 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Economic Dispatch of Power-to-Gas Systems with Deep Reinforcement Learning:Tackling the Challenge of Delayed Rewards with Long-Term Energy Storage
Jun 06, 2025Power-to-Gas (P2G) technologies gain recognition for enabling the integration of intermittent renewables, such as wind and solar, into electricity grids. However, determining the most cost-effective operation of these systems is complex due to the volatile nature of renewable energy, electricity prices, and loads. Additionally, P2G systems are less efficient in converting and storing energy compared to battery energy storage systems (BESs), and the benefits of converting electricity into gas are not immediately apparent. Deep Reinforcement Learning (DRL) has shown promise in managing the operation of energy systems amidst these uncertainties. Yet, DRL techniques face difficulties with the delayed reward characteristic of P2G system operation. Previous research has mostly focused on short-term studies that look at the energy conversion process, neglecting the long-term storage capabilities of P2G. This study presents a new method by thoroughly examining how DRL can be applied to the economic operation of P2G systems, in combination with BESs and gas turbines, over extended periods. Through three progressively more complex case studies, we assess the performance of DRL algorithms, specifically Deep Q-Networks and Proximal Policy Optimization, and introduce modifications to enhance their effectiveness. These modifications include integrating forecasts, implementing penalties on the reward function, and applying strategic cost calculations, all aimed at addressing the issue of delayed rewards. Our findings indicate that while DRL initially struggles with the complex decision-making required for P2G system operation, the adjustments we propose significantly improve its capability to devise cost-effective operation strategies, thereby unlocking the potential for long-term energy storage in P2G technologies.
Economic Battery Storage Dispatch with Deep Reinforcement Learning from Rule-Based Demonstrations
Apr 06, 2025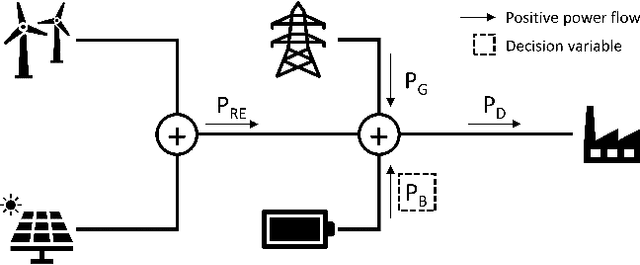

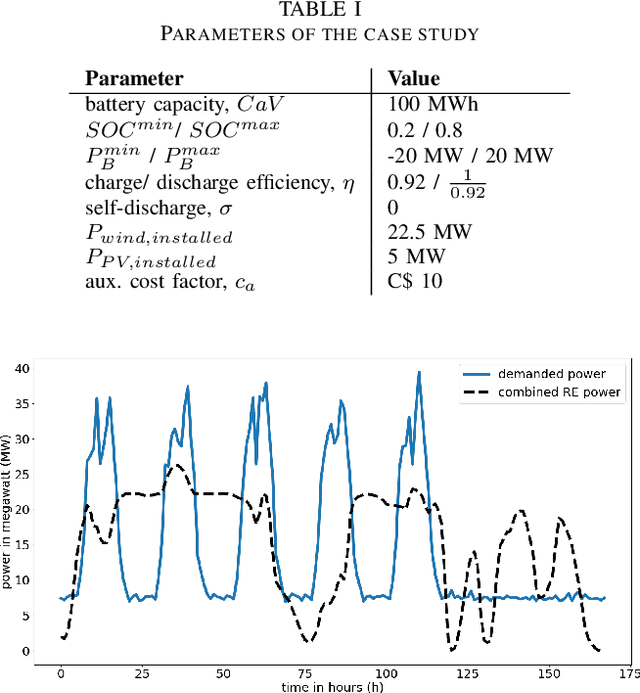
The application of deep reinforcement learning algorithms to economic battery dispatch problems has significantly increased recently. However, optimizing battery dispatch over long horizons can be challenging due to delayed rewards. In our experiments we observe poor performance of popular actor-critic algorithms when trained on yearly episodes with hourly resolution. To address this, we propose an approach extending soft actor-critic (SAC) with learning from demonstrations. The special feature of our approach is that, due to the absence of expert demonstrations, the demonstration data is generated through simple, rule-based policies. We conduct a case study on a grid-connected microgrid and use if-then-else statements based on the wholesale price of electricity to collect demonstrations. These are stored in a separate replay buffer and sampled with linearly decaying probability along with the agent's own experiences. Despite these minimal modifications and the imperfections in the demonstration data, the results show a drastic performance improvement regarding both sample efficiency and final rewards. We further show that the proposed method reliably outperforms the demonstrator and is robust to the choice of rule, as long as the rule is sufficient to guide early training into the right direction.
Enhancing Battery Storage Energy Arbitrage with Deep Reinforcement Learning and Time-Series Forecasting
Oct 25, 2024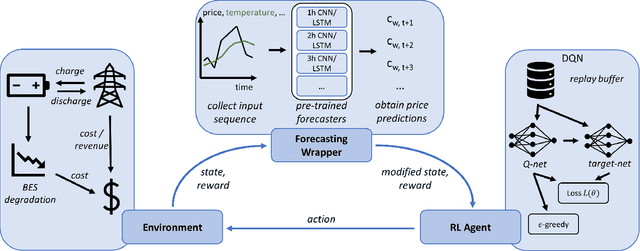
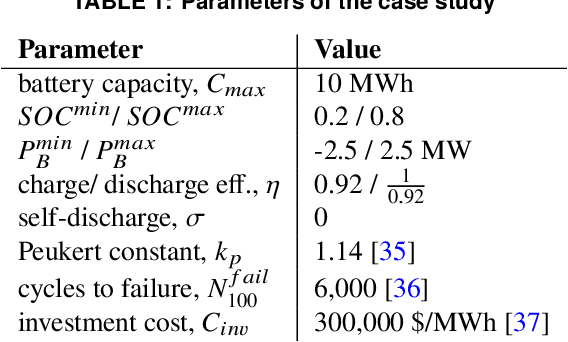

