 2024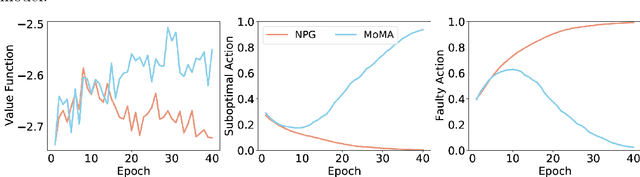
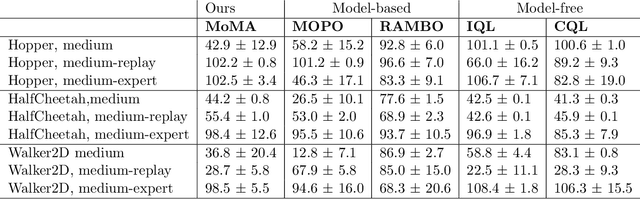
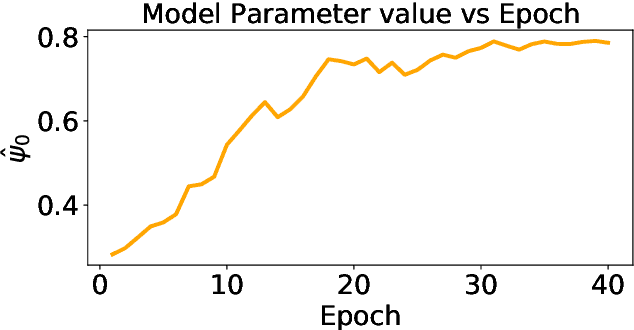

Model-based offline reinforcement learning methods (RL) have achieved state-of-the-art performance in many decision-making problems thanks to their sample efficiency and generalizability. Despite these advancements, existing model-based offline RL approaches either focus on theoretical studies without developing practical algorithms or rely on a restricted parametric policy space, thus not fully leveraging the advantages of an unrestricted policy space inherent to model-based methods. To address this limitation, we develop MoMA, a model-based mirror ascent algorithm with general function approximations under partial coverage of offline data. MoMA distinguishes itself from existing literature by employing an unrestricted policy class. In each iteration, MoMA conservatively estimates the value function by a minimization procedure within a confidence set of transition models in the policy evaluation step, then updates the policy with general function approximations instead of commonly-used parametric policy classes in the policy improvement step. Under some mild assumptions, we establish theoretical guarantees of MoMA by proving an upper bound on the suboptimality of the returned policy. We also provide a practically implementable, approximate version of the algorithm. The effectiveness of MoMA is demonstrated via numerical studies.
A Policy Gradient Method for Confounded POMDPs
May 26, 2023



In this paper, we propose a policy gradient method for confounded partially observable Markov decision processes (POMDPs) with continuous state and observation spaces in the offline setting. We first establish a novel identification result to non-parametrically estimate any history-dependent policy gradient under POMDPs using the offline data. The identification enables us to solve a sequence of conditional moment restrictions and adopt the min-max learning procedure with general function approximation for estimating the policy gradient. We then provide a finite-sample non-asymptotic bound for estimating the gradient uniformly over a pre-specified policy class in terms of the sample size, length of horizon, concentratability coefficient and the measure of ill-posedness in solving the conditional moment restrictions. Lastly, by deploying the proposed gradient estimation in the gradient ascent algorithm, we show the global convergence of the proposed algorithm in finding the history-dependent optimal policy under some technical conditions. To the best of our knowledge, this is the first work studying the policy gradient method for POMDPs under the offline setting.