 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Staged Event Tree Models via Hierarchical Clustering on the Simplex
Mar 16, 2026Staged tree models enhance Bayesian networks by incorporating context-specific dependencies through a stage-based structure. In this study, we present a new framework for estimating staged trees using hierarchical clustering on the probability simplex, utilizing simplex basesd divergences. We conduct a thorough evaluation of several distance and divergence metrics including Total Variation, Hellinger, Fisher, and Kaniadakis; alongside various linkage methods such as Ward.D2, average, complete, and McQuitty. We conducted the simulation experiments that reveals Total Variation, especially when combined with Ward.D2 linkage, consistently produces staged trees with better model fit, structure recovery, and computational efficiency. We assess performance by utilizing relative Bayesian Information Criterion (BIC), and Hamming distance. Our findings indicate that although Backward Hill Climbing (BHC) delivers competitive outcomes, it incurs a significantly higher computational cost. On the other, Total Variation divergence with Ward.D2 linkage, achieves similar performance while providing significantly better computational efficiency, making it a more viable option for large-scale or time sensitive tasks.
Modeling Psychological Profiles in Volleyball via Mixed-Type Bayesian Networks
Sep 26, 2025Psychological attributes rarely operate in isolation: coaches reason about networks of related traits. We analyze a new dataset of 164 female volleyball players from Italy's C and D leagues that combines standardized psychological profiling with background information. To learn directed relationships among mixed-type variables (ordinal questionnaire scores, categorical demographics, continuous indicators), we introduce latent MMHC, a hybrid structure learner that couples a latent Gaussian copula and a constraint-based skeleton with a constrained score-based refinement to return a single DAG. We also study a bootstrap-aggregated variant for stability. In simulations spanning sample size, sparsity, and dimension, latent Max-Min Hill-Climbing (MMHC) attains lower structural Hamming distance and higher edge recall than recent copula-based learners while maintaining high specificity. Applied to volleyball, the learned network organizes mental skills around goal setting and self-confidence, with emotional arousal linking motivation and anxiety, and locates Big-Five traits (notably neuroticism and extraversion) upstream of skill clusters. Scenario analyses quantify how improvements in specific skills propagate through the network to shift preparation, confidence, and self-esteem. The approach provides an interpretable, data-driven framework for profiling psychological traits in sport and for decision support in athlete development.
Will AI Take My Job? Evolving Perceptions of Automation and Labor Risk in Latin America
May 13, 2025As artificial intelligence and robotics increasingly reshape the global labor market, understanding public perceptions of these technologies becomes critical. We examine how these perceptions have evolved across Latin America, using survey data from the 2017, 2018, 2020, and 2023 waves of the Latinobar\'ometro. Drawing on responses from over 48,000 individuals across 16 countries, we analyze fear of job loss due to artificial intelligence and robotics. Using statistical modeling and latent class analysis, we identify key structural and ideological predictors of concern, with education level and political orientation emerging as the most consistent drivers. Our findings reveal substantial temporal and cross-country variation, with a notable peak in fear during 2018 and distinct attitudinal profiles emerging from latent segmentation. These results offer new insights into the social and structural dimensions of AI anxiety in emerging economies and contribute to a broader understanding of public attitudes toward automation beyond the Global North.
bnRep: A repository of Bayesian networks from the academic literature
Sep 27, 2024Bayesian networks (BNs) are widely used for modeling complex systems with uncertainty, yet repositories of pre-built BNs remain limited. This paper introduces bnRep, an open-source R package offering a comprehensive collection of documented BNs, facilitating benchmarking, replicability, and education. With over 200 networks from academic publications, bnRep integrates seamlessly with bnlearn and other R packages, providing users with interactive tools for network exploration.
The diameter of a stochastic matrix: A new measure for sensitivity analysis in Bayesian networks
Jul 05, 2024Bayesian networks are one of the most widely used classes of probabilistic models for risk management and decision support because of their interpretability and flexibility in including heterogeneous pieces of information. In any applied modelling, it is critical to assess how robust the inferences on certain target variables are to changes in the model. In Bayesian networks, these analyses fall under the umbrella of sensitivity analysis, which is most commonly carried out by quantifying dissimilarities using Kullback-Leibler information measures. In this paper, we argue that robustness methods based instead on the familiar total variation distance provide simple and more valuable bounds on robustness to misspecification, which are both formally justifiable and transparent. We introduce a novel measure of dependence in conditional probability tables called the diameter to derive such bounds. This measure quantifies the strength of dependence between a variable and its parents. We demonstrate how such formal robustness considerations can be embedded in building a Bayesian network.