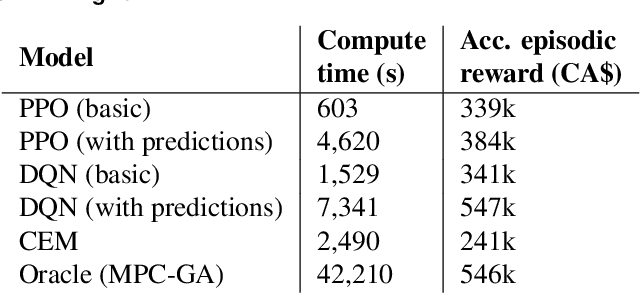
Energy arbitrage is one of the most profitable sources of income for battery operators, generating revenues by buying and selling electricity at different prices. Forecasting these revenues is challenging due to the inherent uncertainty of electricity prices. Deep reinforcement learning (DRL) emerged in recent years as a promising tool, able to cope with uncertainty by training on large quantities of historical data. However, without access to future electricity prices, DRL agents can only react to the currently observed price and not learn to plan battery dispatch. Therefore, in this study, we combine DRL with time-series forecasting methods from deep learning to enhance the performance on energy arbitrage. We conduct a case study using price data from Alberta, Canada that is characterized by irregular price spikes and highly non-stationary. This data is challenging to forecast even when state-of-the-art deep learning models consisting of convolutional layers, recurrent layers, and attention modules are deployed. Our results show that energy arbitrage with DRL-enabled battery control still significantly benefits from these imperfect predictions, but only if predictors for several horizons are combined. Grouping multiple predictions for the next 24-hour window, accumulated rewards increased by 60% for deep Q-networks (DQN) compared to the experiments without forecasts. We hypothesize that multiple predictors, despite their imperfections, convey useful information regarding the future development of electricity prices through a "majority vote" principle, enabling the DRL agent to learn more profitable control policies.
Optimal Economic Gas Turbine Dispatch with Deep Reinforcement Learning
Aug 28, 2023



Dispatching strategies for gas turbines (GTs) are changing in modern electricity grids. A growing incorporation of intermittent renewable energy requires GTs to operate more but shorter cycles and more frequently on partial loads. Deep reinforcement learning (DRL) has recently emerged as a tool that can cope with this development and dispatch GTs economically. The key advantages of DRL are a model-free optimization and the ability to handle uncertainties, such as those introduced by varying loads or renewable energy production. In this study, three popular DRL algorithms are implemented for an economic GT dispatch problem on a case study in Alberta, Canada. We highlight the benefits of DRL by incorporating an existing thermodynamic software provided by Siemens Energy into the environment model and by simulating uncertainty via varying electricity prices, loads, and ambient conditions. Among the tested algorithms and baseline methods, Deep Q-Networks (DQN) obtained the highest rewards while Proximal Policy Optimization (PPO) was the most sample efficient. We further propose and implement a method to assign GT operation and maintenance cost dynamically based on operating hours and cycles. Compared to existing methods, our approach better approximates the true cost of modern GT dispatch and hence leads to more realistic policies.