Global Sensitivity Analysis of Uncertain Parameters in Bayesian Networks
Jun 09, 2024Traditionally, the sensitivity analysis of a Bayesian network studies the impact of individually modifying the entries of its conditional probability tables in a one-at-a-time (OAT) fashion. However, this approach fails to give a comprehensive account of each inputs' relevance, since simultaneous perturbations in two or more parameters often entail higher-order effects that cannot be captured by an OAT analysis. We propose to conduct global variance-based sensitivity analysis instead, whereby $n$ parameters are viewed as uncertain at once and their importance is assessed jointly. Our method works by encoding the uncertainties as $n$ additional variables of the network. To prevent the curse of dimensionality while adding these dimensions, we use low-rank tensor decomposition to break down the new potentials into smaller factors. Last, we apply the method of Sobol to the resulting network to obtain $n$ global sensitivity indices. Using a benchmark array of both expert-elicited and learned Bayesian networks, we demonstrate that the Sobol indices can significantly differ from the OAT indices, thus revealing the true influence of uncertain parameters and their interactions.
Learning Staged Trees from Incomplete Data
May 28, 2024



Staged trees are probabilistic graphical models capable of representing any class of non-symmetric independence via a coloring of its vertices. Several structural learning routines have been defined and implemented to learn staged trees from data, under the frequentist or Bayesian paradigm. They assume a data set has been observed fully and, in practice, observations with missing entries are either dropped or imputed before learning the model. Here, we introduce the first algorithms for staged trees that handle missingness within the learning of the model. To this end, we characterize the likelihood of staged tree models in the presence of missing data and discuss pseudo-likelihoods that approximate it. A structural expectation-maximization algorithm estimating the model directly from the full likelihood is also implemented and evaluated. A computational experiment showcases the performance of the novel learning algorithms, demonstrating that it is feasible to account for different missingness patterns when learning staged trees.
Context-Specific Refinements of Bayesian Network Classifiers
May 28, 2024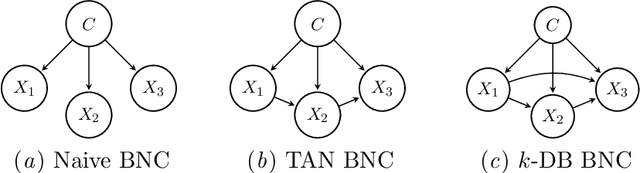

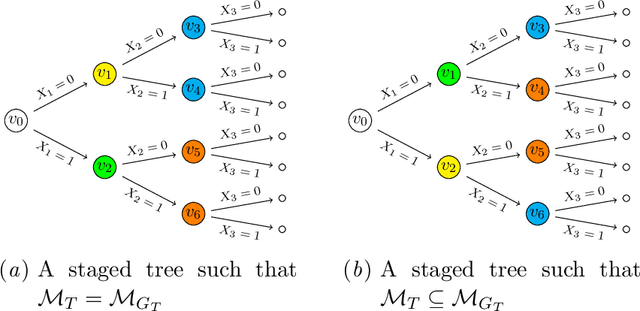
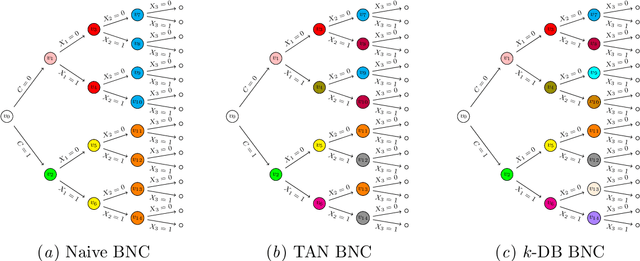
Supervised classification is one of the most ubiquitous tasks in machine learning. Generative classifiers based on Bayesian networks are often used because of their interpretability and competitive accuracy. The widely used naive and TAN classifiers are specific instances of Bayesian network classifiers with a constrained underlying graph. This paper introduces novel classes of generative classifiers extending TAN and other famous types of Bayesian network classifiers. Our approach is based on staged tree models, which extend Bayesian networks by allowing for complex, context-specific patterns of dependence. We formally study the relationship between our novel classes of classifiers and Bayesian networks. We introduce and implement data-driven learning routines for our models and investigate their accuracy in an extensive computational study. The study demonstrates that models embedding asymmetric information can enhance classification accuracy.
AI and the creative realm: A short review of current and future applications
Jun 01, 2023This study explores the concept of creativity and artificial intelligence (AI) and their recent integration. While AI has traditionally been perceived as incapable of generating new ideas or creating art, the development of more sophisticated AI models and the proliferation of human-computer interaction tools have opened up new possibilities for AI in artistic creation. This study investigates the various applications of AI in a creative context, differentiating between the type of art, language, and algorithms used. It also considers the philosophical implications of AI and creativity, questioning whether consciousness can be researched in machines and AI's potential interests and decision-making capabilities. Overall, we aim to stimulate a reflection on AI's use and ethical implications in creative contexts.
The YODO algorithm: An efficient computational framework for sensitivity analysis in Bayesian networks
Feb 01, 2023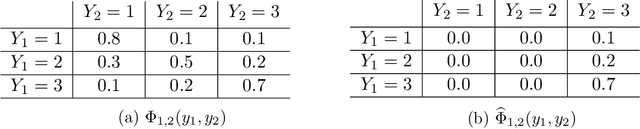
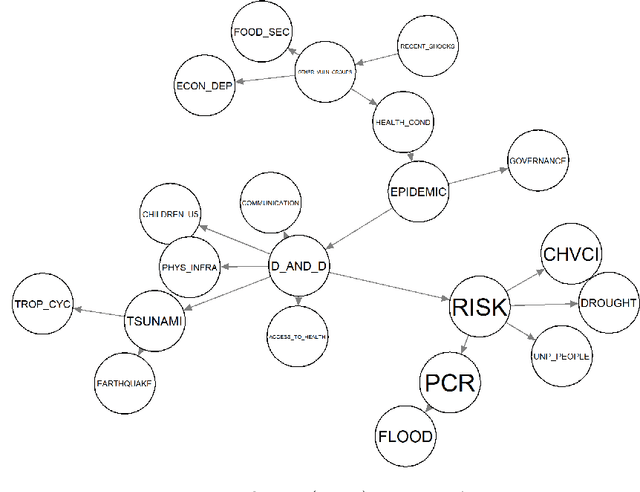
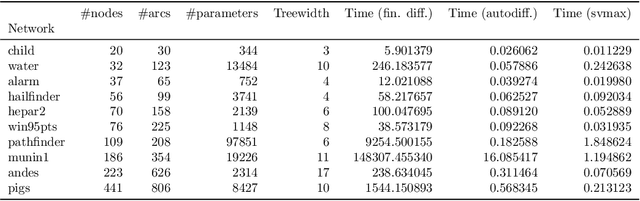
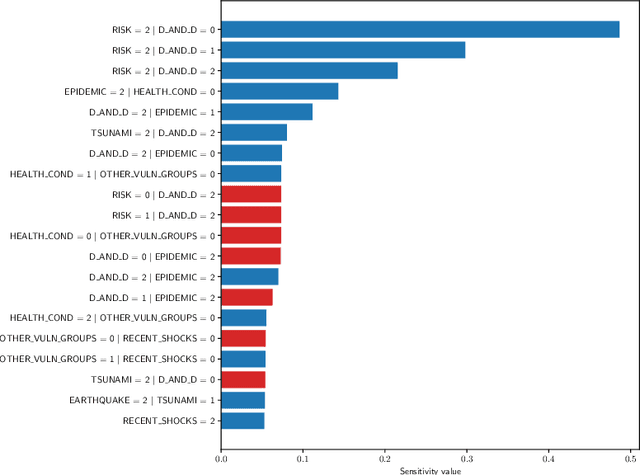
Sensitivity analysis measures the influence of a Bayesian network's parameters on a quantity of interest defined by the network, such as the probability of a variable taking a specific value. Various sensitivity measures have been defined to quantify such influence, most commonly some function of the quantity of interest's partial derivative with respect to the network's conditional probabilities. However, computing these measures in large networks with thousands of parameters can become computationally very expensive. We propose an algorithm combining automatic differentiation and exact inference to efficiently calculate the sensitivity measures in a single pass. It first marginalizes the whole network once, using e.g. variable elimination, and then backpropagates this operation to obtain the gradient with respect to all input parameters. Our method can be used for one-way and multi-way sensitivity analysis and the derivation of admissible regions. Simulation studies highlight the efficiency of our algorithm by scaling it to massive networks with up to 100'000 parameters and investigate the feasibility of generic multi-way analyses. Our routines are also showcased over two medium-sized Bayesian networks: the first modeling the country-risks of a humanitarian crisis, the second studying the relationship between the use of technology and the psychological effects of forced social isolation during the COVID-19 pandemic. An implementation of the methods using the popular machine learning library PyTorch is freely available.